

Ep #33: The Evolution of Facebook's Architecture: From Dorm Room to Global Scale - Part 1
From connecting college students to handling massive data—how Facebook solved its first engineering challenges

Ep #33: Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Sep 2, 2025 · Free Post ·
Why Facebook Was Invented: The Beginning
In 2004, Harvard sophomore Mark Zuckerberg spotted a simple yet powerful campus pain point - students lacked a universal, easy-to-access face book. These “face books” were paper directories with student photos and basic info, distributed by colleges but never online or searchable. Zuckerberg saw an opportunity to do what Harvard couldn’t: build a centralized, digital, instant-access face book. In one week, he shipped “TheFacebook,” from his dorm room, launching it on February 4, 2004.
Zuckerberg’s idea was straightforward: give students an easy way to connect, share information, and expand their social circles beyond the walls of their campus. What started as an online version of the printed “face books” on campus would eventually reach nearly 3 billion people worldwide.
This is the story of how Facebook grew from a basic website running on a single server to one of the most advanced distributed systems ever built - a journey filled with growing pains, bold solutions, and constant reinvention.
Why You Should Read This
Understanding Facebook’s early architecture is not just about one company’s engineering story - it’s a masterclass in solving real-world scaling problems from day one. Every design decision in this era came from a concrete challenge: connecting thousands of college students, handling exploding friend networks, calculating mutual friends efficiently, or keeping pages fast under growing load.
By reading this article, you’ll get:
End-to-end clarity – You’ll follow the journey from a dorm-room LAMP app to the first major sharding, caching, and CDN strategies that kept Facebook alive.
Problem → Solution mapping – Instead of abstract theory, you’ll learn how real problems - like the mutual friends computation, monolithic app slowdown, or database bottlenecks, forced Facebook to invent solutions.
Early engineering lessons – Concepts like sharding, caching with memcached, precomputing graph relationships, and CDNs are foundational patterns you can apply to your own systems.
Perspective on trade-offs – Why keep PHP and a monolithic app initially? Why invest in aggressive caching rather than immediately moving to complex distributed systems? These early trade-offs highlight how to balance speed, simplicity, and scalability.
A mental framework – After this post, you’ll better understand how scaling decisions build upon each other, preparing you to follow the next stage of Facebook’s evolution when it opened to the public.
In short: this is the one article you need to understand the first chapters of Facebook’s engineering story - how small problems turned into big lessons that shaped the future of global-scale systems.
Let’s dive into this amazing story.
🚀 Special Offer Reminder:
Join the Yearly Premium Tier by September 5 and receive a free copy of The Architect’s Mindset - A Psychological Guide to Technical Leadership📘, valued at $22! Or better yet, consider it an invaluable resource on your journey to systems leadership to elevate your thinking and skills! ✨
In the meantime, feel free to check out the free sample right here! 👀
Don’t miss out on this exclusive bonus 🎁. Upgrade now and unlock premium content plus this valuable resource! 🔥
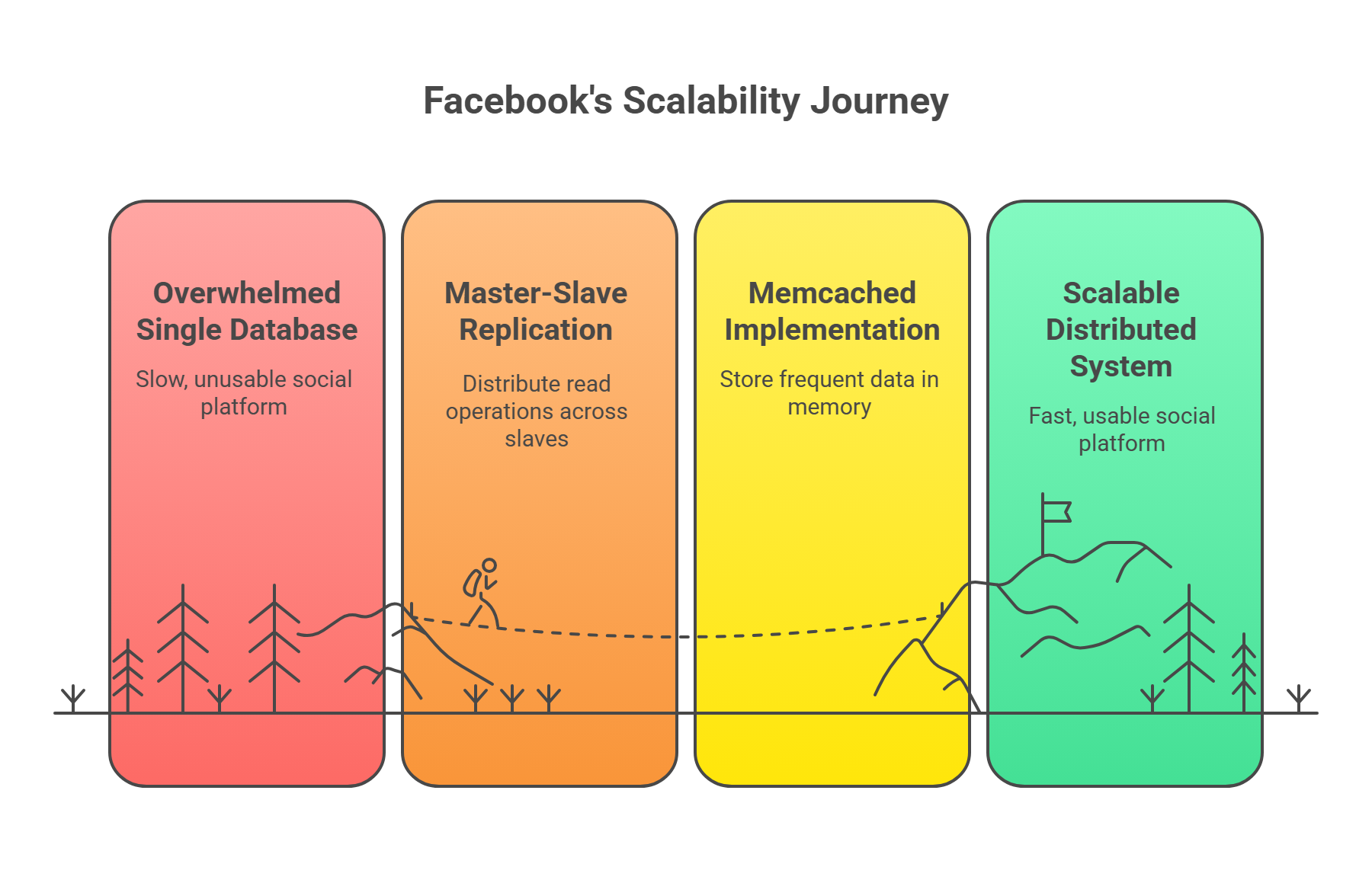
The Humble Beginning (2004-2005)
The Problem: Connecting College Students
In early 2004, social networking wasn't new - Friendster and MySpace already existed. But they were slow, unreliable, and not tailored for the college experience. Students wanted something fast, exclusive, and designed for their specific social dynamics.
Zuckerberg's vision was clear: create a platform where college students could:
Share profile information and photos
Connect with classmates and friends
Browse networks of people within their university
Communicate through messages and wall posts
The Original Architecture: Classic LAMP Stack
The first version of Facebook was built using the most straightforward web architecture available - the LAMP stack:
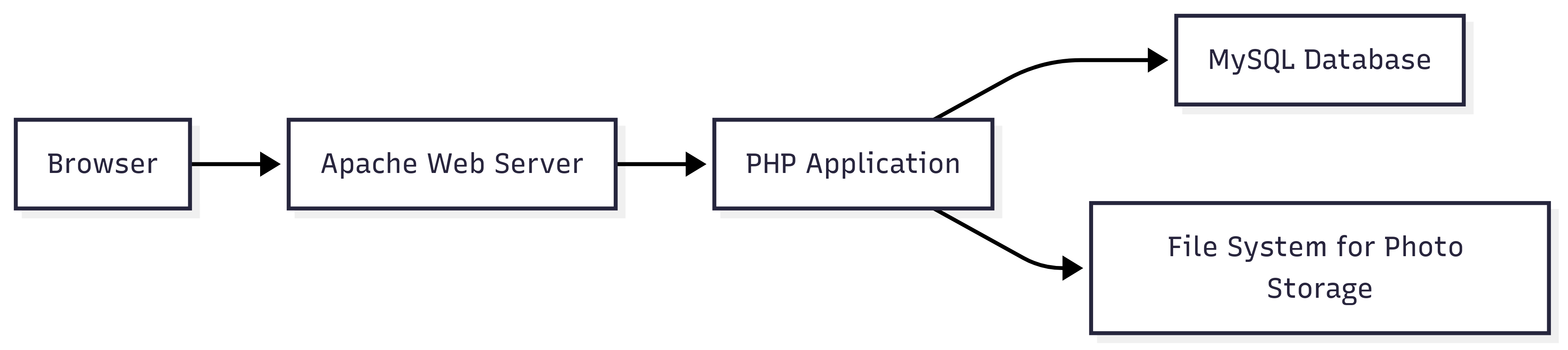
The Components:
(L) Linux1: Red Hat Enterprise Linux as the operating system
(A) Apache2: A lone Apache web server handling HTTP requests
(M) MySQL3: Single database instance storing all user data (profiles and friendships)
(P) PHP4: Server-side scripting language for application logic - PHP scripts processing user interactions
In simple terms, if we talk about the technology stack
Frontend: Basic HTML/CSS with minimal JavaScript
Backend: PHP running on Apache
Database: Single MySQL database
Server: Single physical server in Zuckerberg's dorm room
Architecture Pattern: The classic three-tier LAMP (Linux, Apache, MySQL, PHP) architecture served the initial Harvard community of a few thousand users. The application was essentially a monolithic PHP application with direct database connections.
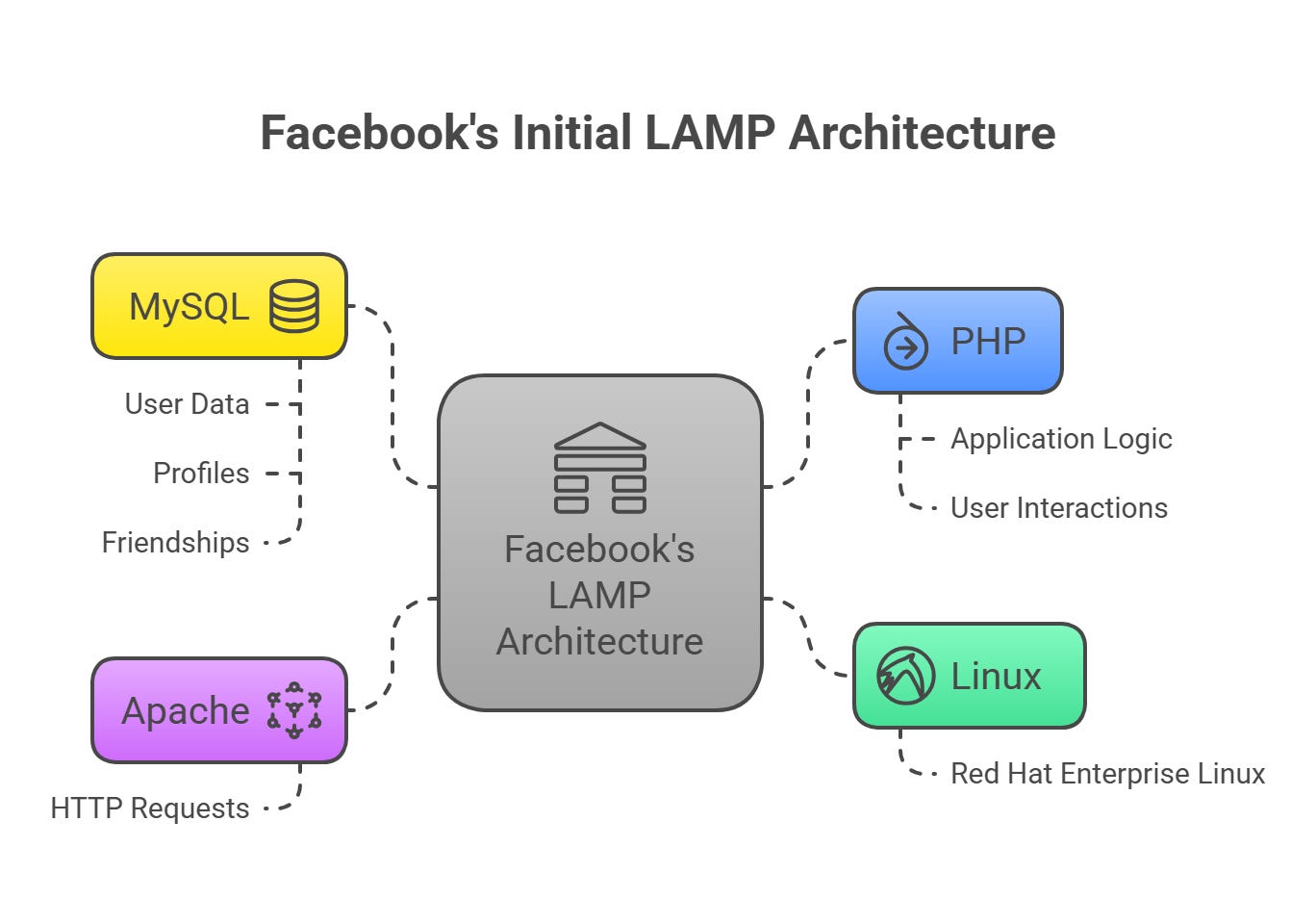
Key Characteristics:
Monolithic codebase
Synchronous request processing
Direct database queries from application code
Session data stored in files
Static content served directly by Apache
The Database Schema:
-- Users table
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
university_id INT,
password_hash VARCHAR(255)
);
-- Friendships table
CREATE TABLE friendships (
user_id_1 INT,
user_id_2 INT,
status ENUM('pending', 'accepted'),
created_at TIMESTAMP
);
-- Posts table
CREATE TABLE posts (
id INT PRIMARY KEY,
user_id INT,
content TEXT,
created_at TIMESTAMP
);"It just needs to work for Harvard," Zuckerberg thought, as he watched his creation spread like wildfire across campus. Little did he know that within months, this simple setup would be screaming for help.
The First Crisis: Too Many Friends
By spring 2004, Facebook was exploding in popularity. Students weren’t just browsing profiles anymore - they were glued to the site, refreshing constantly, messaging each other, and adding friends like crazy. The single lonely server that once handled a few hundred users was now buckling under the weight of thousands.
The Problem
The database couldn’t keep up. Every click triggered a query, and the poor machine was drowning in hundreds of requests at the same time. Pages slowed to a crawl, and frustrated Harvard students started flooding Zuckerberg with complaints.
The Solution
In a moment of desperation and insight, the team implemented their first architectural evolution - connection pooling5 and basic query optimization6. They added a second server and implemented rudimentary load balancing. It was like adding a second lane to a traffic jam - not elegant, but it worked.
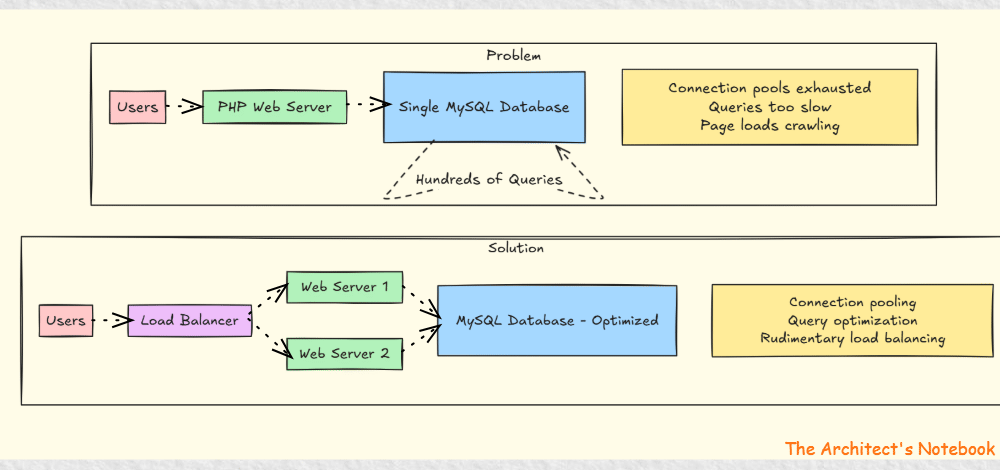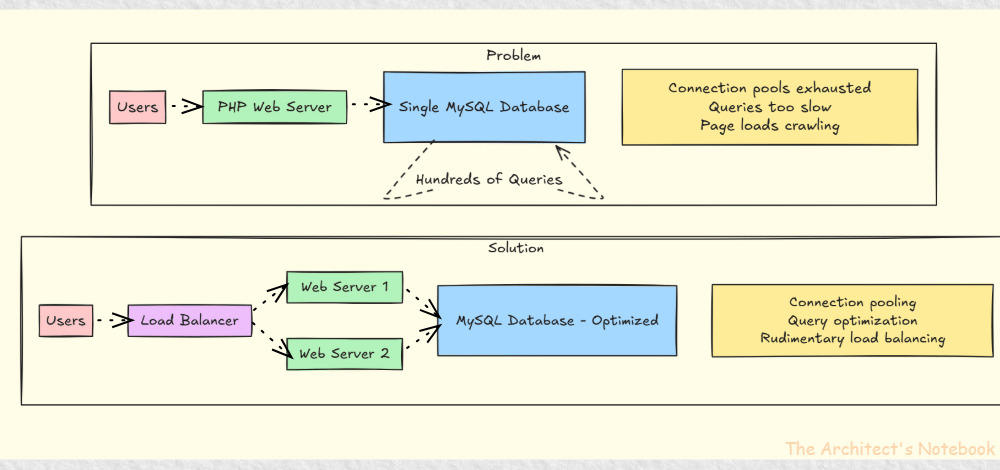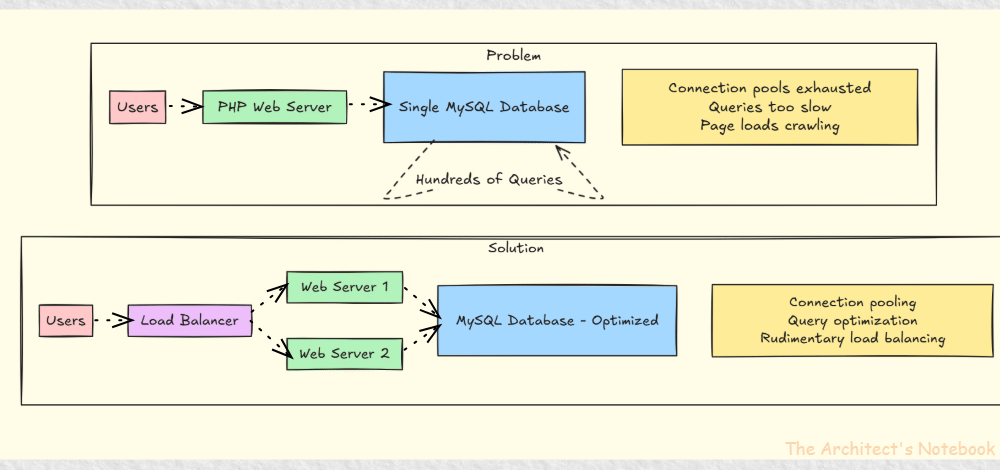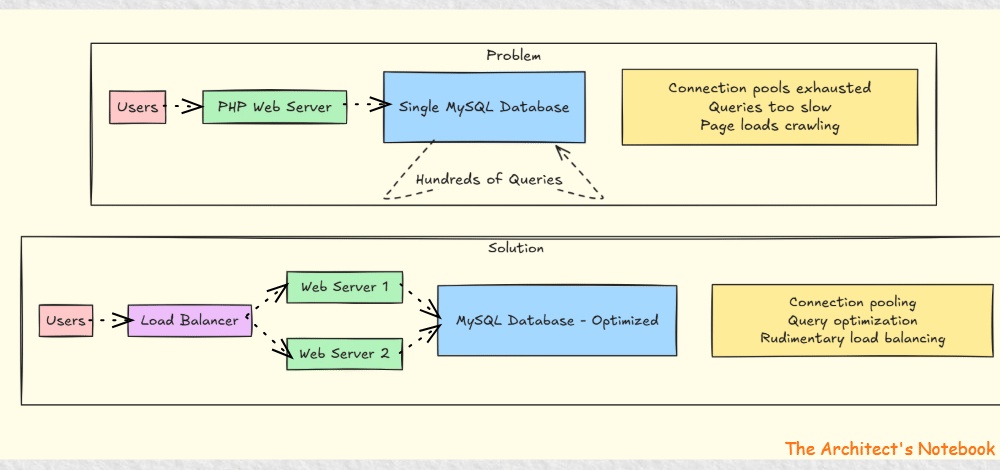
As Facebook spread from Harvard to Yale, Columbia, and Stanford, each new wave of users brought fresh challenges. What worked for 10,000 students fell apart at 50,000. That’s when the team realized something important: they weren’t just running a college website anymore - they were architecting the future of human connection.
TL;DR
Problem 1: Database Connection Overload
Too many concurrent users overwhelming MySQL connections
Solution: Implemented connection pooling and basic query optimization
Problem 2: Server Resource Exhaustion
Single server couldn't handle growing user base
Solution: Added a second server and implemented basic load balancing
The College Revolution (2005-2006)
When Universities Became Digital Kingdoms
By 2005, Facebook had become the digital backbone of American college life. Hundreds of universities and hundreds of thousands of students were logging in daily, sharing photos, posting messages, and living their social lives online. But with great popularity came great architectural headaches.
The Great Database Breakdown
The first major crisis hit like a digital tsunami. The single MySQL database, once the reliable heart of the system, was now the bottleneck strangling everything else. Read queries were piling up, write operations were blocking, and the entire platform was grinding to a halt during peak hours.
The Crisis: Students would click "refresh" and wait... and wait... and wait. Page load times stretched from seconds to minutes. The engineering team watched in horror as their creation became unusable during the very times students wanted to use it most - evenings and weekends.
The Breakthrough: Enter master-slave replication, Facebook's first dance with distributed systems. The team split their database load - all writes went to a master database, while read operations were distributed across multiple slave databases. It was like having one chef prepare meals while multiple servers delivered them to tables.
But they didn't stop there. They introduced their first caching layer using Memcached - a brilliant innovation that stored frequently requested data in memory. Suddenly, common queries that once required database hits could be answered instantly from cache. Page load times dropped from minutes back to seconds, and students could once again live their digital social lives without interruption.
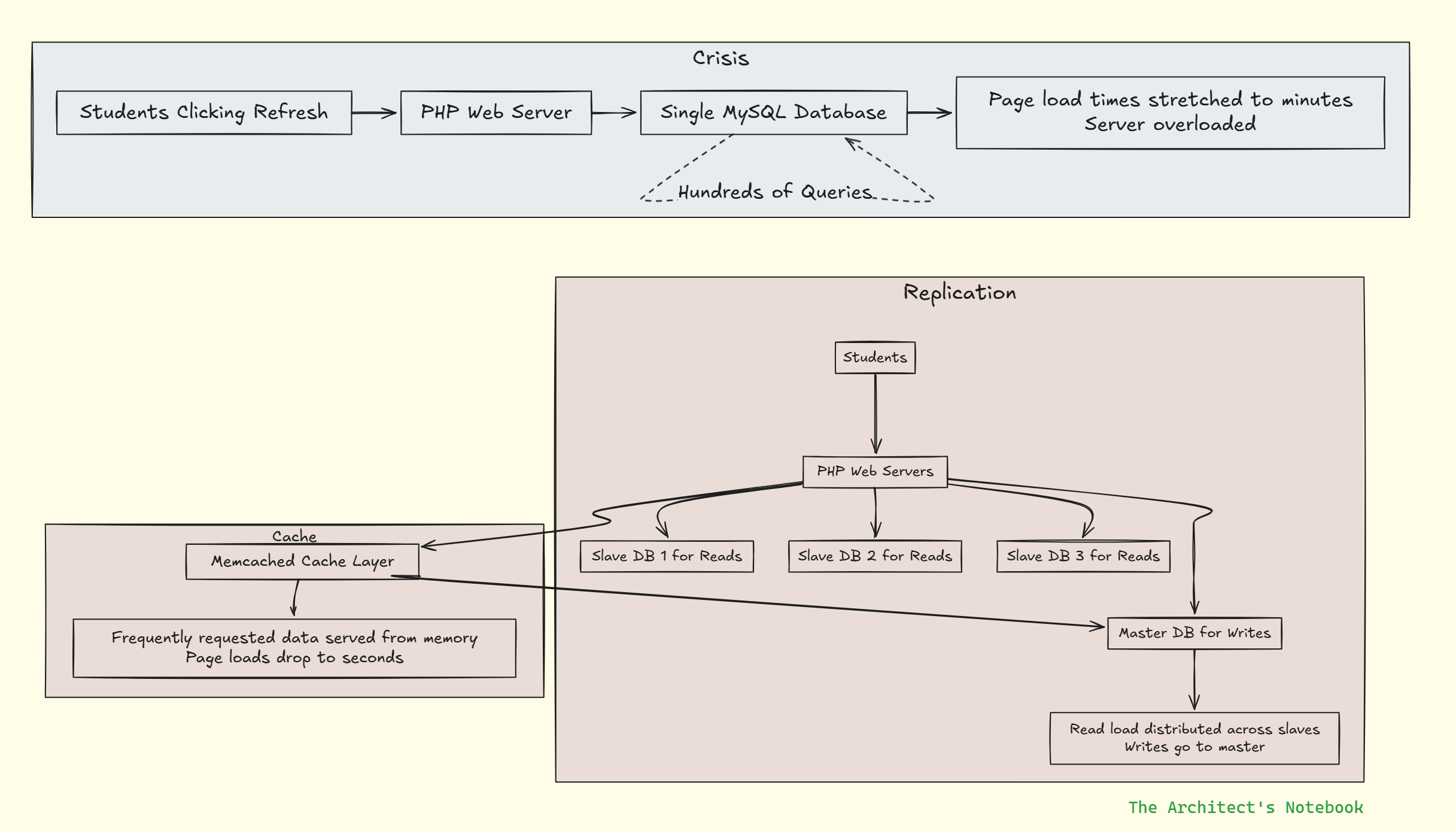
Explanation:
Crisis: Single DB overwhelmed → huge page load times.
Replication: Master handles writes; multiple slaves handle reads → distributed load.
Caching: Memcached stores frequent queries → instant responses, fast page loads.
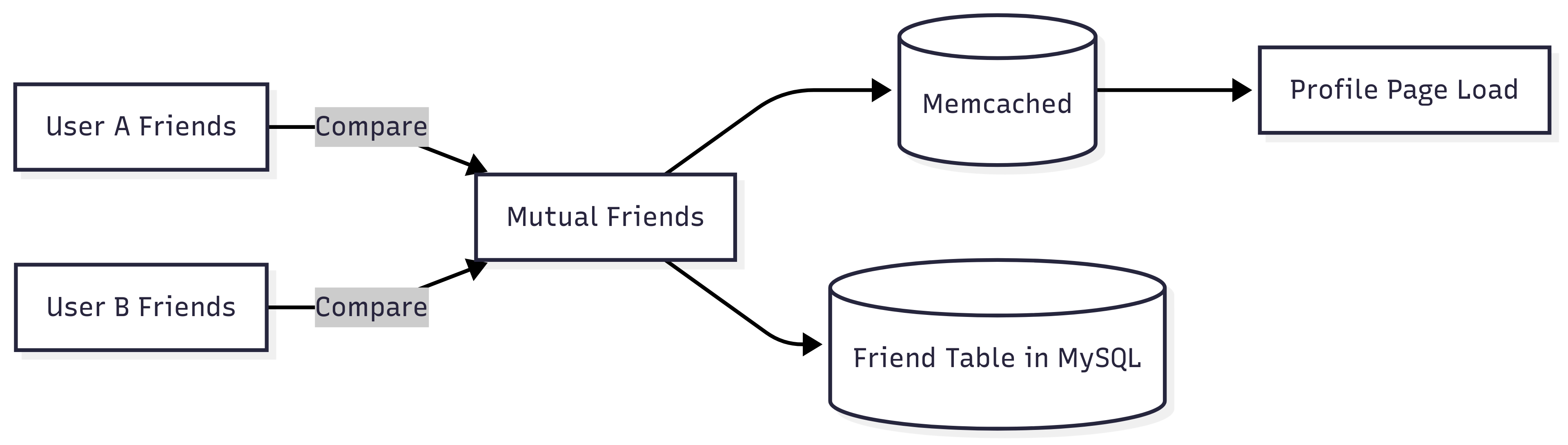
Mutual Friends: The Hidden Graph Problem
One of the first features that made Facebook feel magical was the ability to see which friends you shared with someone else. On the surface, it seems simple: compare your friend list with theirs and show the overlap.
The Early Problem
In 2004–2005, Facebook’s LAMP stack and a single MySQL database were perfectly fine for loading individual profiles, but calculating mutual friends on the fly created a new challenge:
Exploding complexity: For a user with 500 friends, comparing against another user with 500 friends requires potentially 500 × 500 = 250,000 checks.
Slow queries: MySQL at that time couldn’t handle millions of such comparisons without slowing down page load for everyone.
Caching challenges: Even caching mutual friends lists was tricky, because the lists changed whenever someone added or removed a friend.
The Initial Solution
Facebook’s engineers initially tried querying the friend table with JOINs to find overlaps, but it was slow under real load.
They added indexes on friend relationships to speed up queries.
Result caching in memcached became critical: the mutual friends for popular profiles were cached aggressively, so repeated requests didn’t hit the database.
They also started precomputing some of these relationships, storing them in separate tables for frequently visited users. This trade-off of space for speed became a recurring pattern in Facebook’s architecture.
Lessons from Mutual Friends
Even simple social features can expose graph-like computation problems.
Early caching and precomputation were essential to maintain fast page load times.
This feature foreshadowed future graph challenges, which would later inspire TAO, Facebook’s distributed social graph system.
The Problem: The Monolithic Application Crisis
As features multiplied - photo sharing, messaging, groups, events - the PHP codebase became a monolithic monster. Every change risked breaking the entire system, and deployments became increasingly dangerous.
The Monolith Issues:
Single point of failure
Difficult to scale individual features
Code coupling made development slow
Database schema changes affected everything
The Solution: Database Partitioning (Sharding)
Facebook engineers realized they needed to split their growing database. They implemented one of the first large-scale MySQL sharding strategies:
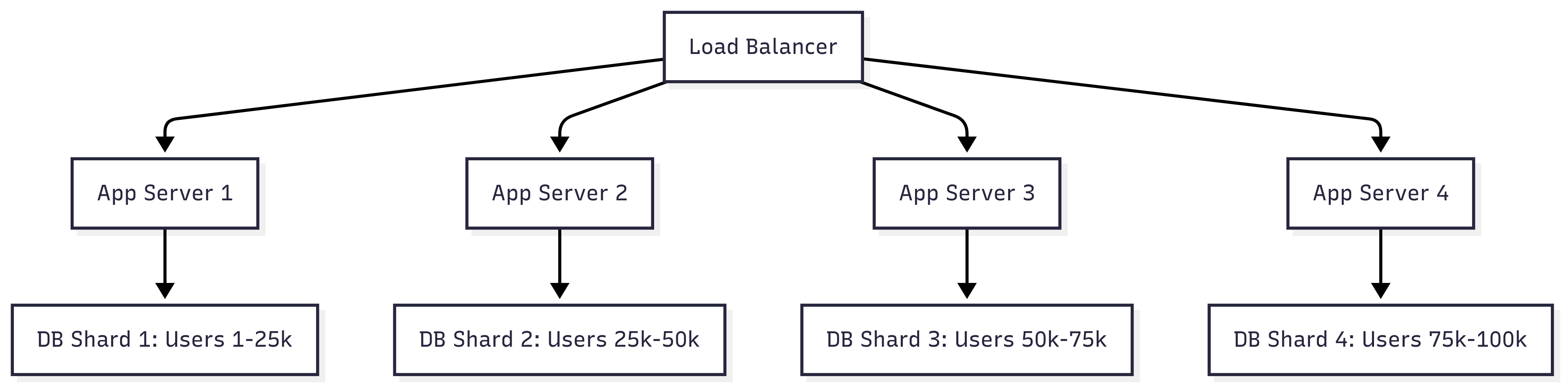
Sharding Strategy: Users were partitioned based on their user ID. For example:
Shard 1: user_id % 4 = 0
Shard 2: user_id % 4 = 1
Shard 3: user_id % 4 = 2
Shard 4: user_id % 4 = 3
New Challenges from Sharding:
Cross-shard queries became complex
Friends might be on different shards
Data consistency across shards
Rebalancing when adding new shards
The Geography Problem
As Facebook spread coast to coast, a new enemy emerged: the speed of light. Students in California were experiencing slow load times because all servers were located on the East Coast. Physics had become their adversary.
The Solution: Content Delivery Networks (CDNs) and strategic server placement. By distributing static content across multiple geographic locations and placing servers on both coasts, they reduced latency and improved the user experience for everyone.
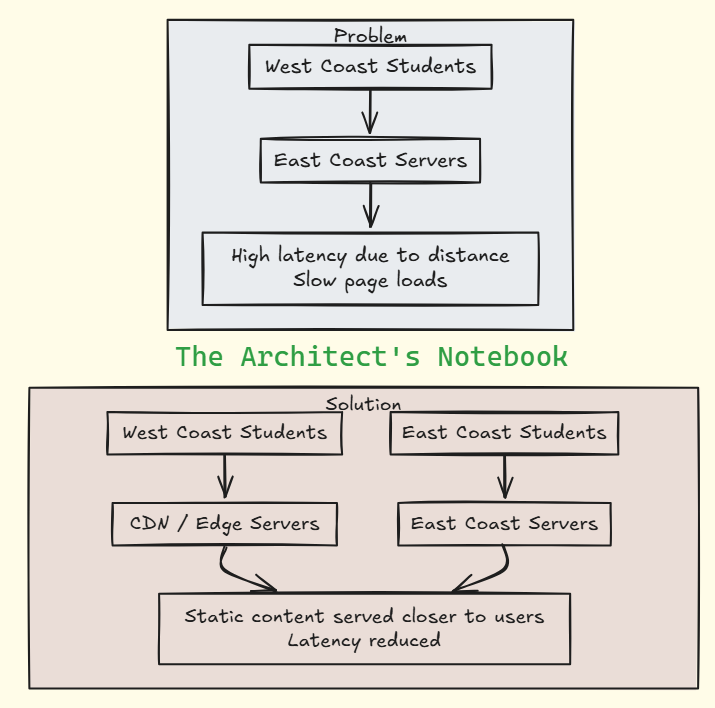
The architecture was becoming more complex, but each addition solved a real problem affecting hundreds of thousands of users. The team was learning a crucial lesson: scaling wasn't just about handling more users - it was about maintaining a great experience as the user base exploded.
TL;DR
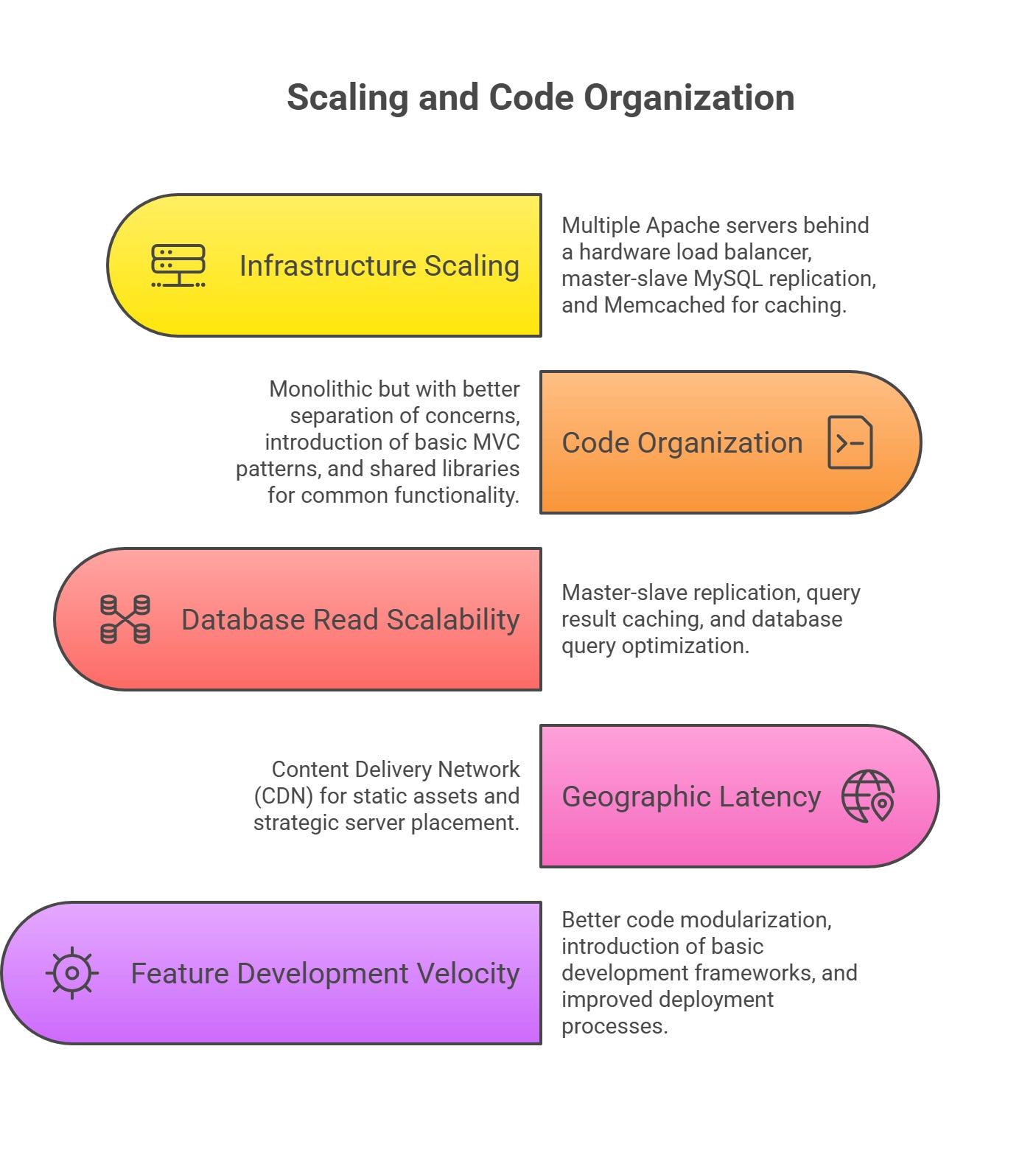
Infrastructure Scaling:
Web Tier: Multiple Apache servers behind a hardware load balancer
Database Tier: Master-slave MySQL replication
Caching Layer: Introduction of Memcached for session and query caching
Code Organization:
Still monolithic but with better separation of concerns
Introduction of basic MVC patterns
Shared libraries for common functionality
Challenge 1: Database Read Scalability The single MySQL master couldn't handle the read load from growing user interactions.
Solution Implemented:
Master-slave replication with read queries distributed to slaves
Query result caching in Memcached
Database query optimization and indexing improvements
Challenge 2: Geographic Latency Users from distant locations experienced slow page loads.
Solution Implemented:
Content Delivery Network (CDN) for static assets
Strategic server placement on the East and West coasts
Challenge 3: Feature Development Velocity Adding new features became increasingly complex due to tight coupling.
Solution Implemented:
Better code modularization
Introduction of basic development frameworks
Improved deployment processes
Conclusion
Facebook’s journey in the early days was defined by rapid growth, urgent crises, and creative engineering solutions. From the initial LAMP stack serving a few thousand college students to the first major database sharding and CDN implementations, every decision was shaped by necessity. These early challenges - managing exploding friend networks, scaling the monolithic application, and delivering content across geographies, laid the foundation for what would become a globally distributed system.
In the next part, we’ll explore how Facebook opened its doors to the public, faced real-world scaling challenges, and evolved its architecture further to support millions of users worldwide. You’ll see how the lessons from the college-era infrastructure informed the strategies that allowed Facebook to grow without breaking.
Linux is an open-source, Unix-like operating system kernel developed by Linus Torvalds in 1991. It powers a wide range of devices including servers, desktops, smartphones, and embedded systems. Linux is known for its stability, flexibility, and strong security, and is distributed in various "distros" like Ubuntu, Fedora, and Debian. It is freely available, highly customizable, and widely used globally.
Apache web server is a free, open-source software developed by the Apache Software Foundation that enables websites to serve content over the internet using HTTP and HTTPS protocols. It is highly modular, customizable, and supports dynamic sites with technologies like PHP, Python, and database integration. Apache is known for reliability, scalability, virtual hosting, robust security features, and cross-platform compatibility.
MySQL is an open-source relational database management system (RDBMS) that uses Structured Query Language (SQL) to manage and manipulate data. It is popular for its speed, reliability, scalability, and security features, powering countless web applications from small blogs to large enterprise systems. MySQL supports data storage in tables, ACID compliance, replication, and works across various platforms including Linux, Windows, and macOS.
PHP is an open-source, server-side scripting language specifically designed for web development and can be embedded into HTML. It powers dynamic web pages, handles user forms, sessions, and database interactions. Known for its simplicity, efficiency, and cross-platform compatibility, PHP supports object-oriented features and integrates seamlessly with technologies like MySQL and Apache. It is extensively used for building everything from small websites to complex content management systems.
Connection pooling is a technique used in database management to optimize resource usage and improve performance. It maintains a cache (pool) of reusable, open database connections that client applications can borrow when needed, rather than opening and closing new connections for each request. This reduces the overhead associated with establishing new connections, speeds up queries, and helps applications scale efficiently especially under heavy load.
Database query optimization is the process of improving the efficiency and performance of database query executions. It involves techniques like using indexes wisely to speed data retrieval, avoiding SELECT * to fetch only necessary columns, writing efficient WHERE clauses to limit rows, choosing appropriate join types, and minimizing complex subqueries. The goal is to reduce runtime, resource consumption, and response times for faster, cost-effective data access and better application performance.