

Ep #27: Mastering Memcached Part 1: A Comprehensive Guide to High-Performance Distributed Caching
Part 1: Exploring the Core Components and Architecture of the High-Performance Caching System

Ep #26: Breaking the complex System Design Components – Free Post
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Aug 19, 2025 · Free Post ·
Introduction to Caching and Memcached - Why Caching Matters in Modern Systems
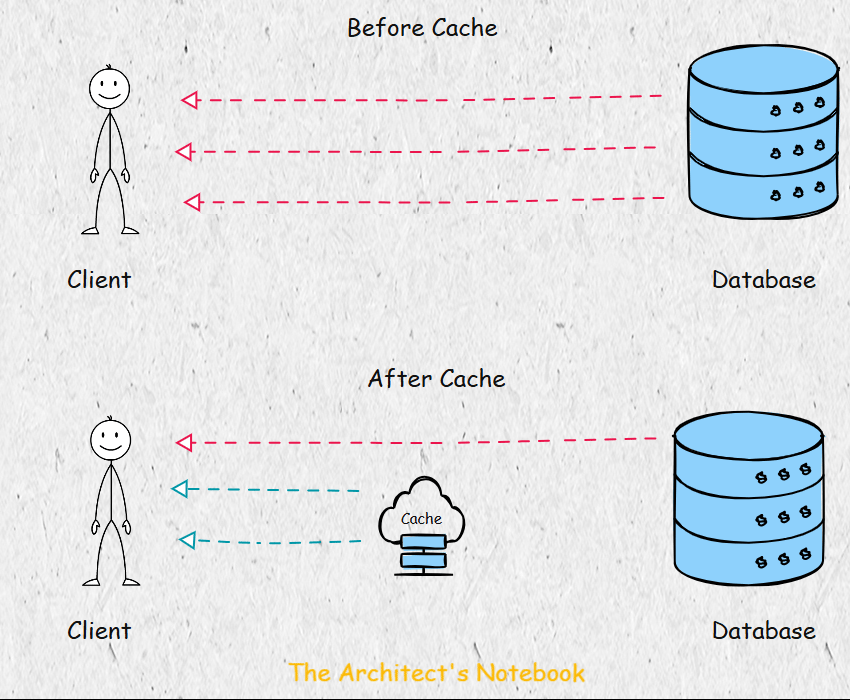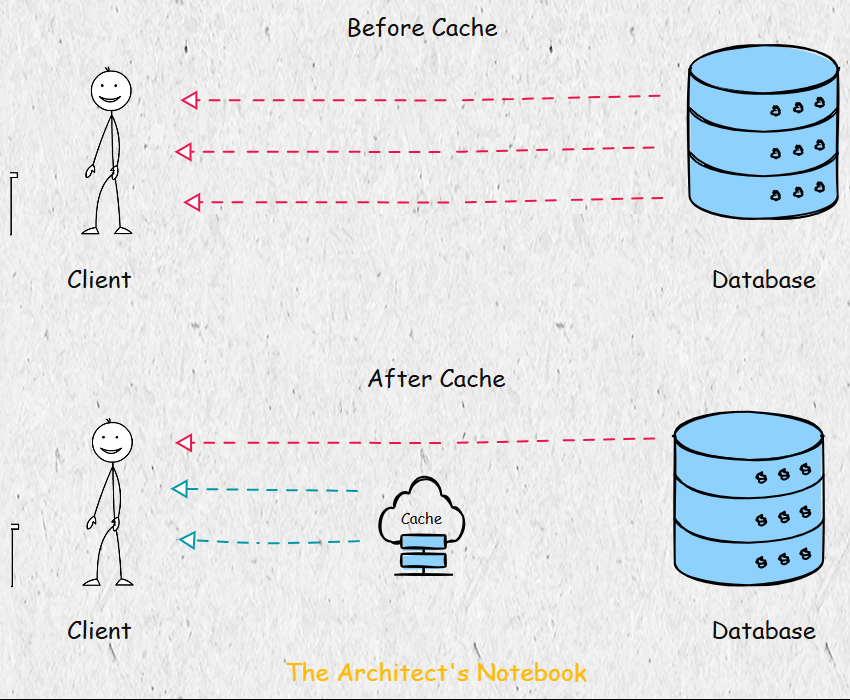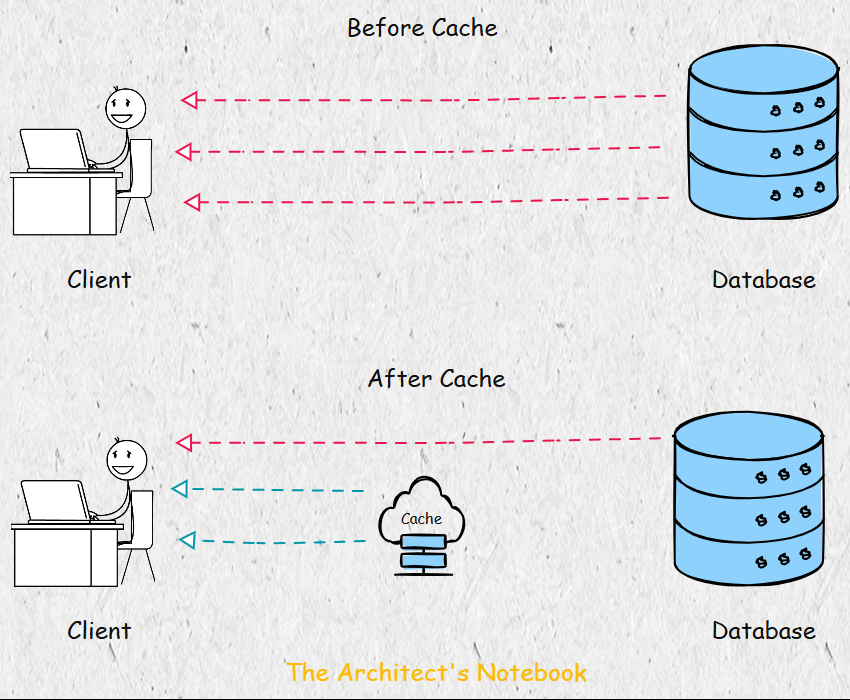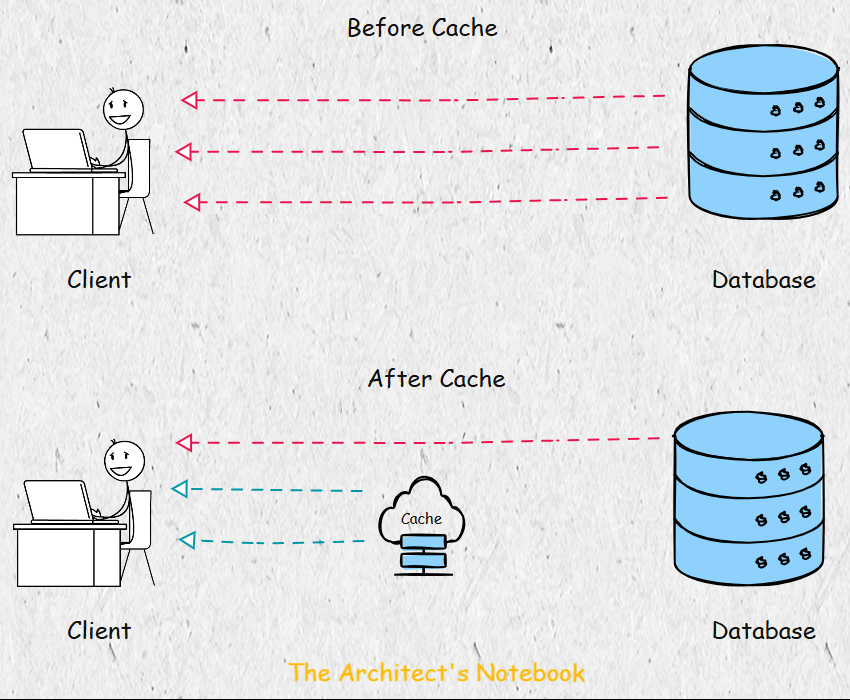
Caching is a fundamental technique in computer science that involves storing frequently accessed data in a faster, more accessible location to reduce the time and resources needed to retrieve that data. In modern web applications, caching serves as a critical performance optimization strategy that bridges the gap between fast application logic and slower persistent storage systems.
The primary purpose of caching is to improve application performance by reducing latency1, decreasing database load, and enhancing overall system scalability. When data is cached, subsequent requests for the same information can be served from the cache rather than executing expensive database queries or complex computations.
Caching requirements can arise at various system layers:
Web Application Layer: To cache session objects2.
Service Layer: To store objects created after expensive computations or database queries.
Caching is most effective for data that is frequently accessed and does not change often, ensuring the cached data remains valid and avoids staleness.
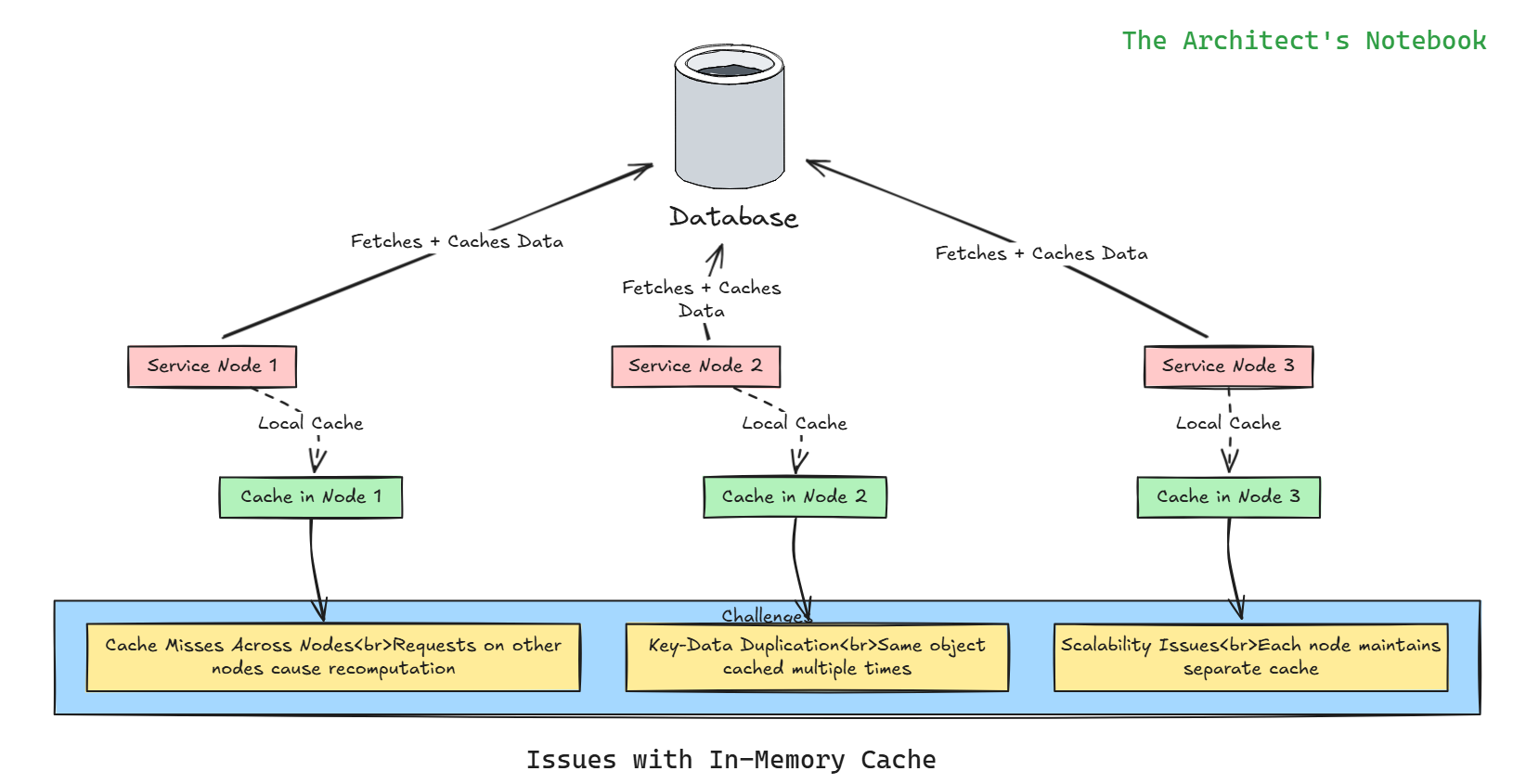
Challenges with In-Memory Caching - The Pitfalls of Local Caches in Distributed Systems
A naive approach to caching is to store data in the memory of individual service nodes. For example, if a node computes an object by fetching data from a database, it might cache it locally for future requests. However, this approach has significant limitations in a distributed system with multiple nodes:
Cache Misses Across Nodes: If a request for the same data lands on a different node, the object must be recomputed, as the cache is not shared.
Key-Data Duplication: The same key-value pair may be stored redundantly across multiple nodes, wasting memory.
Scalability Issues: Local caching does not scale well, as each node maintains its own cache, leading to inefficiencies.
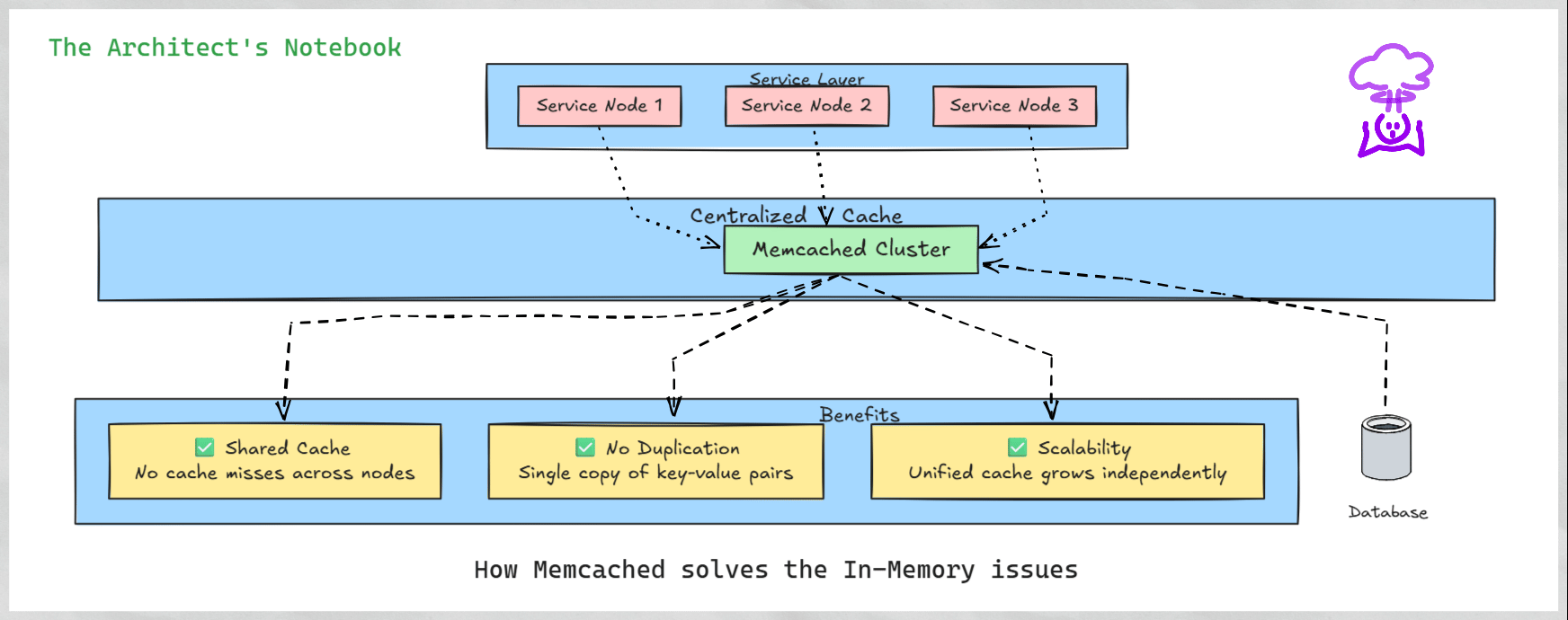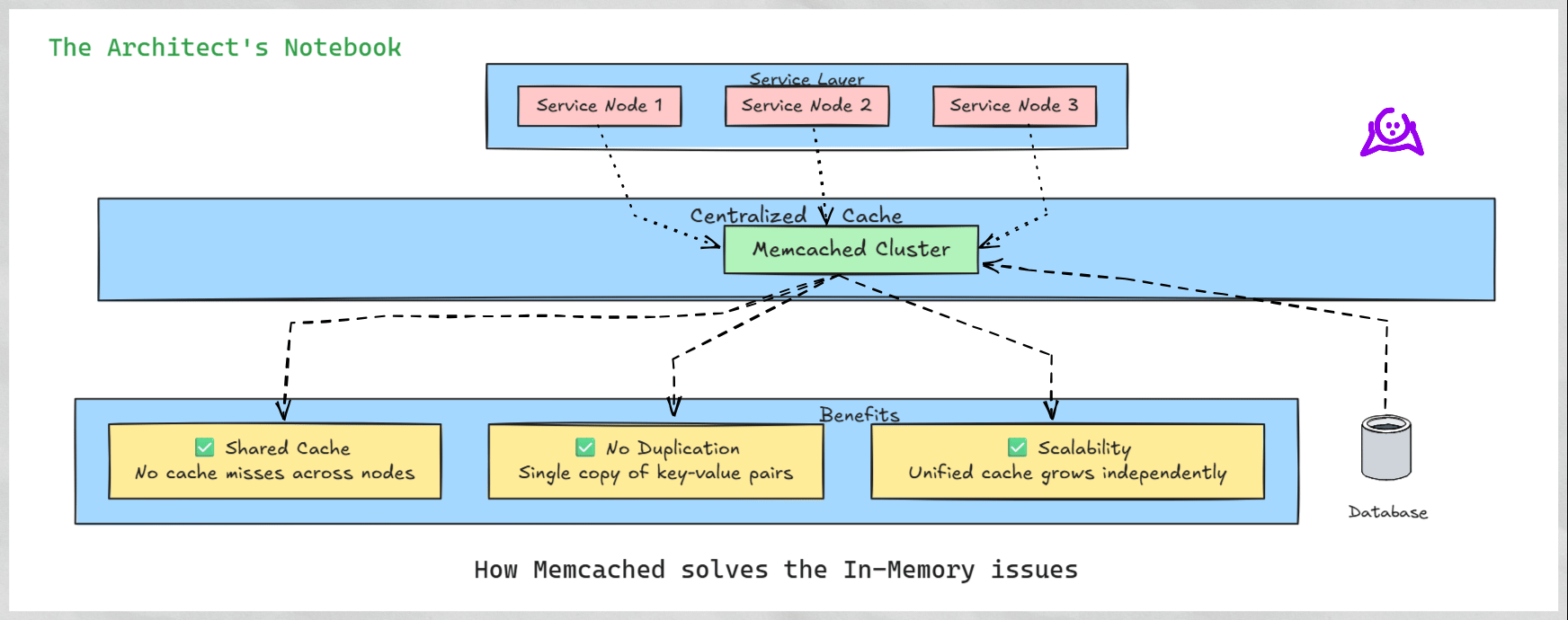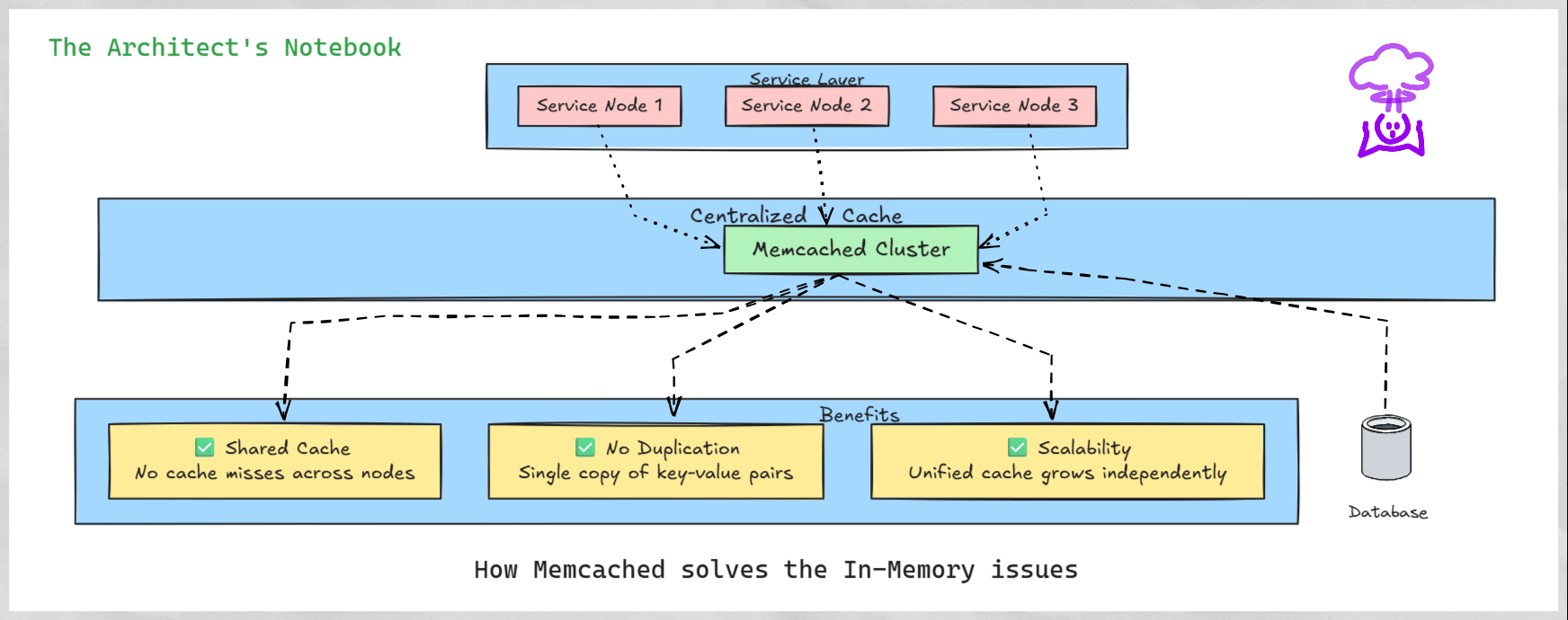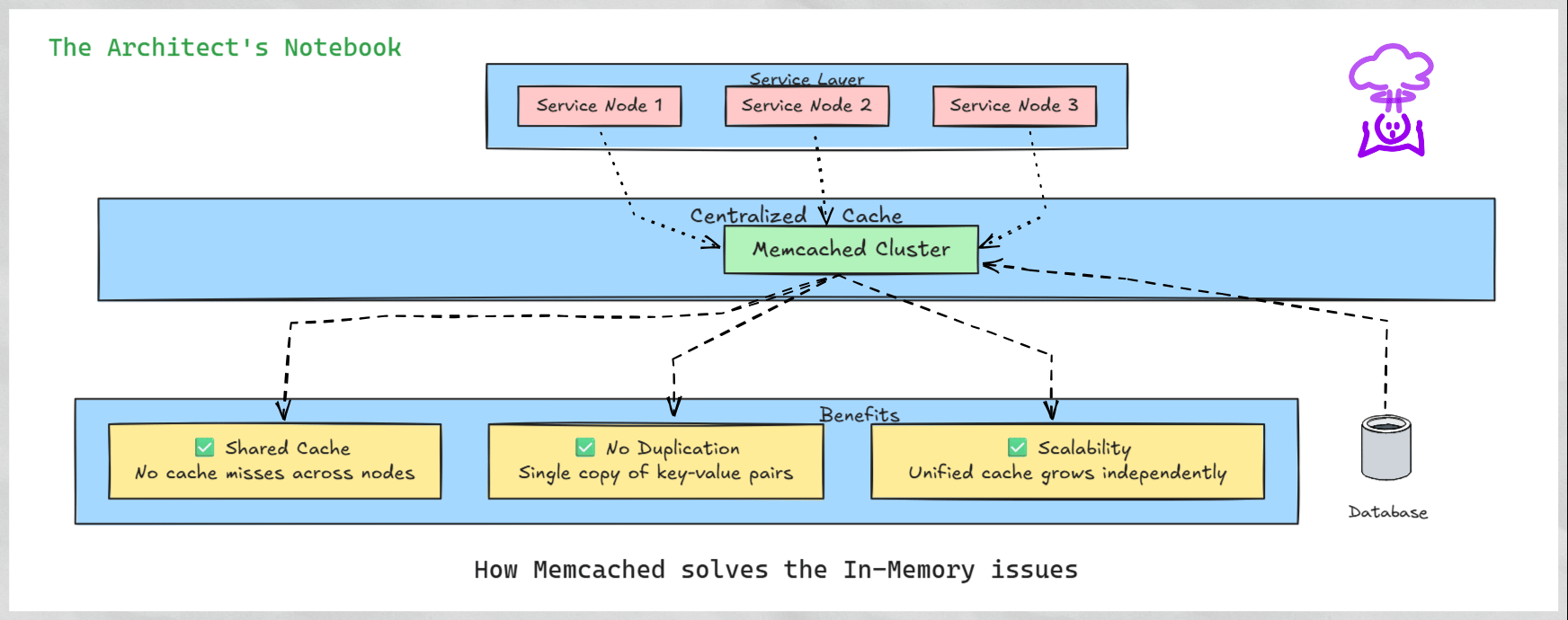
How Memcached Solves These Problems - A Centralized Approach to Caching
Memcached addresses these issues by providing a centralized caching system. Instead of each node maintaining its own cache, all nodes connect to a shared Memcached cluster, treating it as a unified cache. This approach eliminates duplication and ensures consistent access to cached data across the system.
What is Memcached?
Memcached is a high-performance, distributed memory object caching system designed to speed up dynamic web applications by reducing database load.
At its core, Memcached is a simple key-value store that operates entirely in memory, providing extremely fast read and write operations. It follows a distributed architecture where multiple Memcached instances can work together to form a cache cluster3, allowing applications to scale their caching capacity horizontally.
Why Memcached is Used
Performance Enhancement
Memcached dramatically reduces response times by serving data from memory rather than disk-based storage. Memory access is orders of magnitude faster than database queries, making it ideal for frequently accessed data.
Database Load Reduction
By caching query results and computed data, Memcached significantly reduces the load on backend databases. This allows databases to handle more concurrent connections and improves overall system stability.
Scalability
Memcached's distributed nature allows organizations to scale their caching layer independently of their application and database tiers. Adding more Memcached nodes increases cache capacity linearly.
Cost Efficiency
Reducing database queries translates to lower infrastructure costs, as fewer database resources are needed to handle the same load. Memory is relatively inexpensive compared to database server resources.
Simple Integration
Memcached's straightforward API and protocol make it easy to integrate into existing applications with minimal code changes.
Key Features of Memcached
Key-Value Storage:
Memcached stores data as key-value pairs, where values are stored as blobs4. It is agnostic to the data type, allowing storage of strings, objects, or any serialized data.
While there is no strict size limit (previously 1 MB, now configurable), large objects should be avoided to maximize the number of keys stored and maintain high cache hit rates.
Time-to-Live (TTL):
Each key-value pair can have a TTL, specifying how long the data remains valid in the cache. This helps manage data staleness.
Memory Management:
LRU Eviction: Automatically removes least recently used items when memory is full
Configurable Memory Limits: Allows fine-tuning of memory usage per instance
Slab Allocation: Efficient memory allocation system that reduces fragmentation
High Performance:
In-Memory Storage: All data resides in RAM, providing sub-millisecond access times
Efficient Protocol: Uses a simple text-based protocol that minimizes overhead
Optimized Data Structures: Employs hash tables5 for O(1) key lookup performance
Distributed Architecture
Horizontal Scaling: Supports multiple nodes in a cluster
Client-Side Sharding6: Uses consistent hashing to distribute keys across nodes
No Single Point of Failure: Designed to continue operating even if individual nodes fail
Multi-Platform Support
Cross-Platform: Runs on Linux, Windows, macOS, and other Unix-like systems
Multiple Client Libraries: Available for virtually every programming language
🚀 Special Offer Reminder:
Join the Yearly/Lifetime Premium Tier by September 5 and receive a free copy of The Architect’s Mindset - A Psychological Guide to Technical Leadership📘, valued at $22! Or better yet, consider it an invaluable resource on your journey to systems leadership to elevate your thinking and skills! ✨
In the meantime, feel free to check out the free sample right here! 👀
Don’t miss out on this exclusive bonus 🎁. Upgrade now and unlock premium content plus this valuable resource! 🔥
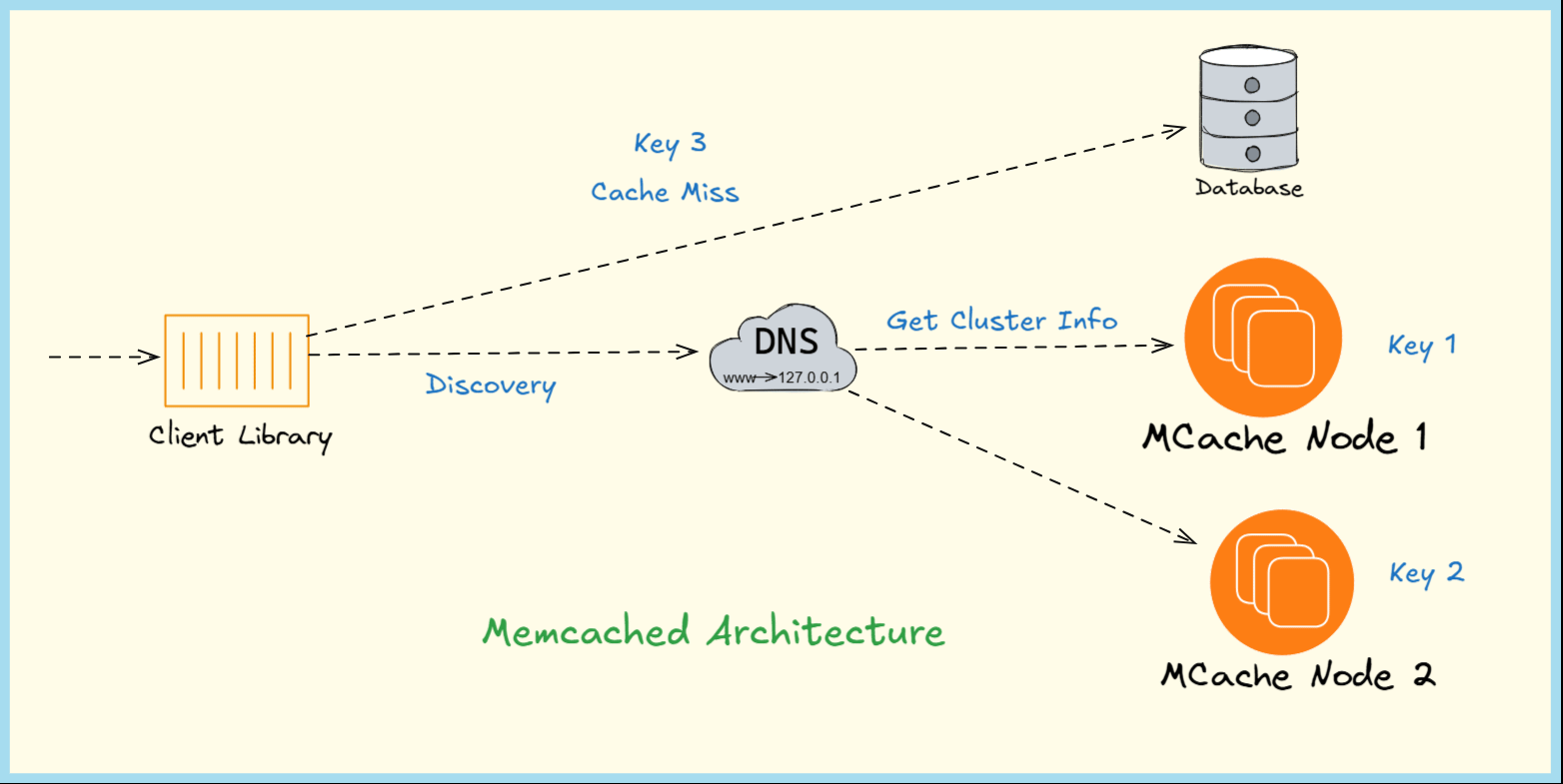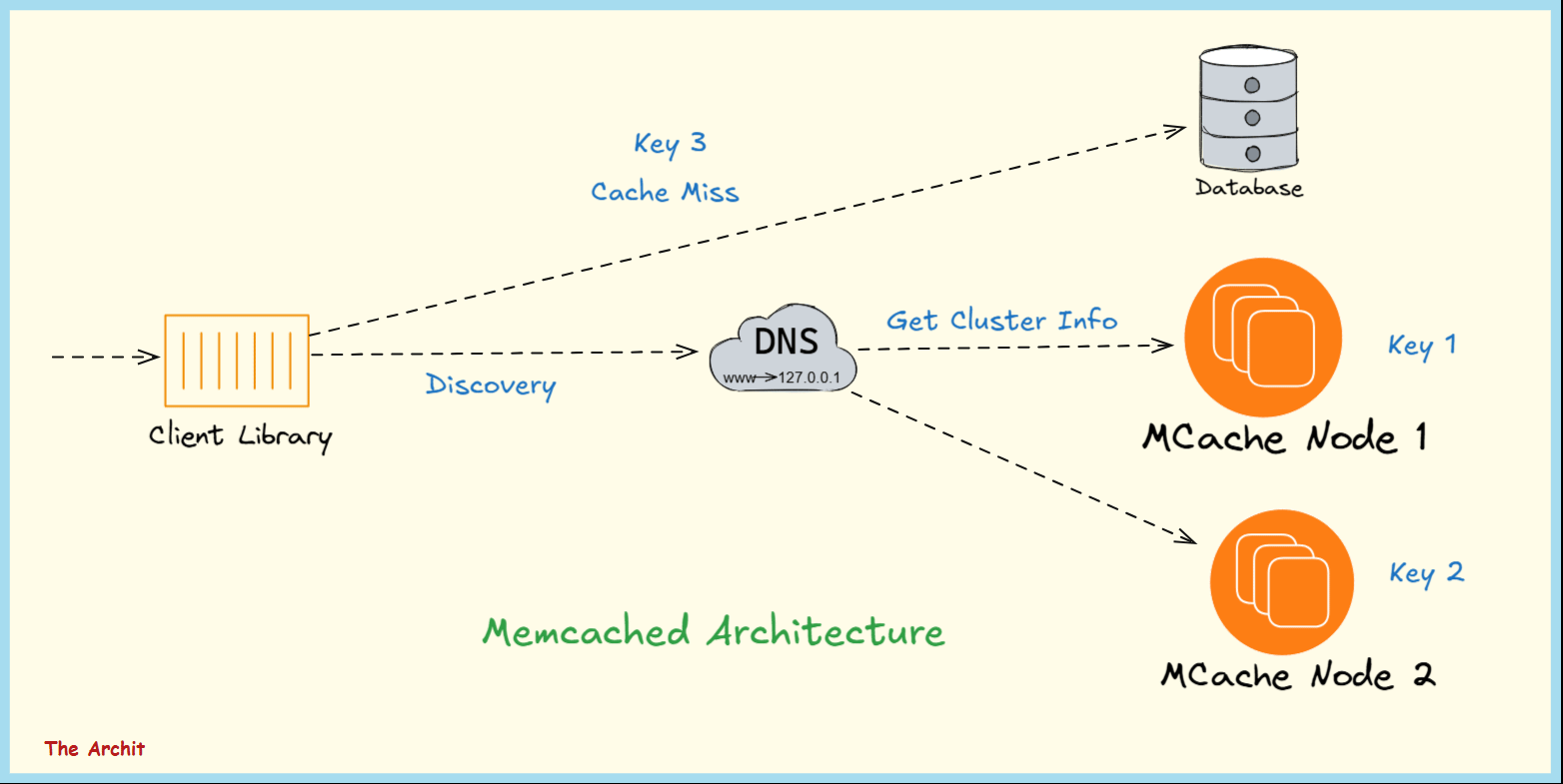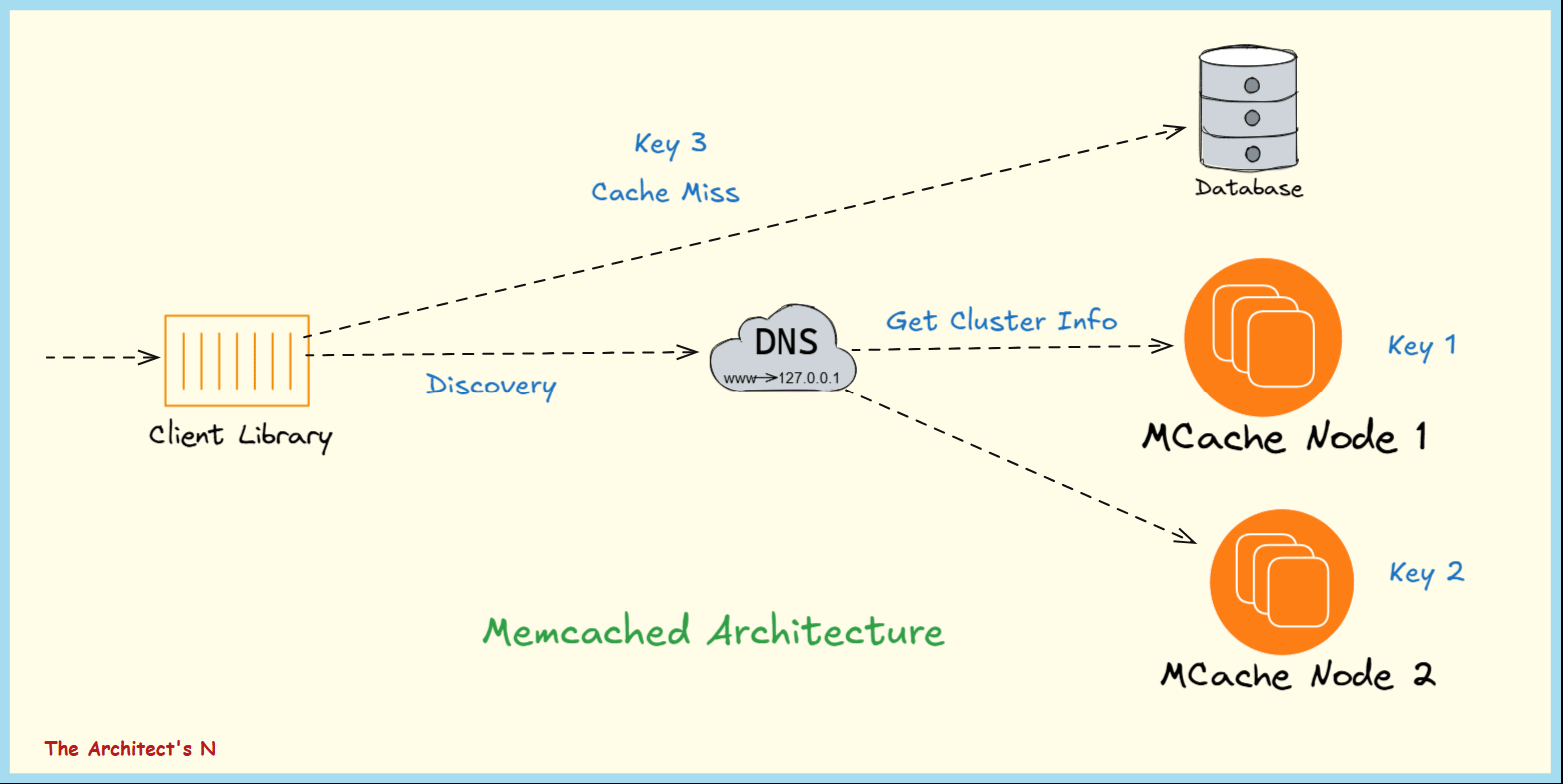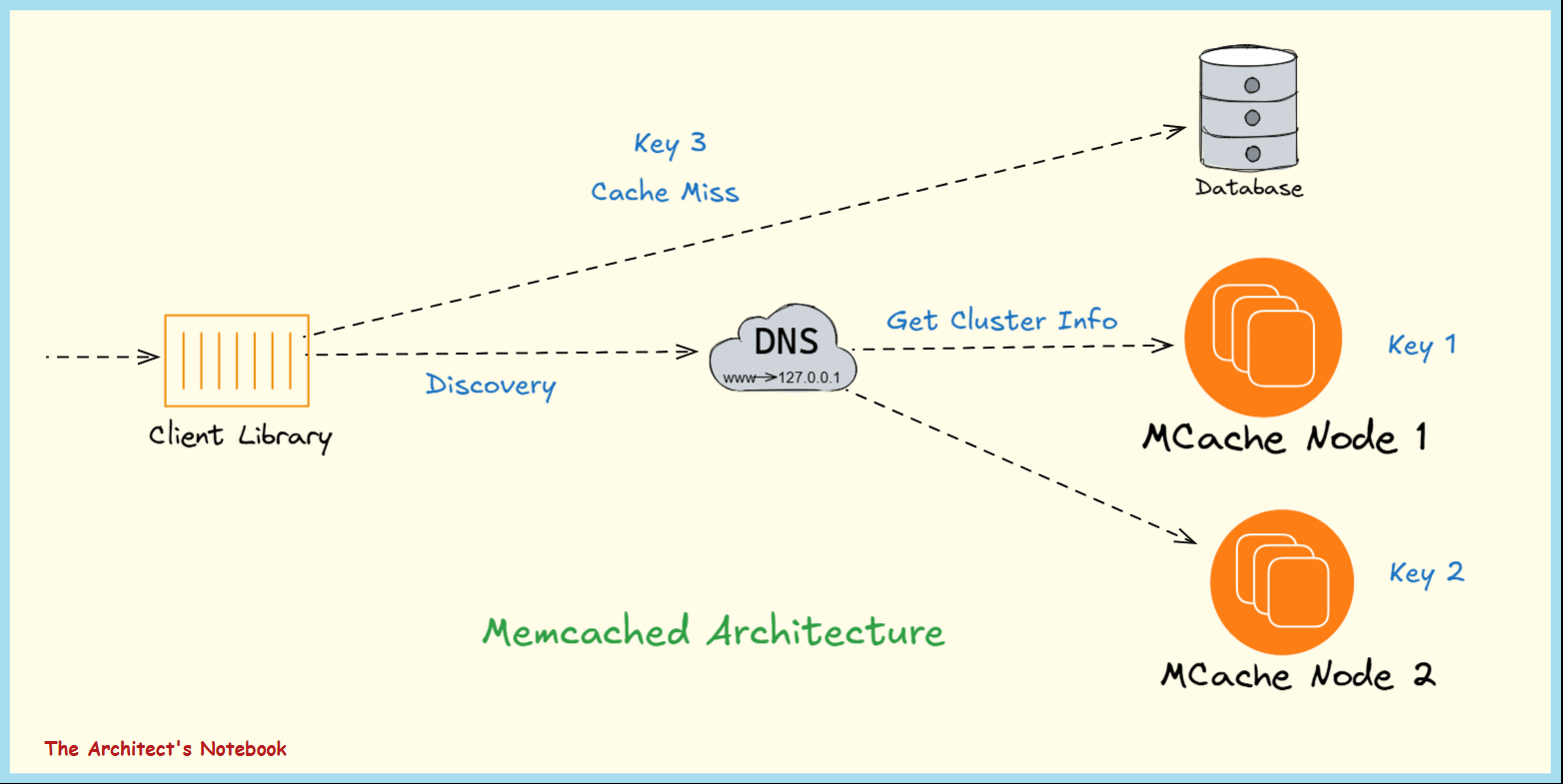
Memcached Architecture - The Building Blocks of Memcached
Memcached operates as a cluster of nodes, each with a unique identifier and IP address. The number of nodes can be scaled based on storage needs, making it horizontally scalable.
1. Core Components
Memcached’s architecture is built around simplicity and performance, with three primary components: the Memcached server, client libraries, and consistent hashing for key distribution.
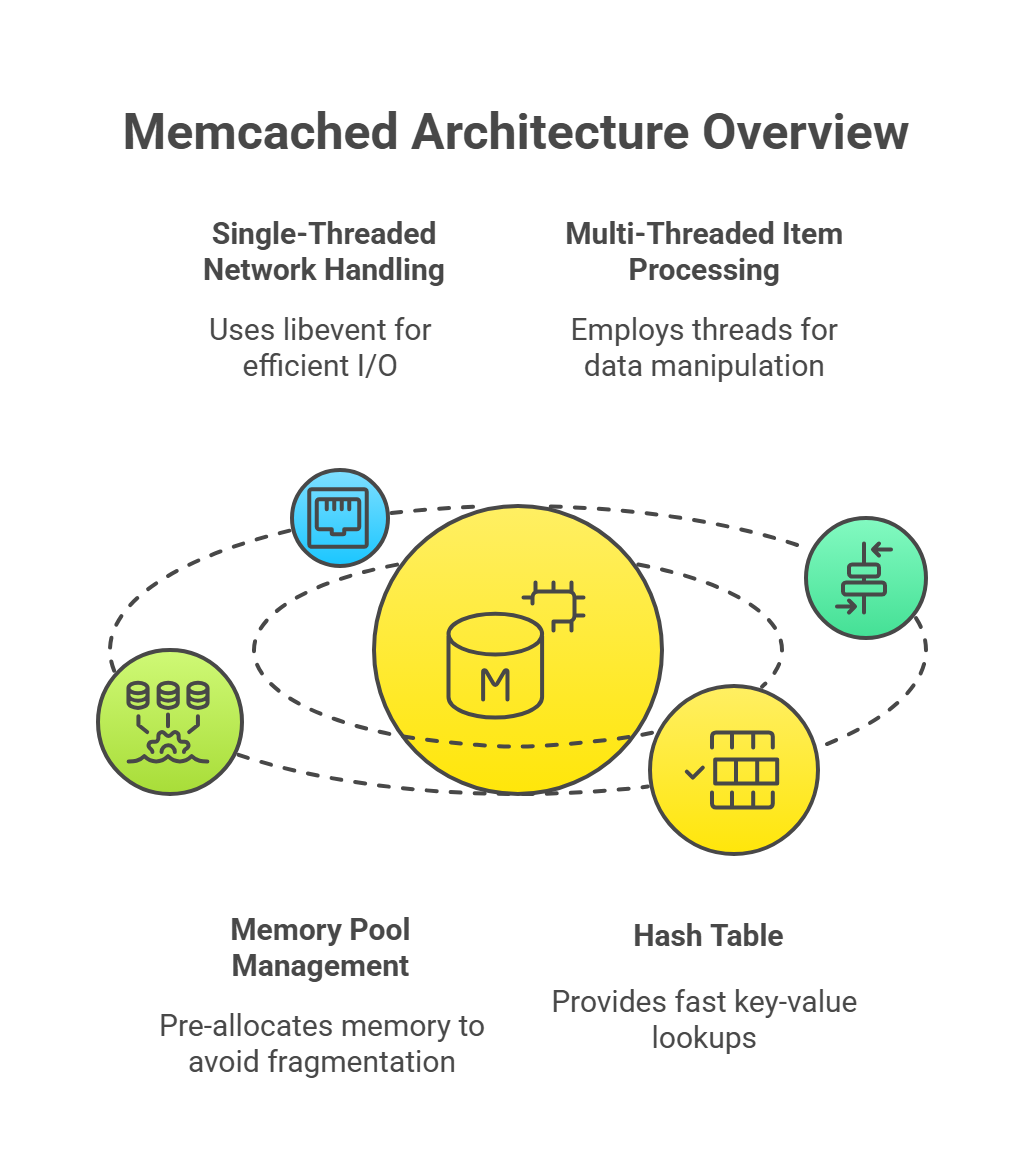
1.1 Memcached Server
The Memcached server is a lightweight daemon process that runs independently on each machine, managing its own memory space for caching data. Its key characteristics include:
Single-Threaded Network Handling:
The server uses the libevent7 library for event-driven, non-blocking I/O operations. This allows it to handle thousands of concurrent connections efficiently without creating a thread per connection, reducing overhead and improving scalability. Libevent monitors network sockets for events (e.g., new connections, data arrivals) and processes them asynchronously.Multi-Threaded Item Processing:
While network I/O is single-threaded, Memcached employs multiple threads for internal operations like item manipulation (e.g., storing, retrieving, or updating cached data). This separation ensures that network handling doesn’t block data processing, optimizing throughput. For example, one thread might handle incoming requests while others manage the in-memory data structures.Memory Pool Management:
Memcached pre-allocates memory in fixed-size chunks called slabs to avoid fragmentation, a common issue in dynamic memory allocation. Each slab is dedicated to storing items of a specific size range, ensuring efficient memory use.Hash Table:
The server maintains an in-memory hash table for fast key-value lookups. When a client sends a key, the server hashes it to locate the corresponding value in O(1) average time complexity. The hash table maps keys to memory locations within the appropriate slab, enabling rapid data retrieval.
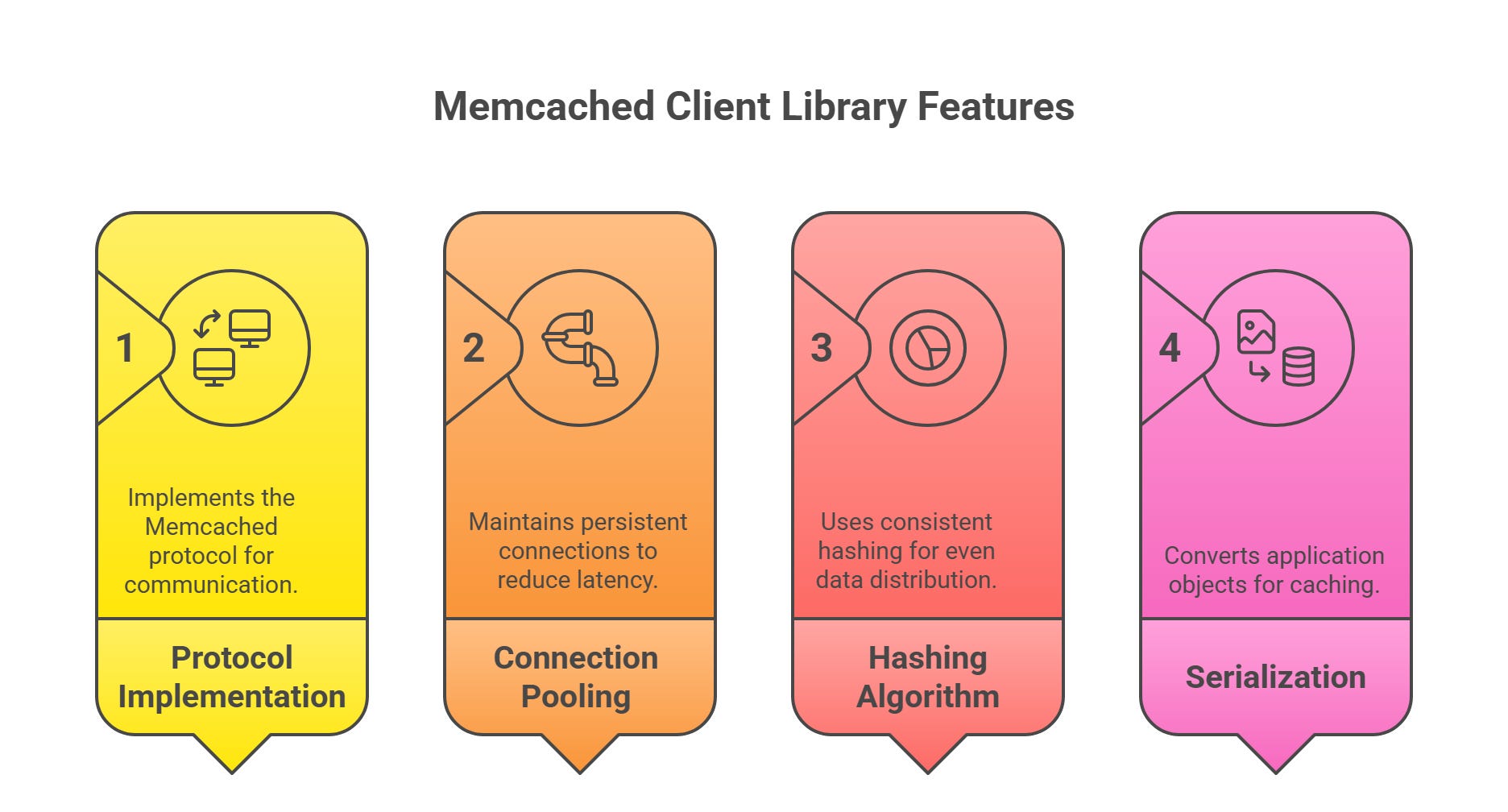
1.2 Client Library
The client library is responsible for communicating with Memcached servers and handling the logic for distributing data across a cluster. It abstracts the complexity of the Memcached protocol and server interactions from the application. Key features include:
Protocol Implementation:
The client library implements the Memcached protocol8 (ASCII or binary, though ASCII is more common) to send commands (e.g., set, get, delete) to servers and parse their responses. This ensures seamless communication between the application and the cache.Connection Pooling:
To avoid the overhead of establishing new connections for every request, the client library maintains a pool of persistent9 connections to each Memcached server. This reduces latency and improves performance, especially in high-traffic environments.Hashing Algorithm:
The client library implements consistent hashing (described below) to determine which server should store or retrieve a given key. This ensures even data distribution and minimizes disruption when the server topology changes.Serialization:
The client library converts application objects (e.g., strings, JSON, or complex data structures) into a format suitable for caching (typically byte arrays) and vice versa. This serialization/deserialization process is critical for ensuring data compatibility between the application and Memcached.
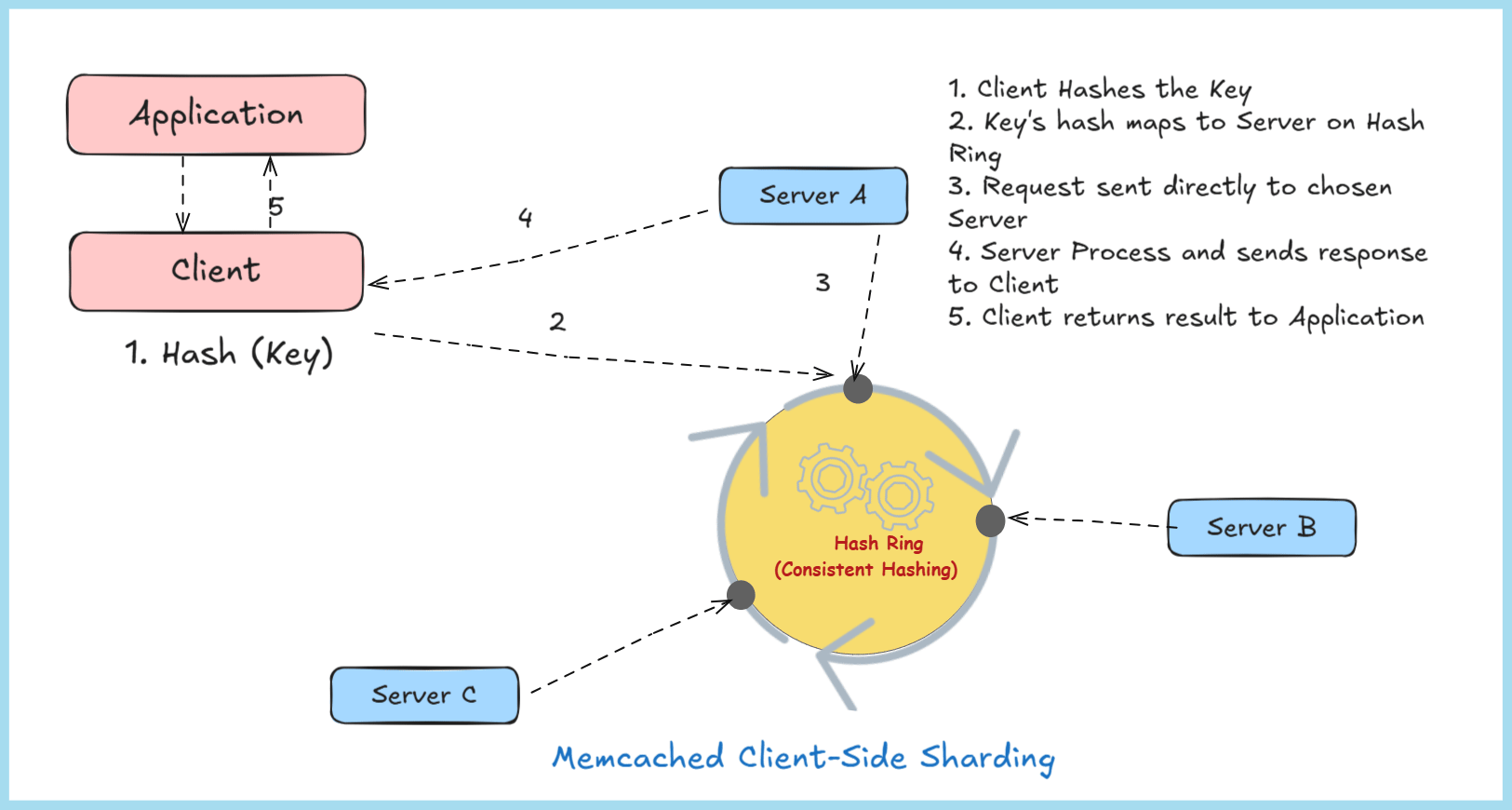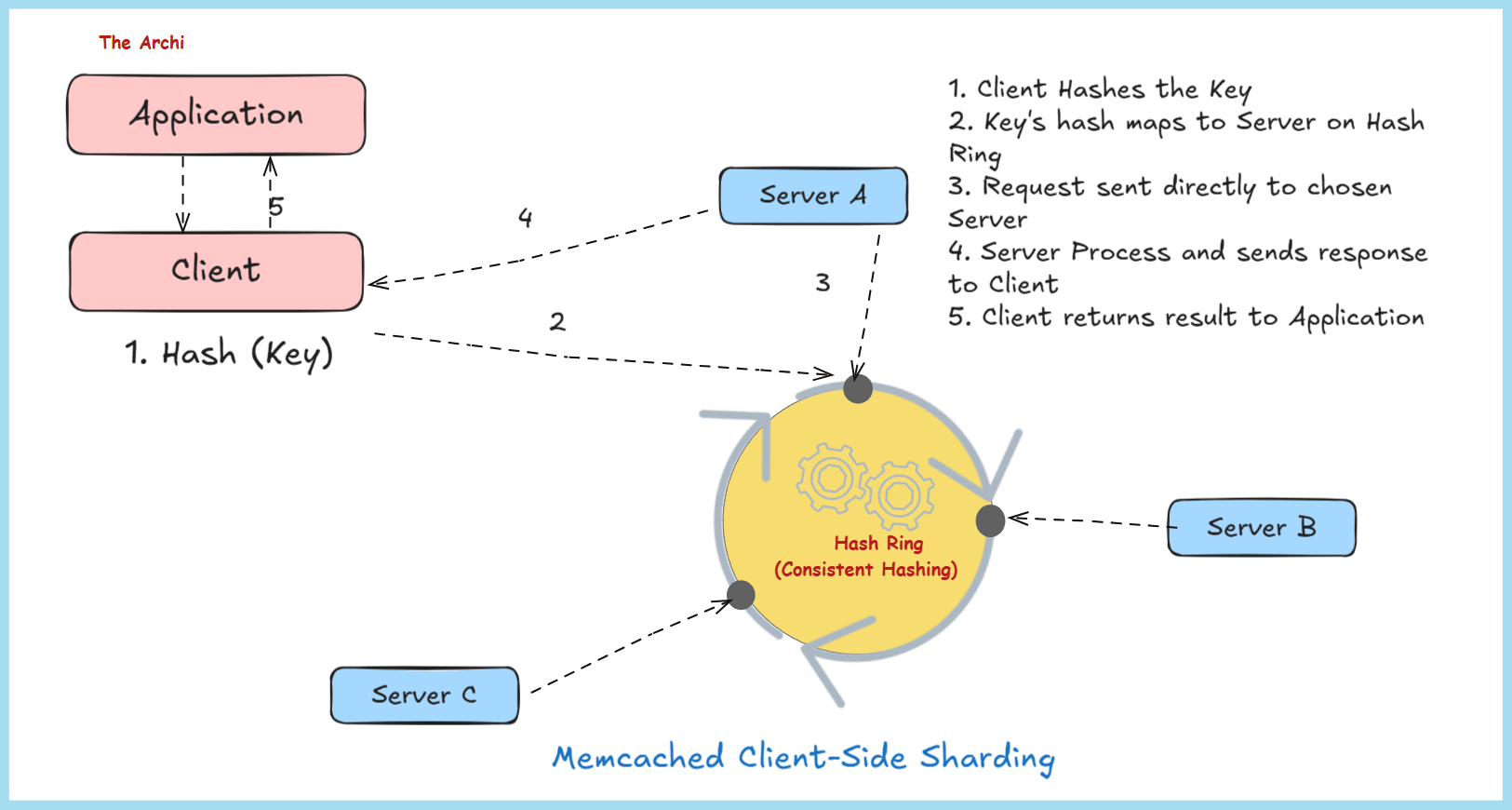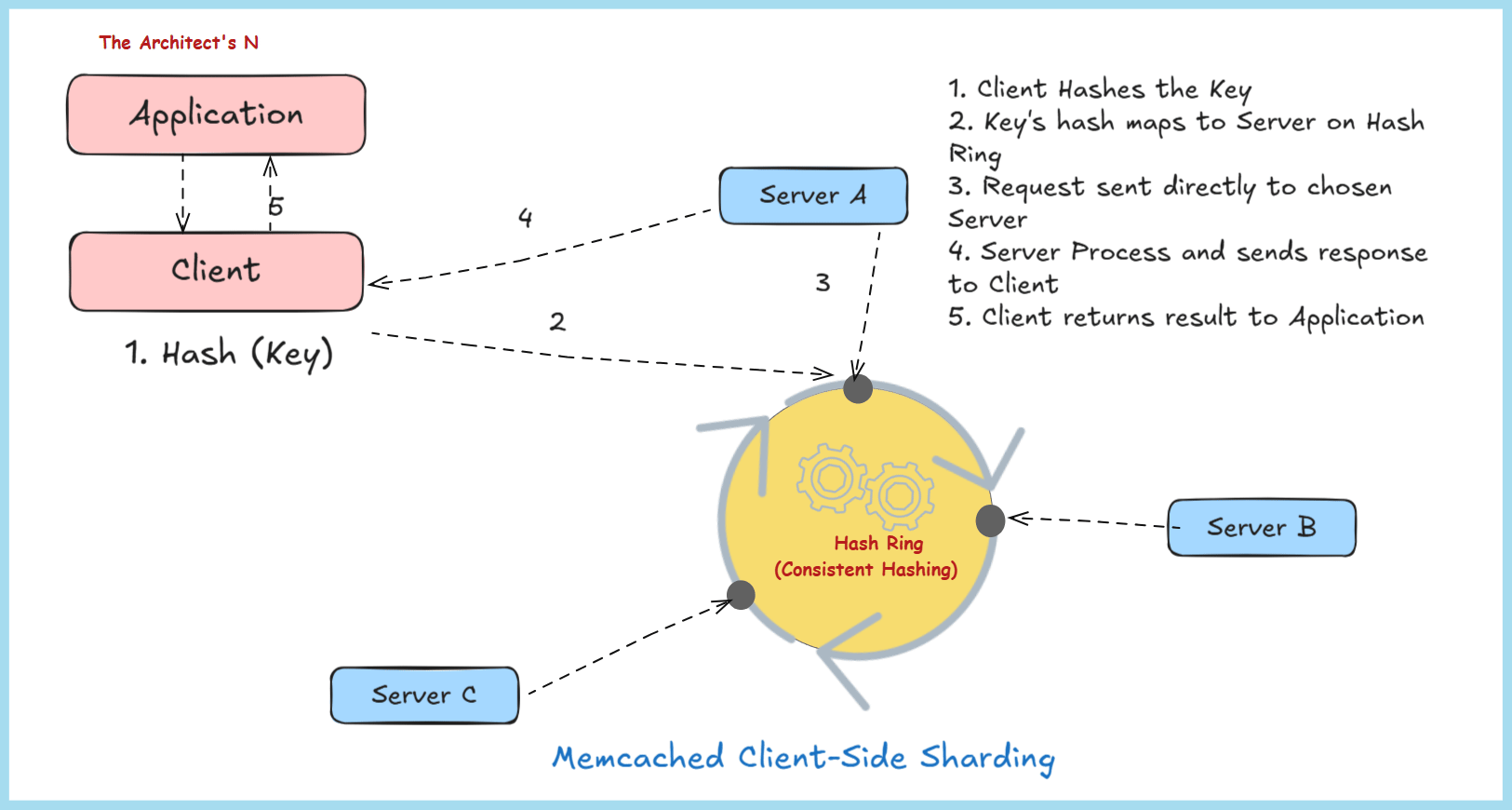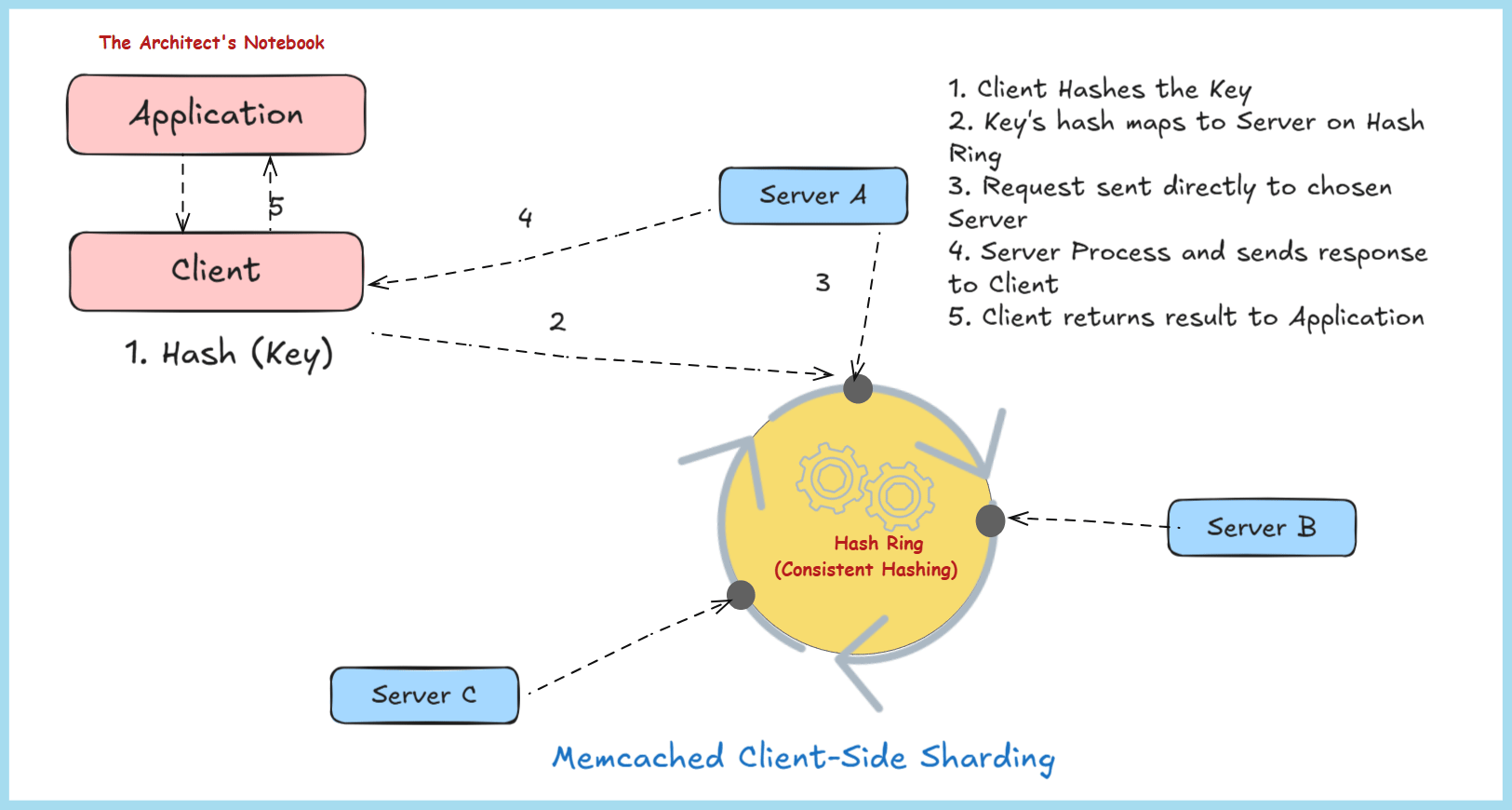
1.3 Consistent Hashing
Consistent hashing is a key distribution mechanism that ensures keys are evenly spread across multiple Memcached servers and minimizes data movement when servers are added or removed. Here’s how it works:
Key → Hash Function → Server Selection → Storage/RetrievalThe client library applies a hash function (e.g., MD5, CRC32) to the key, generating a fixed-size hash value.
This hash value is mapped to a point on a virtual ring (a circular number space, often visualized as a hash ring).
Each server is also assigned multiple points on the ring (via virtual nodes) to improve load balancing.
The key is assigned to the server whose point on the ring is closest (clockwise or counterclockwise, depending on the implementation).
The client sends the storage or retrieval request to the selected server.
Benefits of Consistent Hashing:
Minimal Data Movement: When a server is added or removed, only a small fraction of keys need to be redistributed (proportional to 1/n, where n is the number of servers). This contrasts with traditional hashing, where all keys might need remapping.
Load Balancing: Virtual nodes ensure that keys are distributed evenly, preventing any single server from becoming a bottleneck.
Scalability: Adding or removing servers is seamless, making Memcached suitable for dynamic, large-scale systems.
If you want to read more about Consistent Hashing, refer these articles:
Cracking Consistent Hashing: Why It Matters in Distributed Systems
Cracking Consistent Hashing: How It Works and Where It's Used
Conclusion
Memcached is a robust, high-performance caching solution that excels in scenarios requiring low-latency data access. Its centralized architecture, consistent hashing, and support for parallel operations make it ideal for distributed systems. However, its in-memory nature means data loss on crashes, requiring careful consideration of cache rebuild strategies. By leveraging Memcached, developers can significantly enhance application performance, making it a cornerstone of modern, scalable architectures.
What’s Next (Teaser for Next Post)
“In the next premium part of this series, we’ll go deeper into Memcached’s internal workings and operational strategies. We’ll cover:
Memory Management Architecture: Slab Allocation System, LRU
Network Architecture: Connection Handling, Protocol Details
Distribution Strategy: Client-Side Sharding, Failover Mechanism
Client Interaction with Memcached
Horizontal Scalability
Advantages and Drawbacks of Memcached
Common Mistakes and Best Practices
Stay tuned as we uncover how Memcached manages memory, handles scale, and what you need to know to use it effectively in production.”
– Amit Raghuvanshi
Author, The Architect’s Notebook
Stay tuned 👀
Latency is the amount of time it takes for data to travel from one point to another or for a system to respond to a request. It is essentially a delay between when an action is initiated and when the effect is observed, often measured in milliseconds. High latency leads to slower response times and can negatively affect user experience.
Session objects are data structures used in web development and computer programming to store information about a user’s interaction with an application across multiple requests. They keep track of user data - like login status, preferences, or other settings throughout a session, allowing users to move between pages without losing context. Each user gets a unique session object, which the server creates when a session starts and destroys when it ends.
A cache cluster is a group of interconnected cache servers or instances that work together to store and deliver frequently accessed data. By combining the resources of multiple caches, a cache cluster can handle more requests at once, improve performance, balance workload across system nodes, and offer greater reliability. If one cache fails, others in the cluster can still provide the needed data, which reduces load on the main application or database and improves overall system efficiency.
A BLOB, which stands for Binary Large Object, is a data type used in databases to store large amounts of binary data as a single entity. BLOBs are typically used for storing multimedia files like images, videos, audio, or other complex files that aren’t practical to save in regular text fields. They allow databases to efficiently manage and retrieve large, unstructured data objects.
A hash table is a data structure that stores key-value pairs for fast data retrieval. It uses a hash function to convert a key into an index in an array, where the corresponding value is stored. This allows quick insertion, lookup, and deletion of data. Hash tables handle collisions when two keys produce the same index, through methods like chaining or open addressing. They are widely used in databases, caching, and programming for efficient data access.
Sharding is a database technique that divides a large database into smaller, more manageable pieces called shards. Each shard holds a portion of the data and is stored on separate servers or nodes. This approach improves performance and scalability by distributing the workload, allowing faster data access and preventing any single server from becoming a bottleneck. Sharding also enhances availability, as the failure of one shard doesn’t bring down the entire system.
Libevent is a software library that provides asynchronous event notification, allowing programs to execute callback functions when specific events happen such as activity on a file descriptor or timeout expiration. It simplifies event-driven programming by replacing traditional event loops with a more scalable, portable mechanism that supports multiple platforms and backends like epoll, kqueue, and Windows IOCP. Libevent is commonly used for building high-performance network servers and includes features such as support for signals, timers, buffered network I/O, and asynchronous DNS resolution.
The Memcached protocol is a simple, lightweight communication protocol used by clients to interact with Memcached servers. It primarily uses a text-based protocol over TCP/IP or UDP to perform operations like storing, retrieving, and deleting key-value pairs. Memcached supports several protocols including the basic Text protocol, a newer Meta Text protocol (recommended for new clients for better efficiency and features), and a deprecated Binary protocol. The protocol defines commands for managing cache items with keys, flags, expiration times, and data payloads, enabling high-performance caching in distributed environments.
Persistent connections are network connections that remain open and reusable for multiple requests between a client and a server, instead of opening and closing a new connection for every request. In Memcached, persistent connections allow a client to maintain long-lived connections to the cache servers, which reduces the overhead of repeatedly establishing connections and improves performance by lowering latency. However, when using persistent connections, it's important to manage server lists carefully to avoid creating too many duplicate connections, as this can lead to resource exhaustion.