

Ep #43: The Evolution of Facebook's Architecture: From Dorm Room to Global Scale - Part 4
Exploring the architecture behind mobile apps, edge computing, and the next generation of social experiences

Ep #43: Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Sep 25, 2025 · Premium Post ·
Quick Recap of Part 1, 2, and 3
Part 1: The Humble Beginnings (2004–2006)
We started with Facebook’s dorm-room origins on a simple LAMP stack, the challenges of mutual friends, early database sharding, and the first steps toward scalability with CDNs. This was the era of rapid growth across universities, where architecture was held together by creative patches and scrappy engineering.Part 2: Opening to the World (2006–2015)
As Facebook went public and expanded globally, it faced fan-out storms, photo storage explosions, and massive platform traffic. We explored how Facebook built Haystack, Channel Server, BigPipe, HipHop, Cassandra, Hadoop, Scribe, Puma, Swift, TAO, Prism, and Corona. This was the age of taming data deluge and re-architecting for service-oriented systems.Part 3: The Data Deluge & Mobile Revolution (2010–2016)
The focus shifted to mobile-first engineering and real-time scale. We saw how GraphQL, Zero Protocol, React, and Flux revolutionized the frontend, while backend systems like Hadoop, TAO, Prism, and Corona evolved to manage petabytes of data and global traffic. This was where Facebook transformed from a “website” into a global mobile platform.Let’s head over to the final installment of the Facebook architectural transition.
The Global Empire Era (2015-2020)
When Facebook Conquered the World
As Facebook approached 2 billion users worldwide, the challenges shifted from technical scaling to global infrastructure. Serving users across continents, cultures, and regulatory environments required architectural innovations that went beyond traditional distributed systems.
The Global Latency Challenge
Users in Mumbai, São Paulo, and Lagos expected the same instant experience as users in San Francisco. But physics remained undefeated - data traveling thousands of miles still took time, and centralized data centers created unacceptable delays for global users.
The Edge Computing Revolution: Facebook built one of the world's most sophisticated edge computing networks:
150+ edge locations worldwide strategically placed near population centers
Smart routing algorithms that considered network conditions in real-time
Local caching of frequently accessed content
Edge compute capabilities for real-time personalization
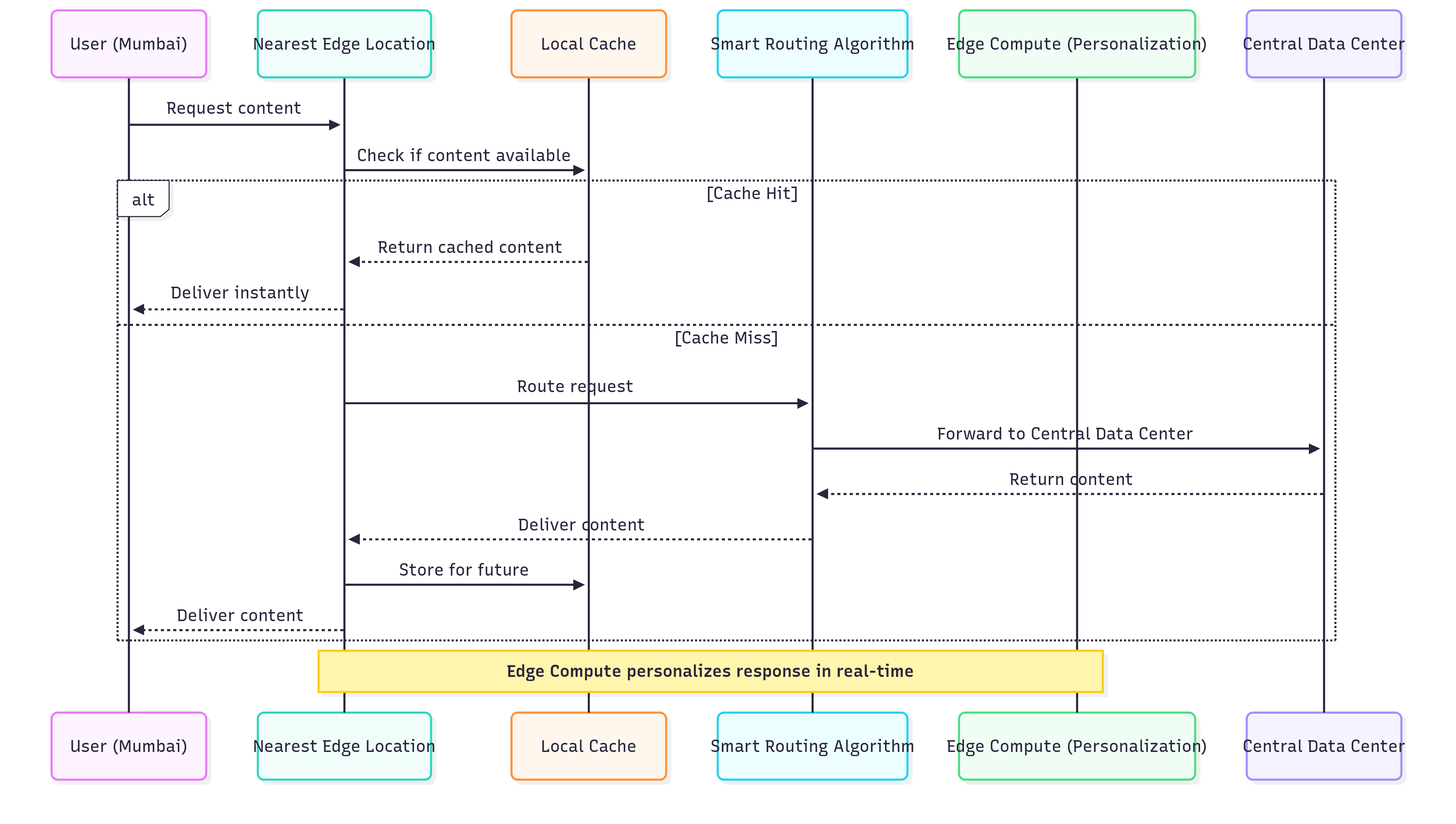
Flow Explained
User sends a request to nearest Edge location.
Cache check:
If hit → instant response.
If miss → routed intelligently to the central data center, then cached.
Edge Compute personalizes data before delivery.
This wasn't just about speed - it was about creating a truly global platform where geographic location didn't determine user experience quality.
The Storage Engine Crisis
Facebook's data storage needs had evolved beyond what traditional databases could handle efficiently. They needed a storage engine optimized for modern hardware (particularly flash storage) and Facebook's specific access patterns.
The RocksDB1 Innovation: Facebook developed RocksDB, a high-performance storage engine built from the ground up:
LSM-tree based architecture optimized for write-heavy workloads
Designed specifically for flash storage characteristics
Column family support for organized data storage
Became the foundation for numerous database systems industry-wide
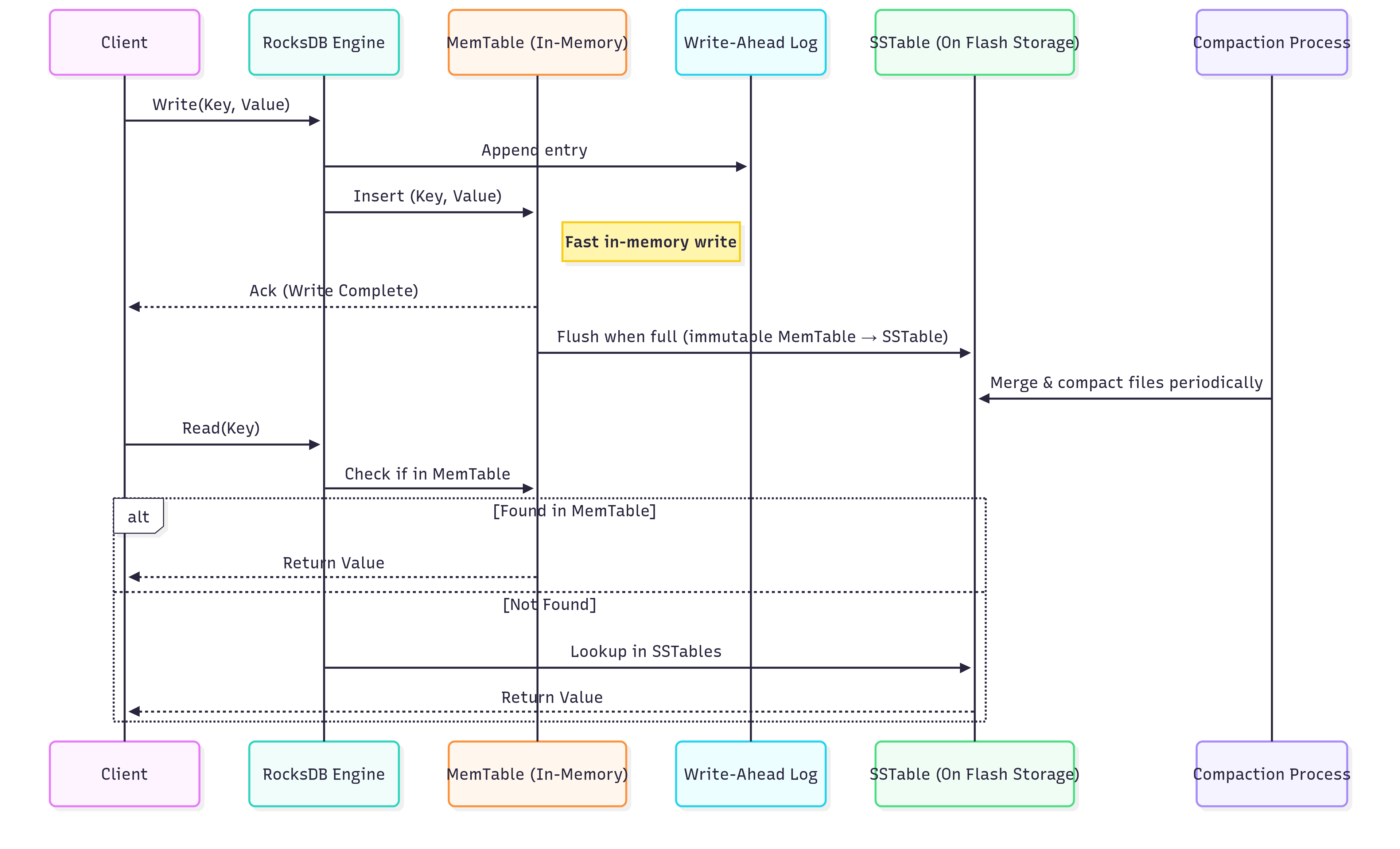
What this shows:
Write path → WAL (safety) + MemTable (speed), later flushed to SSTable.
Compaction → Background process merging SSTs.
Read path → First checks MemTable, then SSTables on flash.
The Service Communication Evolution
With hundreds of services communicating across the globe, efficient serialization and service communication became critical. Facebook needed protocols that were both efficient and developer-friendly.
Let me tell you a joke
TAO stores billions of connections in a graph.
It’s basically the largest relationship 💞 tracker ever built.
Proof that even computers struggle to understand human relationships 😂.
The Thrift Evolution: Facebook enhanced Apache Thrift2 with:
Compact binary protocols for reduced bandwidth
Async service frameworks for better performance
Built-in load balancing and service discovery
Circuit breaker patterns for reliability
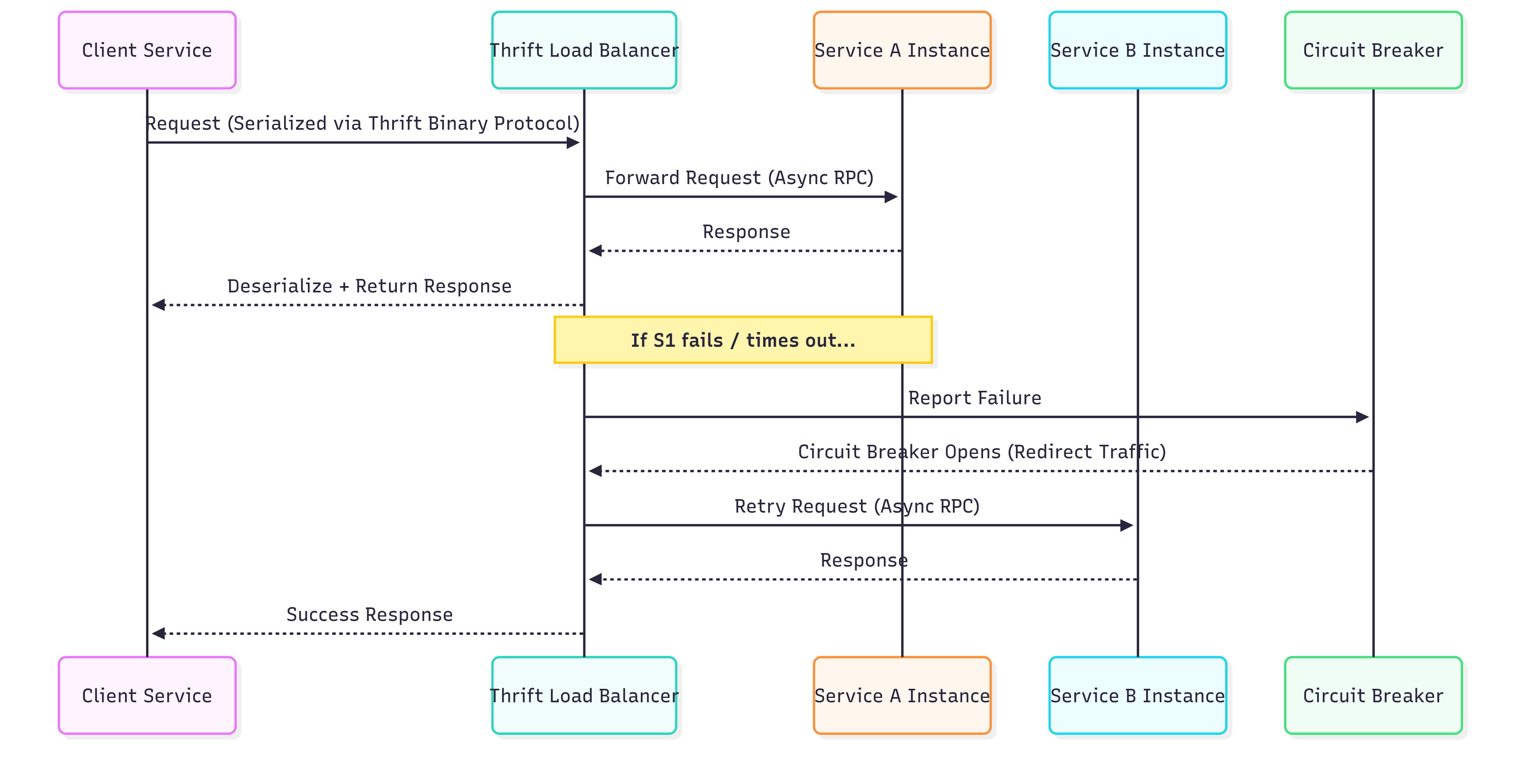
What this shows
Client sends a request through Thrift with compact binary serialization.
The Load Balancer routes requests to service instances.
If a service fails, the Circuit Breaker trips and traffic is rerouted.
Async RPC + retries ensure minimal latency and high reliability.
The AI and Machine Learning Platform
As machine learning became central to Facebook's products, they needed infrastructure that could support both research and production at massive scale.
The PyTorch Innovation: Facebook developed PyTorch3, a deep learning framework that bridged research and production:
Dynamic computational graphs for flexible model development
Seamless transition from research prototypes to production systems
Became one of the most popular machine learning frameworks globally
The FBLearner Flow: Facebook built an end-to-end machine learning platform:
Feature engineering pipelines for consistent data processing
Model training infrastructure that could handle massive datasets
A/B testing integration for scientific model evaluation
Automated deployment and monitoring for production models
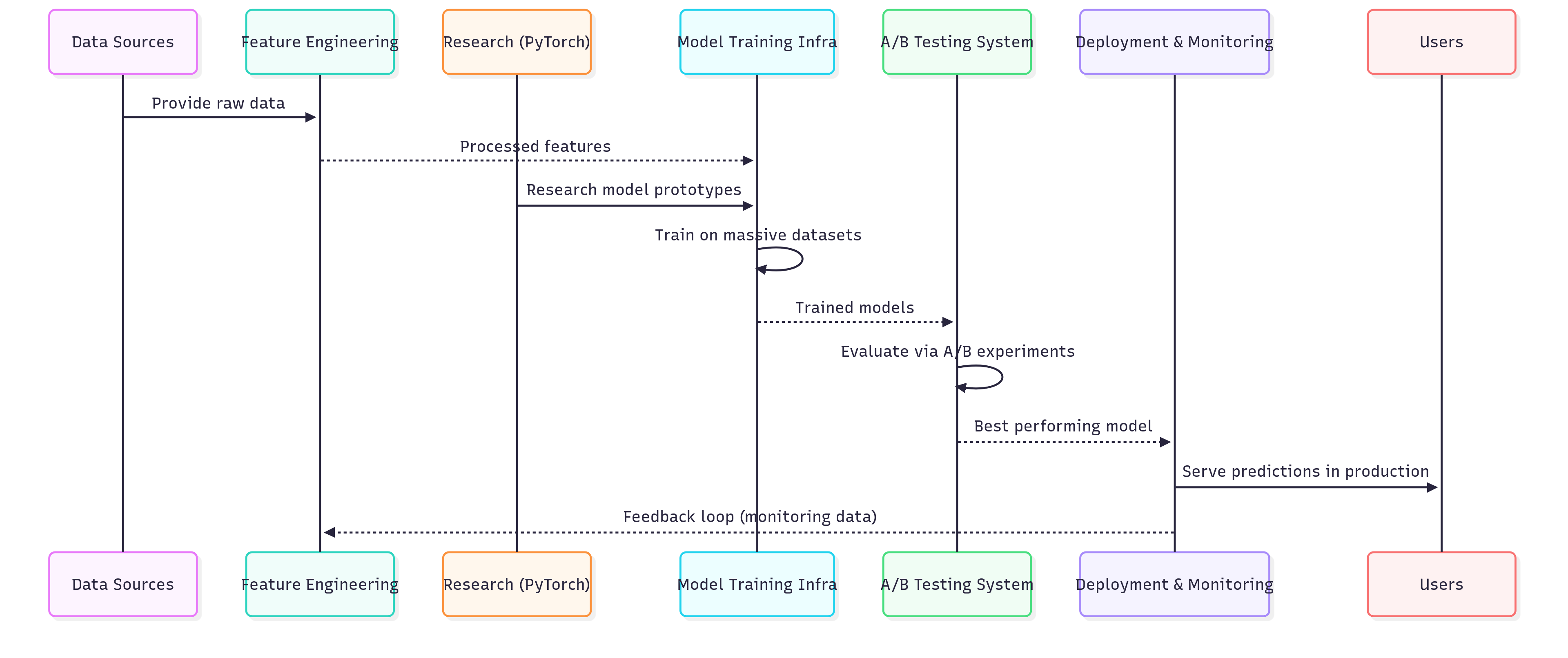
Explanation:
Data Sources feed into Feature Engineering for consistent inputs.
PyTorch provides research → production model transition.
Training handles massive scale.
A/B testing ensures scientific evaluation - only the best models go live.
Deployment serves predictions to users and feeds monitoring data back to improve models.
The Real-Time AI Challenge
Serving machine learning models to billions of users in real-time created unprecedented infrastructure challenges. Models needed to process requests in milliseconds while continuously learning from new data.
The High-Performance ML Serving: Facebook developed infrastructure for:
Sub-millisecond model inference at massive scale
Real-time feature computation and serving
Online learning systems that updated models continuously
Automated model deployment with safety guarantees
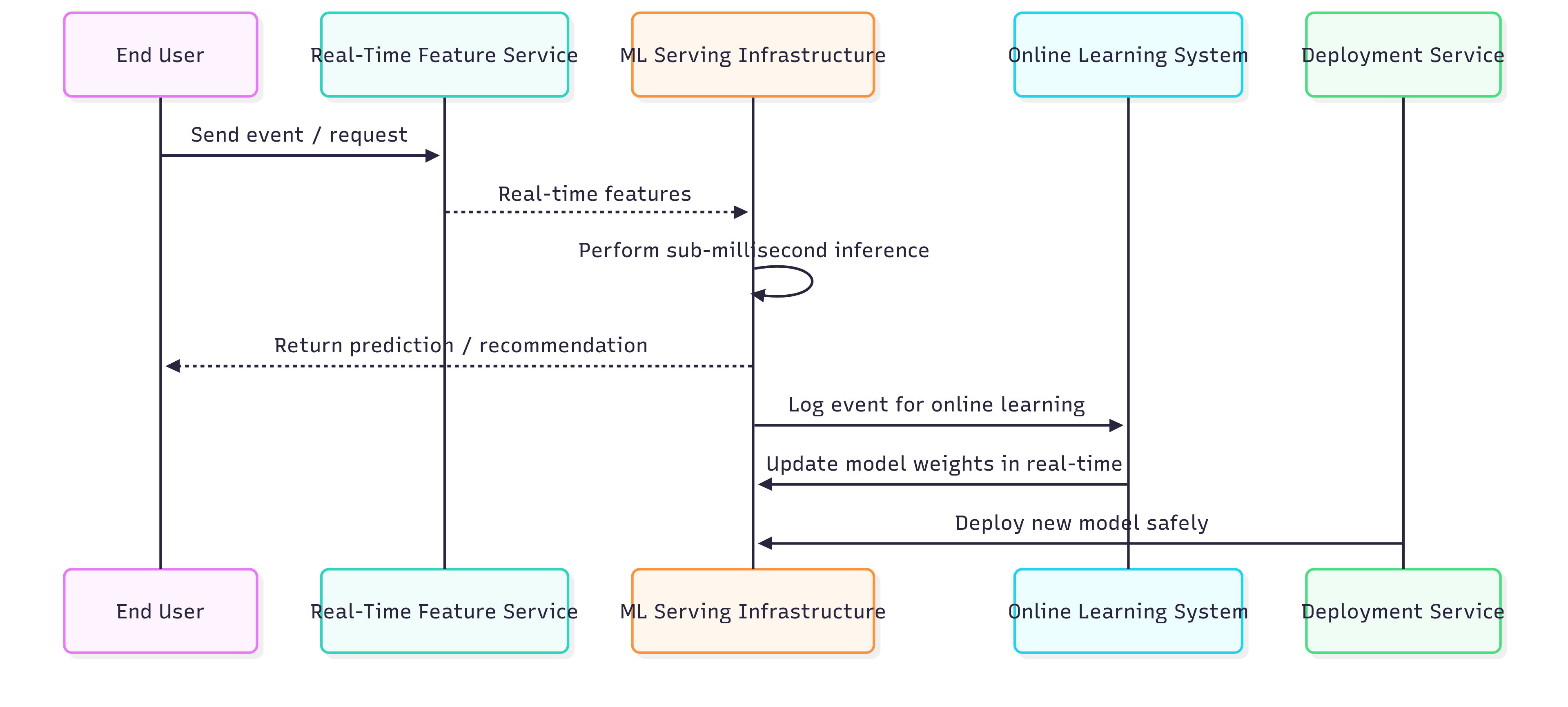
Flow:
User triggers an event → Real-time data feeds into feature computation: feature service calculates real-time features.
ML serving uses features to infer predictions in sub-millisecond latency.
Predictions are returned to the user instantly.
Events are logged for online learning; model weights update continuously.
Deployment system pushes updated models safely without downtime.
By 2020, Facebook's architecture had evolved into something unprecedented: a global, AI-powered platform that could serve personalized experiences to billions of users with millisecond latencies, regardless of their location on Earth.
The Modern Era (2020-Present)
The Metaverse and Beyond
As Facebook transformed into Meta, the architectural challenges shifted once again. Building virtual worlds, supporting augmented reality, and creating the metaverse required solving problems that had never been solved before at such scale.
🔒 This is a premium post: an exclusive insight
👉 To access the full content, continue reading via the Premium Series below:
Please note: all the Premium Memberships of The Architect’s Notebook are managed through Gumroad.
✨ System design insight: Studying the end result alone won’t make you better. Studying the transitions will. Paid members get detailed breakdowns of these transitions, helping you think like the architects who built them.
Already a Paid Member? - Continue the series below