

Ep #40: The Evolution of Facebook's Architecture: From Dorm Room to Global Scale - Part 3
Exploring the systems that powered Facebook’s data explosion and its transition from a web app to a mobile-first global platform

Ep #40: Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Sep 18, 2025 · Premium Post ·
Recap of Part 1 & Part 2
Part 1: The Humble Beginnings (2004–2006)
Facebook started as a dorm-room project at Harvard, powered by a simple LAMP stack (PHP, Apache, MySQL, Linux). Early challenges included:
Exploding friend networks and slow queries (“The First Crisis: Too Many Friends”)
Calculating mutual friends efficiently
Handling monolithic application limits with database sharding
Delivering content across universities with early CDN strategies
These early decisions established a culture of fast iteration, problem-driven infrastructure, and creative engineering solutions.
You can read Part 1 here.
Part 2: Opening to the World & Scaling Globally (2006–2012)
As Facebook opened to the public, the platform faced massive fan-out, growing datasets, and global adoption. Key architectural innovations included:
Haystack and Channel Server to manage media and notifications efficiently
SOA and sandbox architecture to handle third-party apps safely
BigPipe for streaming pagelets, HipHop Compiler for PHP performance, and Cassandra for NoSQL storage
Part 2 showed how Facebook evolved from college-scale infrastructure to global-scale, distributed systems, preparing the foundation for mobile, real-time, and immersive experiences.
You can read Part 2 here.
Why You Should Read This Part
If Part 1 was about Facebook’s humble beginnings, and Part 2 was about scaling to handle global adoption, then Part 3 is where Facebook re-engineered itself for the future. This is the chapter where Facebook not only mastered massive data systems but also embraced the mobile-first revolution that changed the internet forever.
By reading this article, you’ll gain:
Deep insights into data-scale systems – Learn how Hadoop, Scribe, Puma, Swift, TAO, Prism, and Corona handled petabytes of data, real-time logging, and caching at planetary scale.
Understanding of the mobile-first pivot – Discover how GraphQL, Zero Protocol, React, and the Flux pattern reshaped the way Facebook delivered lightning-fast, interactive mobile experiences.
Practical takeaways for modern engineering – See reusable patterns for building real-time pipelines, caching social graphs, and designing APIs that work seamlessly across devices.
Perspective on architectural evolution – Understand how Facebook moved from being a website to becoming a true platform for mobile and global connectivity.
A mental framework for today’s challenges – After this, you’ll be able to reason about how other mobile-first platforms (Instagram, WhatsApp, TikTok, etc.) solve similar problems.
In short: this part shows how Facebook evolved from just handling data to rethinking architecture entirely for a mobile-first, real-time world.
Let’s get started.
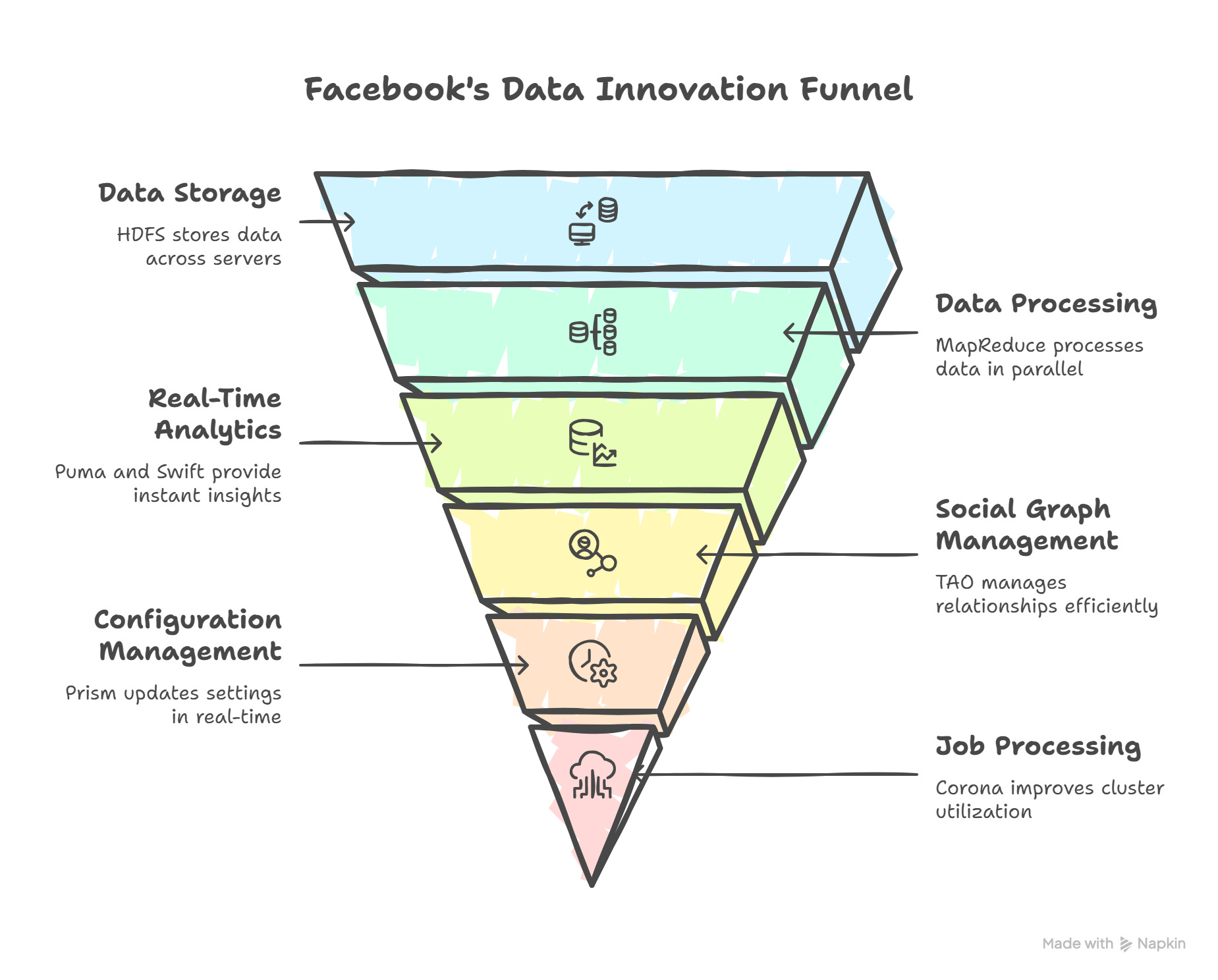
The Data Deluge Era (2010-2015)
When Information Became the New Oil
As Facebook entered the new decade, a new challenge emerged that would dwarf all previous scaling problems: data. Users weren't just connecting with friends - they were sharing, liking, commenting, and interacting at unprecedented rates. Every click, every scroll, every pause was generating data. Facebook was drowning in information, and traditional approaches to data management were completely inadequate.
The Big Data Avalanche
By 2011, Facebook was generating terabytes of data daily. User interactions, system logs, performance metrics, and behavioral data created an avalanche of information that could potentially unlock incredible insights - if they could process it.
The Challenge: Traditional databases and analytics tools were designed for structured data and batch processing. Facebook's data was messy, real-time, and massive. They needed to process both historical data for insights and real-time data for immediate decisions.
The Hadoop1 Revolution: Facebook embraced and extended the Hadoop ecosystem:
HDFS2 for storing massive datasets across thousands of servers
MapReduce3 for processing data in parallel
Hive4 for SQL-like querying of big data
HBase5 for real-time access to large datasets
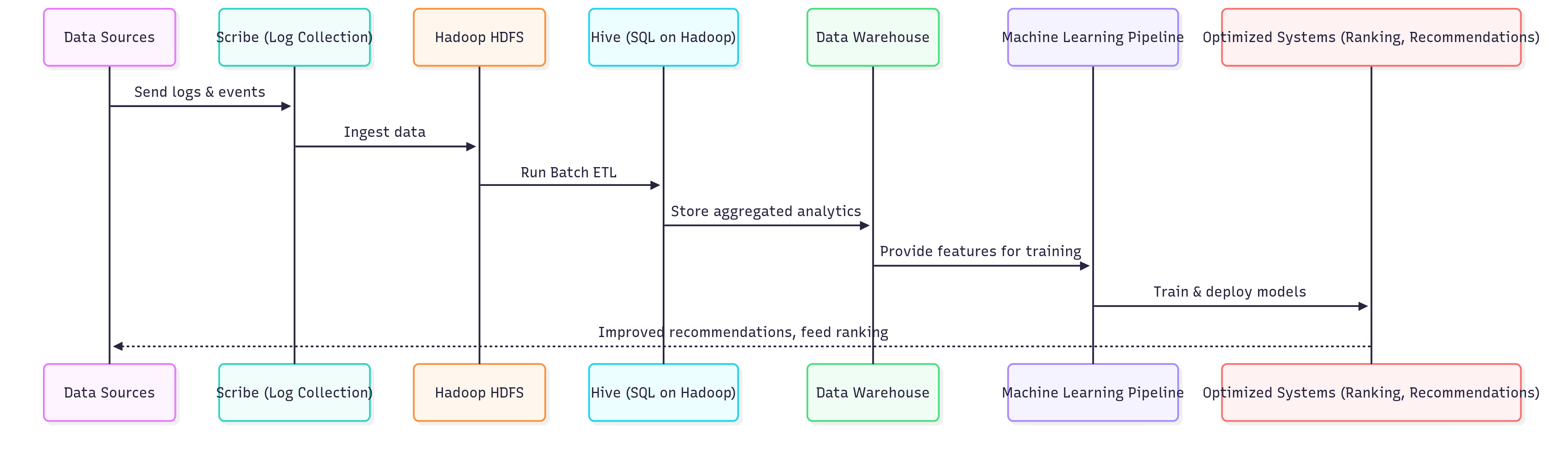
Explanation:
Logs flow from Facebook apps into Scribe6.
Scribe collects and pushes into HDFS.
HDFS stores them as raw distributed data.
Hive transforms and structures the data and performs batch ETL.
Data warehouse powers reports + analytics.
ML pipeline extracts features, trains models.
Final optimized systems (like News Feed ranking, ads, friend suggestions) send better results back to users (data sources).
But Facebook didn't just adopt existing tools - they improved them. By optimizing Hive, Facebook made it possible to run complex queries at a scale no one thought possible before.
And while diving into Facebook’s architecture is fascinating, life outside these systems has been equally eye-opening. Life at home is teaching me a very different kind of architecture: parenthood. With twin baby girls👶👶, the days are a mix of chaos and magic✨. Some nights feel like debugging an endless loop of feeding and soothing, but the mornings bring smiles😊 that make every sleepless hour worth it. Watching them explore the world in their own ways reminds me that growth isn’t always about speed or scale. It’s about being present, patient, and celebrating small wins that add up over time. ❤️
The Real-Time Analytics Crisis
Having historical data was valuable, but social media required real-time insights. How many users were online right now? Which posts were going viral? What features were causing problems? Traditional batch processing took hours or days to provide answers - Facebook needed answers in seconds.
The Real-Time Pipeline Innovation:
Scribe aggregated log data from thousands of servers in real-time
Puma7 provided real-time analytics on streaming data
Swift8 processed user events the moment they happened
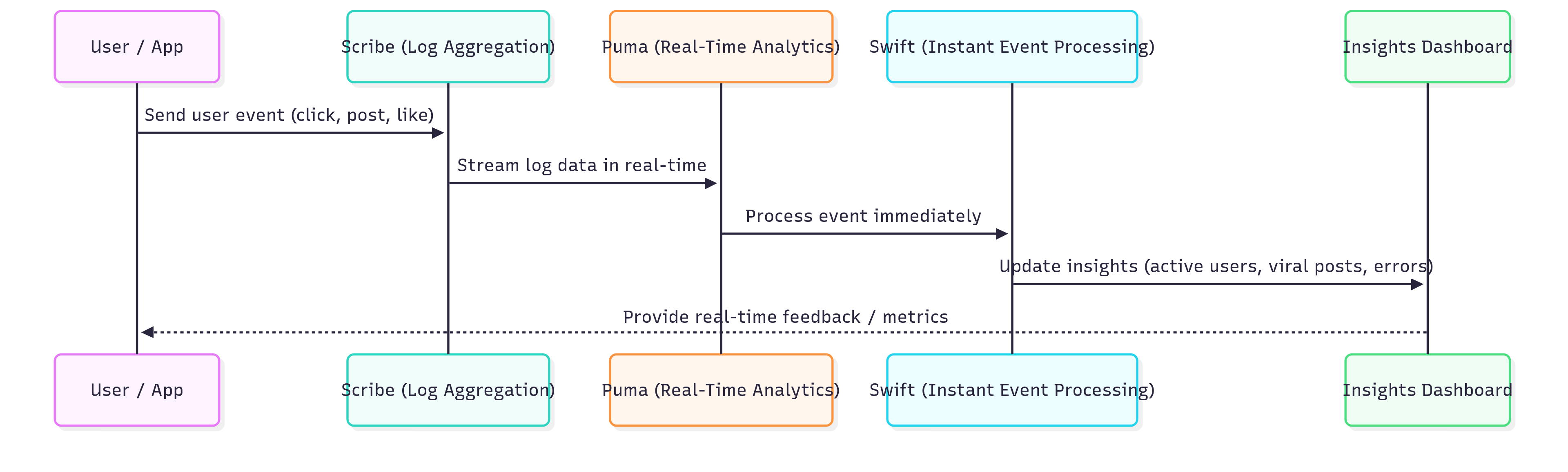
Explanation:
User/App generates events.
Scribe collects logs from thousands of servers instantly.
Puma performs real-time analytics on streaming data (like trending posts, current online users).
Swift processes user events the moment they happen (low latency).
Output flows into insight dashboards & alerting systems, letting Facebook respond within seconds.
This real-time data pipeline became the nervous system of Facebook, enabling instant insights and rapid response to problems.
The Social Graph Database Crisis
Facebook’s biggest treasure wasn’t just posts or photos - it was the network of relationships: who liked what, who was friends with whom, and how everything connected. Traditional databases couldn’t handle these relationships efficiently.
The TAO Revolution: Facebook built TAO (The Associations and Objects)9, a graph-aware caching layer that sat above MySQL and understood the social nature of Facebook's data.
The Genius of TAO:
99.8% cache hit rate for read queries
Reduced database load by orders of magnitude
Provided Graph-aware APIs that understood relationships (users, posts, likes, comments)
Eventual consistency with read-after-write consistency where needed
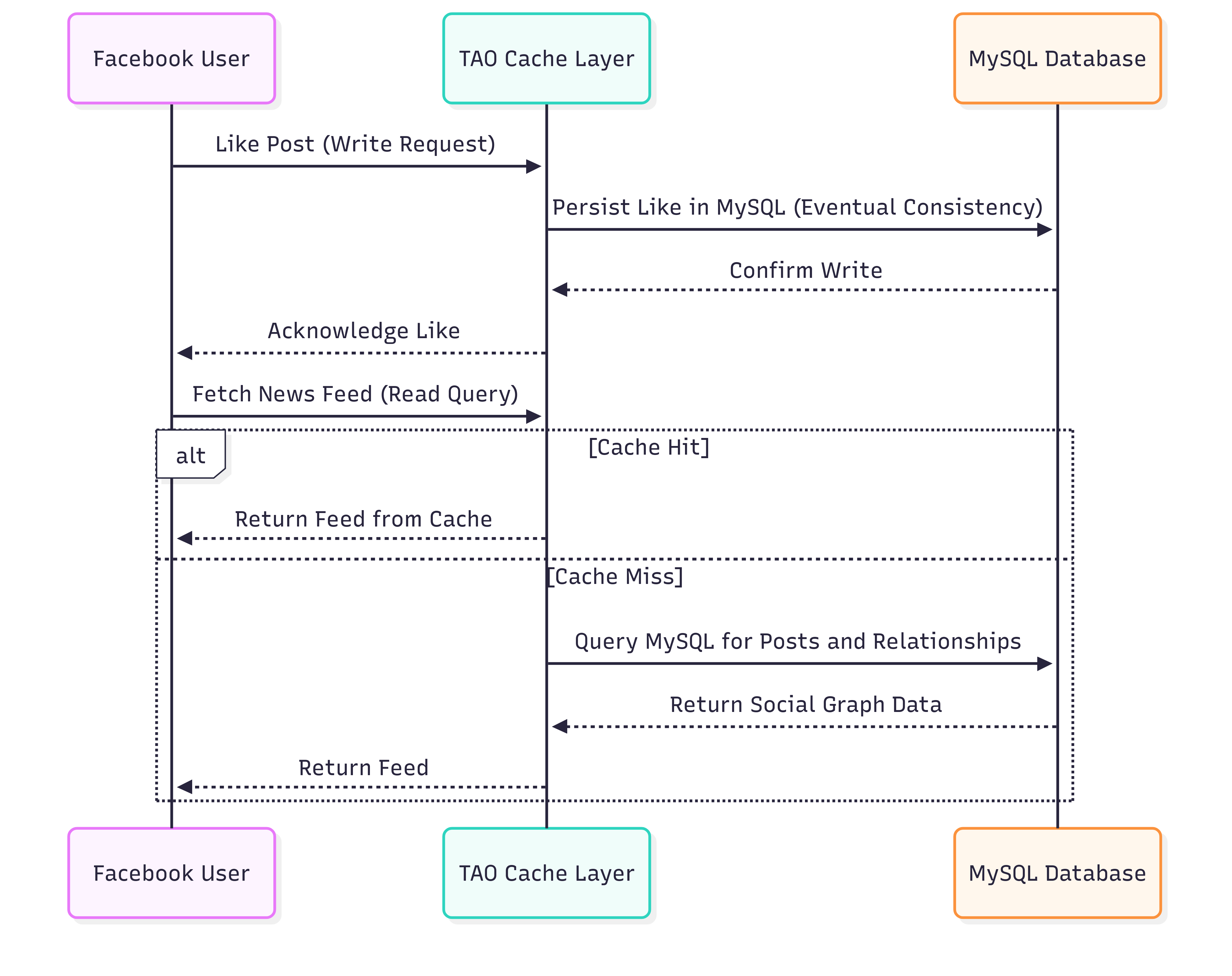
Explanation:
Users, posts, comments, likes, friendships form the social graph.
TAO sits between the app and MySQL, providing:
Graph-aware read queries (99.8% cache hit rate)
Write operations with eventual consistency
Write path: User actions (like/comment) first hit TAO, which writes to MySQL asynchronously.
Read path: Most queries are served directly from TAO cache. On cache miss, TAO queries MySQL and updates the cache.
This read-heavy, graph-aware caching layer enables Facebook to scale social interactions efficiently.
Reduces database load drastically while supporting instant feed updates, notifications, and relationship queries.
TAO Innovations:
Graph-native: Optimized for social graph queries
Cache-aside Pattern: Intelligent caching of graph relationships
Eventual Consistency: Accepting some inconsistency for performance
Horizontal Scaling: Easy addition of new storage nodes
🔒 This is a premium post: an exclusive insight
👉 To access the full content, continue reading via the Premium Series below:
Please note: all the Premium Memberships of The Architect’s Notebook are managed through Gumroad.
✨ System design insight: Studying the end result alone won’t make you better. Studying the transitions will. Paid members get detailed breakdowns of these transitions, helping you think like the architects who built them.
Already a Paid Member? - Continue the series below