

Ep #36: Inside DynamoDB — Part 4: The SSD Advantage & MVCC
Unlocking Speed and Concurrency at Scale

Ep #36: Breaking the complex System Design Components – Free Post
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Sep 9, 2025 · Free Post ·
Recap of What We’ve Learned So Far
Part 1: The Origins of DynamoDB
Why DynamoDB was created, its core philosophy, and how it fits into modern distributed system design.
Part 2: Core Concepts & Building Blocks
Understanding Tables, Partitions, and how data distribution works.
How DynamoDB balances consistency, availability, and partition tolerance.
Part 3: Modeling Data the Right Way
Deep dive into Tables, Partition Keys, and Sort Keys.
Attributes & supported data types.
Principles of single-table design for multi-entity apps.
Common schema pitfalls and how to avoid them.
⚡ Why This Part Matters in Your System Design Journey
Every architect knows the symptoms of slow queries and messy concurrency but few understand the root design choices that make databases fast and safe at scale. DynamoDB’s adoption of SSDs and Multi-Version Concurrency Control (MVCC) is not just an implementation detail, it’s a masterclass in how hardware innovation and concurrency theory converge to power real-world systems.
In this part, you’ll uncover:
How SSDs redefined performance economics for databases.
Why DynamoDB’s storage architecture goes beyond “just using SSDs.”
The concurrency problems MVCC solves, and why it matters in distributed systems.
The practical benefits of these design decisions in production environments.
By the end, you won’t just know what DynamoDB does, you’ll understand the why behind its architectural edge, giving you principles you can carry into any large-scale system design.
Now let’s begin:
DynamoDB Architecture & Storage Model: Deep Dive
What is DynamoDB?
Amazon DynamoDB is a NoSQL database service designed for high performance, scalability, and reliability. It’s used for applications that need to handle massive amounts of data with very fast response times, like e-commerce websites, gaming platforms, or mobile apps. DynamoDB’s architecture is built to make sure it can process requests quickly, even when millions of users are accessing it at the same time.
The key to DynamoDB’s speed and efficiency is its use of Solid State Drives (SSDs) for storage and MVCC to handle concurrency. Let’s dive into why SSDs are so important and how DynamoDB uses them.
Why SSDs? The Speed Revolution
Imagine you’re trying to find a specific book in a huge library. If the library uses an old system where a librarian has to physically walk to a shelf, pick up the book, and bring it to you, it takes time. This is like a traditional Hard Disk Drive (HDD). HDDs have spinning disks and mechanical arms that move to find data, which makes them slower.
Now, imagine a super-smart assistant who instantly knows where every book is and hands it to you in a split second. This is like a Solid State Drive (SSD). SSDs store data electronically, with no moving parts, so they’re much faster at accessing data.
HDD vs. SSD Performance Comparison
Here’s a simple comparison to show why SSDs are better:

Why this matters: SSDs are 100-200 times faster than HDDs for finding and reading data. This speed is critical for applications like online shopping or gaming, where users expect instant responses.
If you want to unlock even more in-depth insights, we have a series of deep dives into modern technologies, each spread across multiple parts exclusively for premium members. These guides are designed to give you practical, architect-level understanding that you can apply directly in real-world systems.
If you find these deep dives valuable for your system design and engineering journey, consider joining our paid membership to access the full library of premium content.
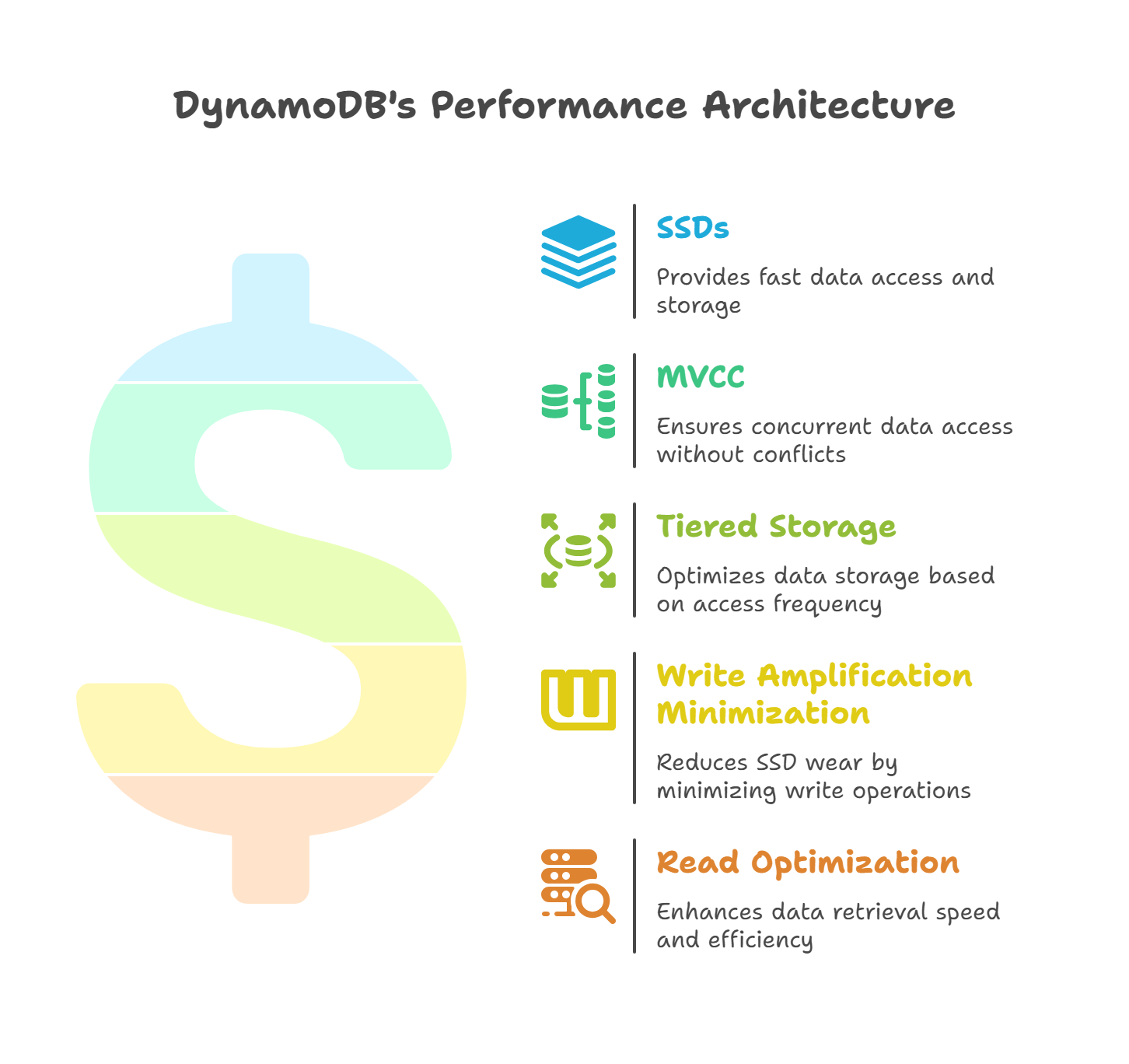
DynamoDB’s SSD Architecture Design
DynamoDB uses SSDs for everything - not just the main storage but also backups, indexes, and logs. This all-SSD design ensures that every part of the system is fast and reliable.
1. All-SSD Infrastructure
DynamoDB stores all its data on SSDs, which are split into different types based on their role:
Primary Storage: Uses super-fast NVMe SSDs1 (a high-performance type of SSD) to store the data users access most often, like recent orders or current game sessions.
Backup Storage: Even backups are stored on SSDs, so restoring data in case of a failure is quick.
Index Storage: Indexes (like shortcuts to find data faster e.g. Global and Local Secondary Indexes2) are stored on SSDs for quick lookups.
Log Storage: Write-ahead logs3 (records of changes to the database) are also on SSDs, ensuring fast and reliable updates.
2. SSD Optimization Strategies
SSDs are fast, but they have a limitation: they can wear out after many write operations (when data is saved to the drive). DynamoDB uses smart techniques to make SSDs last longer and perform better.
2.1 Write Amplification Minimization
Problem: In traditional databases, updating a single piece of data (like changing a user’s email) might require rewriting a large chunk of data, which wears out SSDs faster.
DynamoDB’s Solution: DynamoDB only writes the changed data (e.g., just the new email), not the entire record. This reduces the number of writes, making SSDs last longer and keeping operations fast.
Example:
Traditional Database:

DynamoDB:

2.2 Read Optimization
DynamoDB is designed to take full advantage of SSDs’ speed for reading data:
Sequential Reads: Reading large chunks of data in order (like a list of orders) can achieve speeds of over 500 MB/s.
Random Reads: Accessing scattered data (like looking up a specific user’s profile) supports over 100,000 IOPS (Input/Output Operations Per Second), meaning it can handle thousands of requests at once.
Parallel Access: DynamoDB uses multiple SSD channels at the same time, so it can process many requests simultaneously without slowing down.
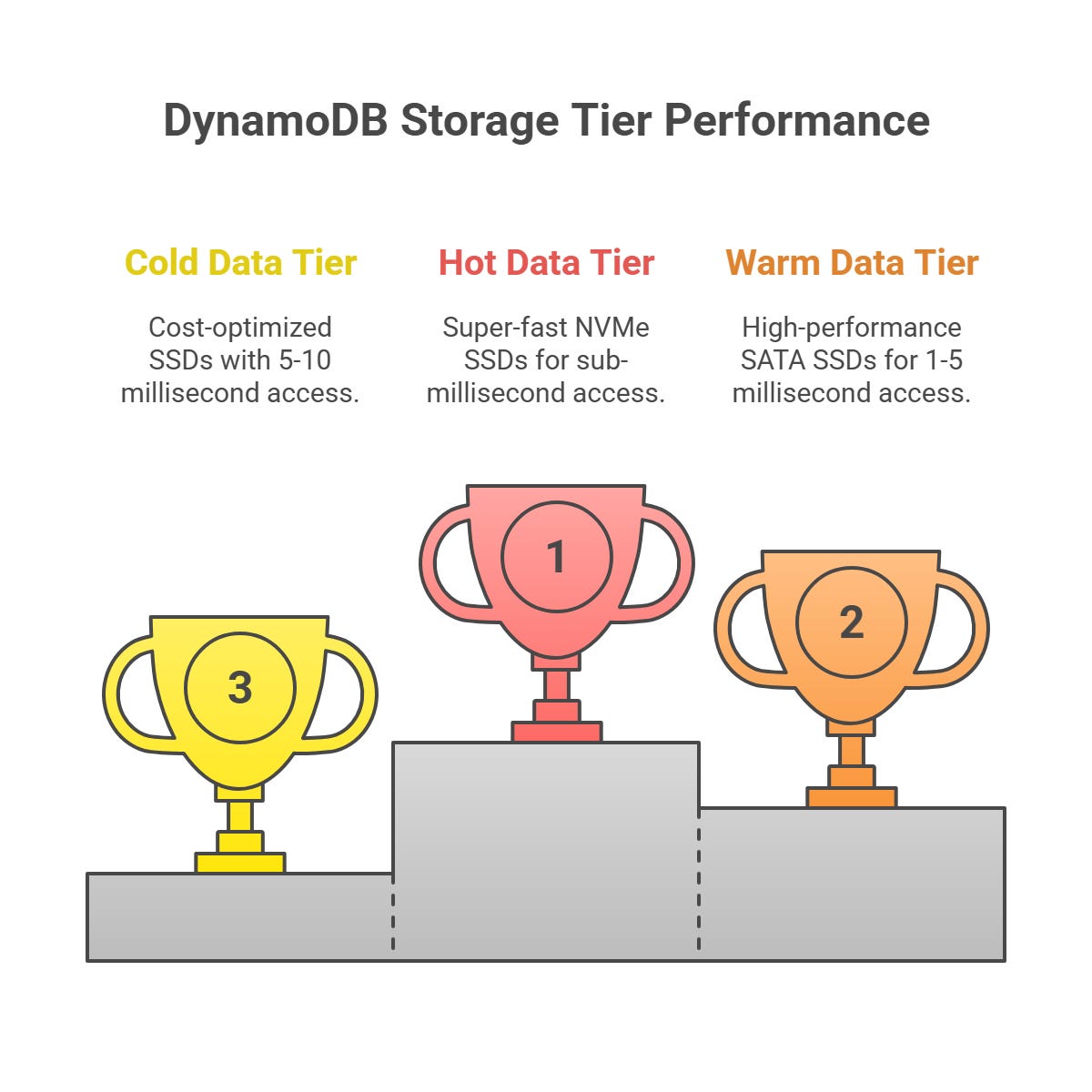
3. Tiered Storage Architecture
Not all data needs to be accessed at the same speed. DynamoDB organizes data into three tiers based on how often it’s used, with each tier using a different type of SSD to balance speed and cost.
3.1 Hot Data Tier (Primary SSDs)
What it stores: Data accessed frequently, like the last 30 days of user activity (e.g., recent orders, active shopping carts, or live game sessions).
Characteristics:
Uses super-fast NVMe SSDs.
Access times are sub-millisecond (less than 1 millisecond).
Most expensive per GB because of high performance.
Example: When you add an item to your cart on Amazon, that data is stored in the hot tier for instant access.
3.2 Warm Data Tier (Standard SSDs)
What it stores: Data accessed less often, like user profiles, order history from the past year, or product catalogs.
Characteristics:
Uses high-performance SATA SSDs4.
Access times are 1-5 milliseconds.
Less expensive than the hot tier but still fast.
Example: When you check your order history from six months ago, it’s retrieved from the warm tier.
3.3 Cold Data Tier (Optimized SSDs)
What it stores: Rarely accessed data, like archived transactions or old logs kept for compliance.
Characteristics:
Uses cost-optimized SSDs with data compression to save space.
Access times are 5-10 milliseconds.
Cheapest per GB, ideal for data that’s rarely needed.
Example: If a company needs to retrieve transaction data from two years ago for an audit, it’s pulled from the cold tier.
SSD Performance Benefits in Real Applications
DynamoDB’s SSD-based architecture shines in real-world scenarios where speed and scalability are critical. Let’s look at two examples:
1. E-commerce During Black Friday
Scenario: Millions of shoppers are browsing, adding items to carts, and checking out at the same time.
Traditional Database with HDDs:
With 1,000 users, page load times can take 15-30 seconds because HDDs struggle with many simultaneous requests.
The database becomes a bottleneck, causing timeouts and frustrated users who abandon their carts.
DynamoDB with SSDs:
Handles 1,000,000+ concurrent users with response times of less than 10 milliseconds.
Scales smoothly, so performance stays consistent even during massive traffic spikes.
Shoppers get a fast, seamless experience, increasing sales.
2. Gaming Leaderboards
Scenario: 10 million players are checking their ranks on a global leaderboard at the same time.
HDD-based System:
Each lookup requires mechanical movement, slowing down as more users access the system.
Performance drops significantly during peak times, making the leaderboard unusable.
DynamoDB SSD System:
All data is accessible in parallel, with sub-10ms response times for each request.
Performance scales linearly, meaning it stays fast even as demand grows.
Players get instant updates, keeping the gaming experience smooth.
TL;DR
Why SSDs? SSDs are much faster than HDDs because they have no moving parts, enabling instant data access.
DynamoDB’s SSD Design: Uses SSDs for all storage (primary, backups, indexes, logs) and optimizes them to reduce wear and maximize speed.
Tiered Storage: Organizes data into hot, warm, and cold tiers to balance speed and cost, ensuring fast access to frequently used data and cost savings for rarely accessed data.
Real-World Impact: SSDs enable DynamoDB to handle millions of users with lightning-fast response times, making it ideal for high-traffic applications like e-commerce and gaming.
By using SSDs and smart optimization techniques, DynamoDB delivers consistent, fast performance, even under heavy loads, making it a go-to choice for modern applications.
These architecture deep dives aren’t just stories of big tech systems, they’re lessons in thinking like an engineer and an architect. By studying DynamoDB, S3, Facebook, and more, you’ll learn how real-world problems were solved at scale and how those lessons apply to your own work. In the coming weeks, we’ll explore more architectures. If you find these valuable for your growth, consider becoming a paid member to support and learn deeper.
Multi-Version Concurrency Control (MVCC)
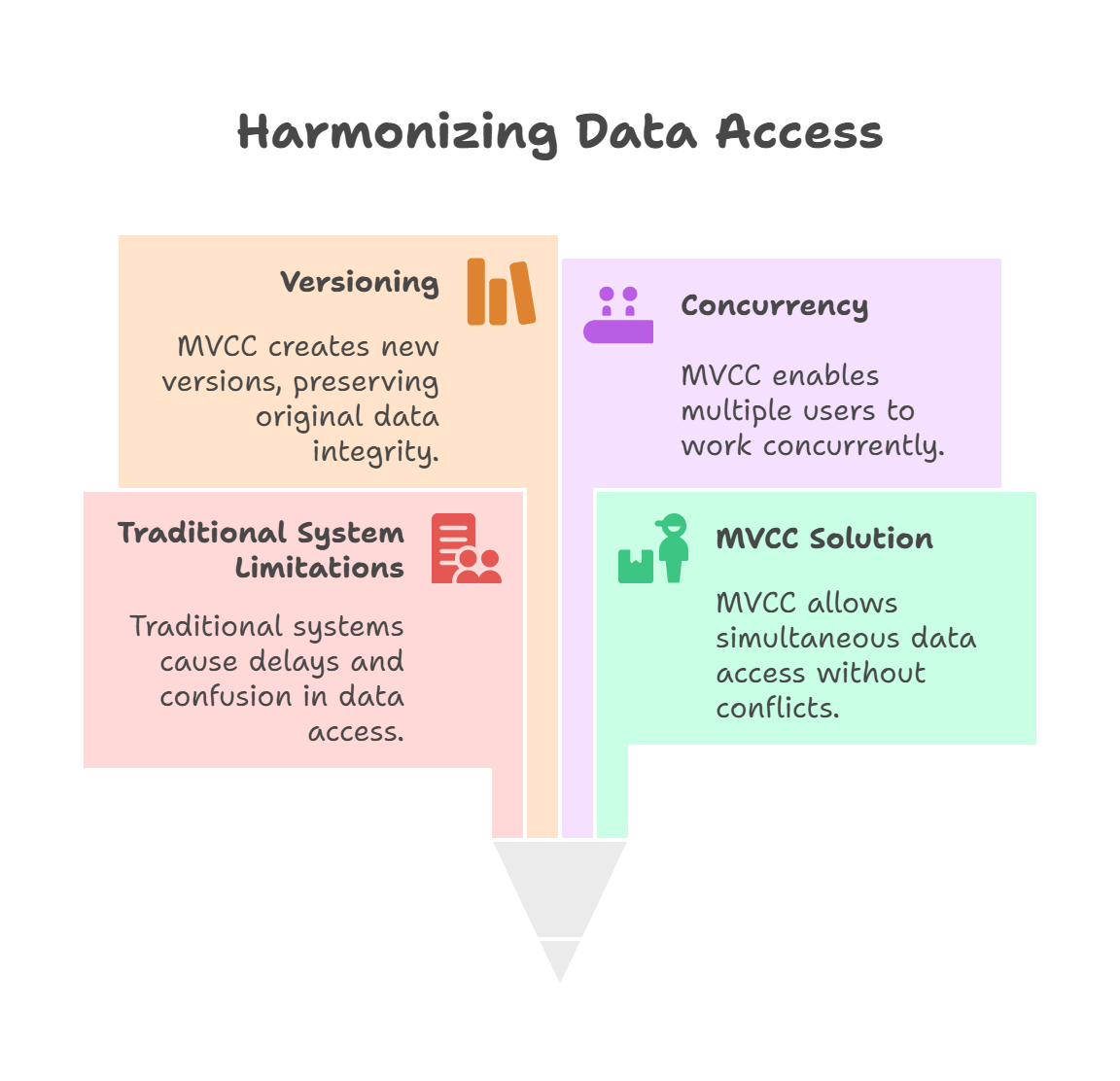
What is MVCC? Understanding MVCC: Time Travel for Databases
Imagine a library where multiple people want to read or edit the same book. In a traditional system, if one person is reading the book, everyone else has to wait. If someone wants to edit the book, they overwrite it, and others can’t see the original version anymore. This creates delays and confusion.
MVCC (Multi-Version Concurrency Control) is like giving each person their own copy of the book at a specific point in time. If someone edits the book, a new version is created, but the original version stays available for others to read. This way, everyone can work at the same time without waiting or seeing unexpected changes. In DynamoDB, MVCC lets multiple users read and write data simultaneously without conflicts, keeping everything fast and consistent.
The Concurrency Problem MVCC Solves
Concurrency means multiple users or processes accessing the same data at the same time. Without a good system to manage this, problems arise, like delays or incorrect data.
Traditional Locking Approach (Without MVCC)
In a traditional database, if one user is reading or writing data, others have to wait. This is called locking. Here’s how it works:
Time 0: User A starts reading a customer’s record (e.g., checking their balance).
Time 1: User B wants to update the same record (e.g., making a purchase). They’re blocked and must wait for User A to finish.
Time 2: User C wants to read the same record. They’re also blocked, waiting for both User A and User B.
Time 3: User A finishes, so User B can start updating.
Time 4: User B finishes, so User C can finally read.
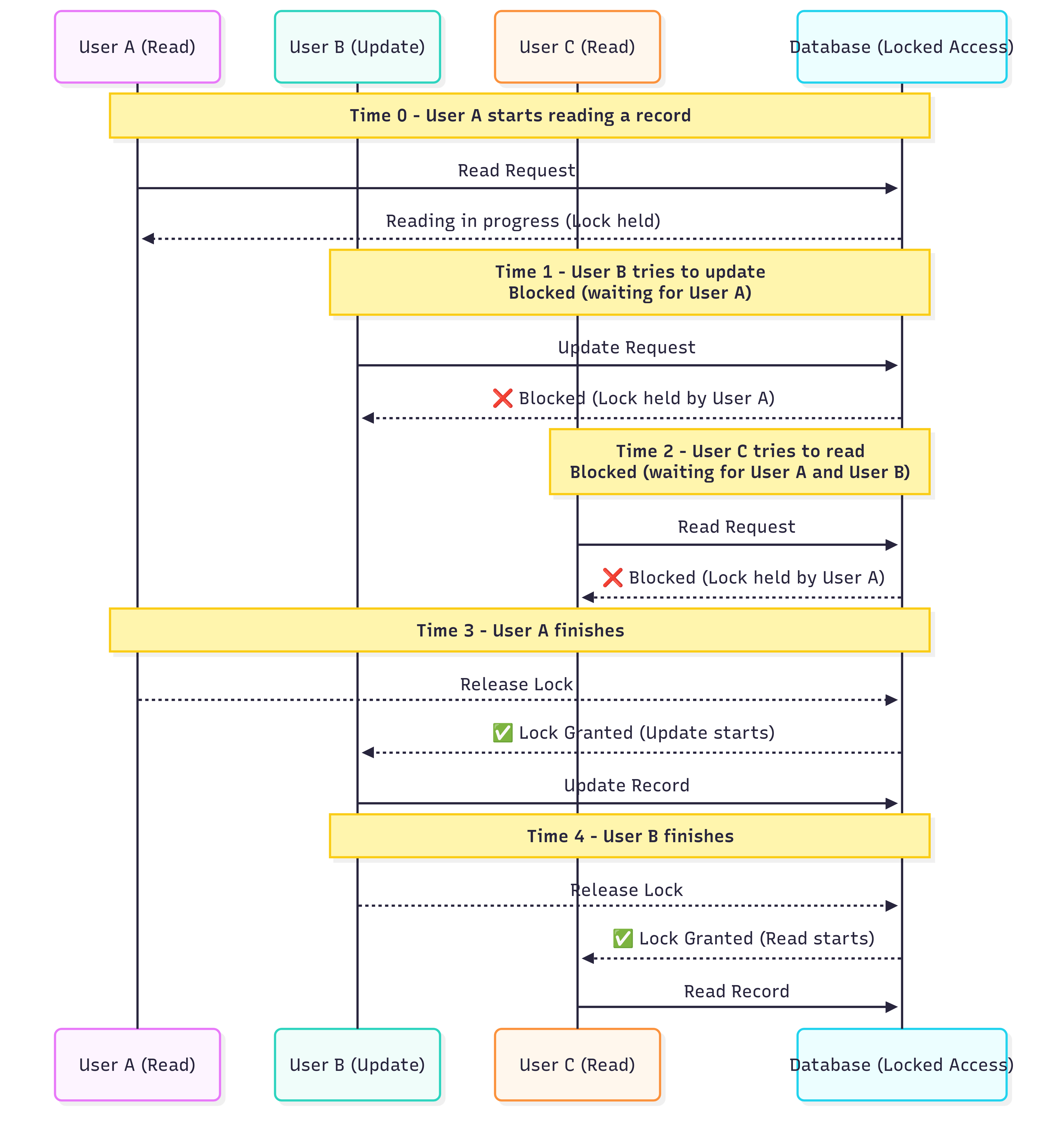
Problem: Everyone is waiting in line, which slows things down, especially when many users are involved. This is bad for apps like online banking or e-commerce, where speed is critical.
MVCC Approach (With DynamoDB)
MVCC avoids locking by creating multiple versions of the data. Here’s how it works:
Time 0: User A starts reading a customer’s record (Version 1, e.g., balance is $1000).
Time 1: User B updates the same record (e.g., makes a purchase, creating Version 2 with balance $950). User A is unaffected and keeps reading Version 1.
Time 2: User C reads the record and gets the latest version (Version 2, balance $950).
Time 3: User A finishes reading Version 1, seeing the consistent balance of $1000.
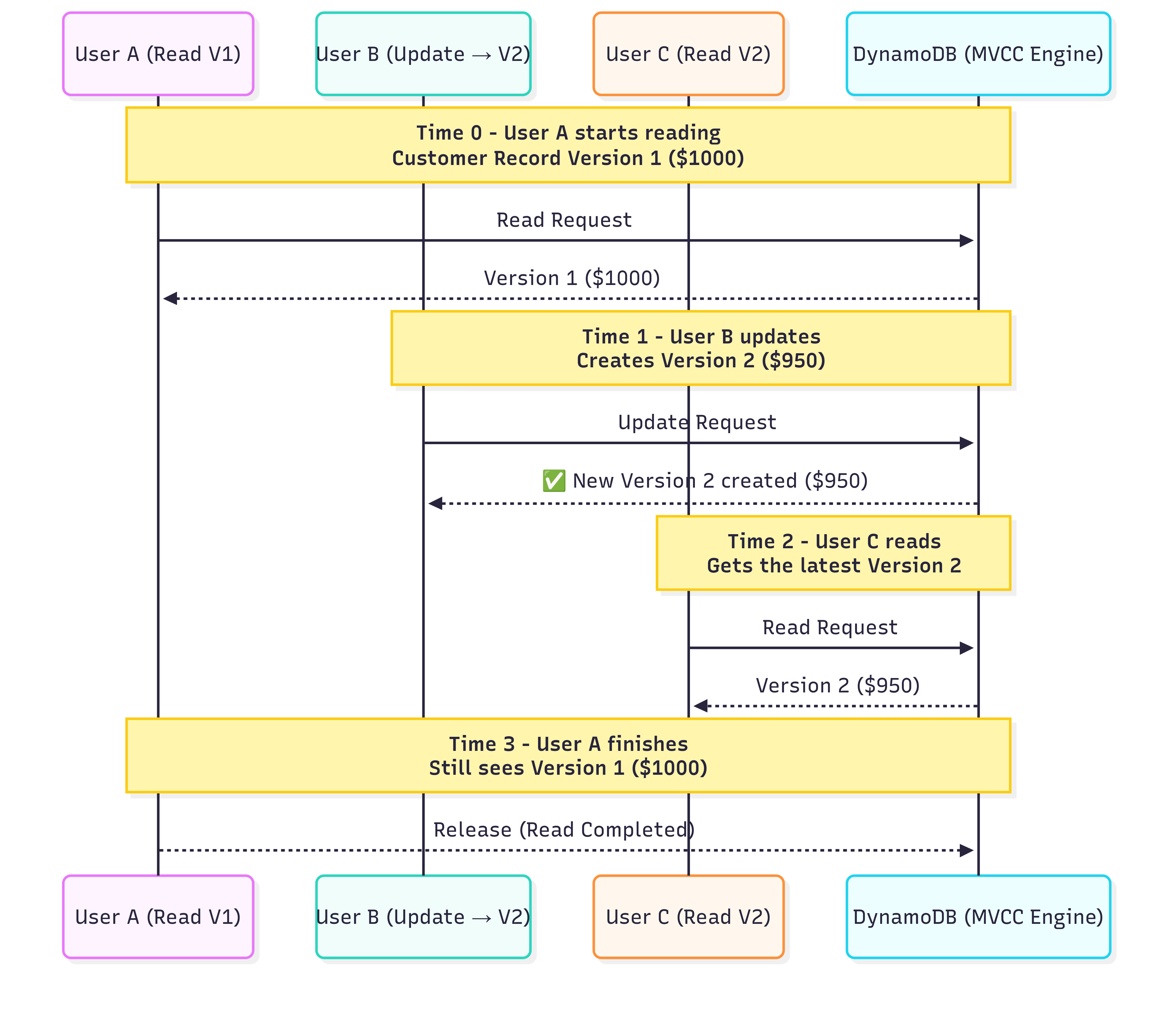
Result: Everyone works at the same time—no waiting, no delays. This makes DynamoDB super fast and efficient, even with millions of users.
How DynamoDB Implements MVCC
DynamoDB uses MVCC to manage multiple versions of data, ensuring that reads and writes happen smoothly without conflicts. Here’s how it works, step by step:
1. Version Timestamping
Every item (like a row in a table) in DynamoDB has hidden metadata that tracks its version. You don’t see this metadata when you query data, but DynamoDB uses it internally to manage versions.
What you see (simplified view):
{
"UserID": "user123",
"Name": "John Doe",
"Email": "john@example.com",
"Balance": 1000.00
}What DynamoDB stores internally:
{
"UserID": "user123",
"Name": "John Doe",
"Email": "john@example.com",
"Balance": 1000.00,
"_version": 147,
"_created_time": "2024-01-15T10:30:00.123Z",
"_modified_time": "2024-01-15T14:22:17.456Z",
"_transaction_id": "txn_789xyz"
}_version: A number that tracks which version of the item this is.
_created_time and _modified_time: Timestamps showing when the item was created or last updated.
_transaction_id: A unique ID for the transaction that created or modified the item.
This metadata lets DynamoDB keep track of different versions of the same item.
2. Version Chain Management
DynamoDB keeps a chain of versions for each item, showing how it has changed over time. For example:
Item Evolution Over Time:
Version 1 (10:00 AM):
{ "UserID": "user123", "Balance": 1000.00 }Version 2 (11:00 AM):
{ "UserID": "user123", "Balance": 950.00 }(after a $50 purchase)Version 3 (12:00 PM):
{ "UserID": "user123", "Balance": 1200.00 }(after a $250 deposit)Version 4 (01:00 PM):
{ "UserID": "user123", "Balance": 1150.00 }(after another $50 purchase)
When users read data, they might see different versions depending on when they started their operation. For example:
If you’re still with me (reading this far), I know it’s a long article. To lighten your mood, let me tell you a joke:
Why did the microservice break up with the monolith?
Because it wanted more independence… but ended up with too many dependencies😂!
A user who started reading at 10:30 AM sees Version 1 ($1000).
A user who starts reading at 12:30 PM sees Version 3 ($1200).
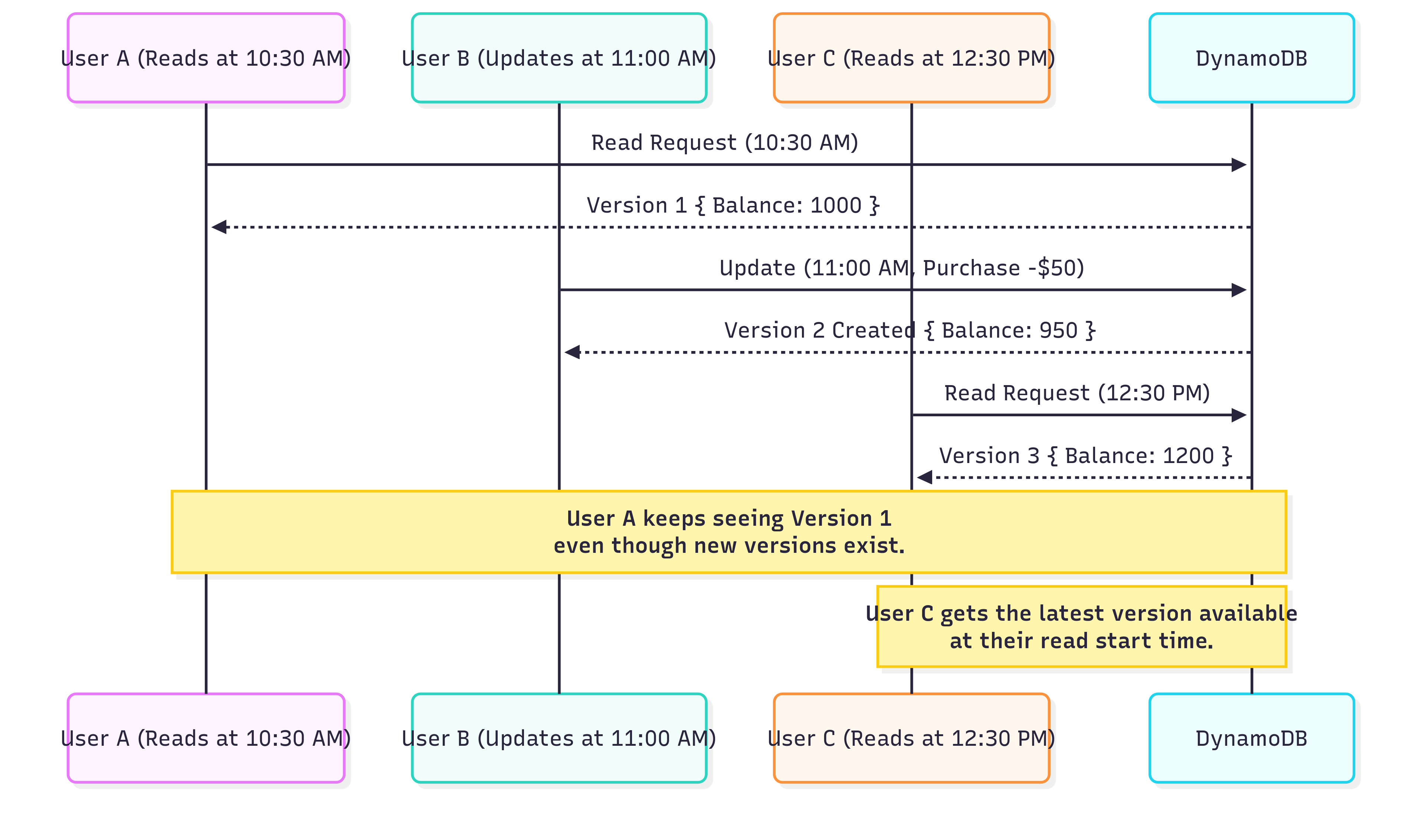
This ensures that each user gets a consistent view of the data, even if it’s being updated by others.
3. Garbage Collection of Old Versions
DynamoDB doesn’t keep old versions forever, as that would use too much storage. It has a garbage collection process to clean up versions that are no longer needed.
Version Cleanup Strategy:
Keep recent versions: Versions needed by active transactions (e.g., a user still reading Version 1) are kept.
Remove old versions: Versions that no one is using anymore are deleted.
Keep versions for recovery: Some versions are kept for point-in-time recovery (a feature that lets you restore the database to a specific moment).
Automatic cleanup: DynamoDB handles this in the background, so you don’t need to worry about it.
Example Timeline:
Versions 1 and 2: Cleaned up because no one is reading them anymore.
Version 3: Kept because a transaction (e.g., a report) is still reading it.
Version 4: Kept as the current, latest version.
This keeps storage usage efficient while ensuring data consistency.
MVCC Benefits in Practice
MVCC makes DynamoDB powerful for real-world applications. Here are three key benefits, with examples:
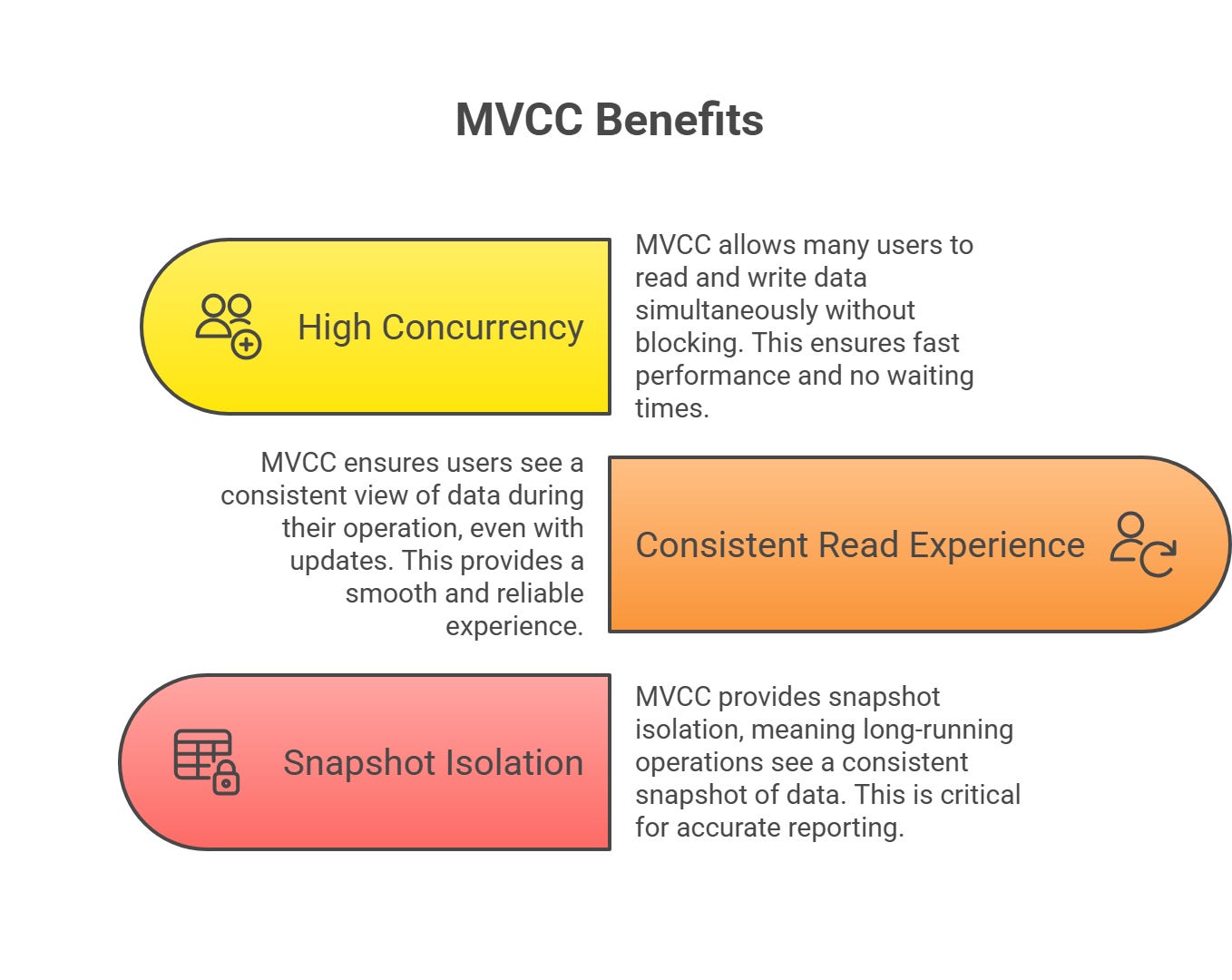
1. High Concurrency Without Blocking
MVCC allows many users to read and write data at the same time without waiting.
Real-World Example: Banking Application
Scenario: A bank has:
1,000 customers checking their balances.
50 customers making deposits or withdrawals.
10 batch jobs calculating interest rates.
Without MVCC: Operations would queue up, causing delays. Customers might wait seconds or minutes to see their balances.
With MVCC: All 1,060 operations happen at the same time. Each user or job gets its own version of the data, so there’s no waiting, and performance stays fast.
2. Consistent Read Experience
MVCC ensures that users see a consistent view of the data during their operation, even if someone else is updating it.
Example: User Transaction Flow
Step 1: You open your bank account dashboard and see a balance of $1,000.
Step 2: While you’re looking, your spouse makes a $200 purchase, updating the balance to $800.
Step 3: You keep navigating the dashboard and still see $1,000, because MVCC gives you a consistent view based on when you started.
Step 4: You refresh the page, and now you see the updated balance of $800.
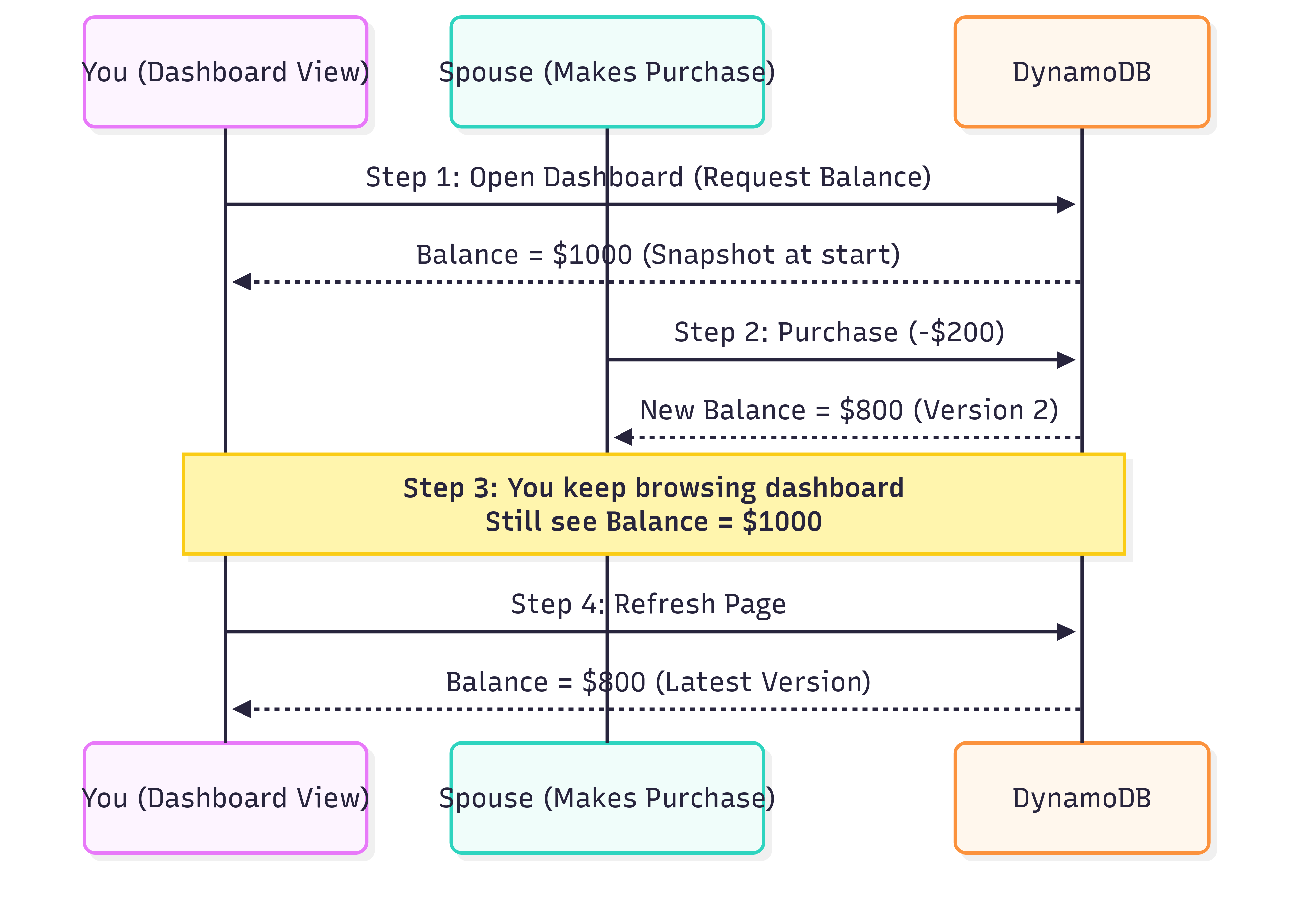
Benefit: You don’t see confusing mid-transaction changes, making the experience smooth and reliable.
3. Snapshot Isolation
MVCC provides snapshot isolation, meaning long-running operations (like reports) see a consistent “snapshot” of the data from when they started, unaffected by later changes.
Example: Long-Running Report Generation
Start Time (9:00 AM): A report starts processing customer data (e.g., total sales for the day).
9:30 AM: A customer makes a purchase, creating a new version of their data.
10:00 AM: Another customer updates their profile, creating another version.
10:30 AM: The report finishes, using the data as it was at 9:00 AM.
Result: The report shows a consistent view of the data from 9:00 AM, ignoring changes made after that. This is critical for accurate reporting in businesses like e-commerce or finance.
MVCC Performance Characteristics
MVCC is designed to be fast and efficient, even with multiple versions of data. Here’s how DynamoDB optimizes performance:
Memory Usage
DynamoDB is smart about storing versions to save space:
Only store changes: If you update just the email field, DynamoDB stores only the new email, not the entire item.
Shared storage: Unchanged data (like the user’s name or ID) is shared across versions to avoid duplication.
Compression: Version chains are compressed to reduce storage needs.
Background cleanup: Old versions are automatically removed when no longer needed.
Example:
Original item: 1 KB (e.g., user ID, name, email, balance).
Update only email: Adds ~50 bytes (not another 1 KB).
Update only balance: Adds ~20 bytes.
Total storage: ~1.07 KB for all versions, not 3 KB.
This keeps storage efficient, even with many versions.
Read Performance
DynamoDB ensures fast access to versions:
Latest version: Accessed directly in less than 1 millisecond.
Historical version: Found using a hash table lookup in 1-2 milliseconds.
Point-in-time query: Found using a binary search in 2-3 milliseconds.
For most workloads, reads stay super fast (sub-millisecond), even with MVCC managing multiple versions.

TL;DR
What is MVCC? A system that creates multiple versions of data, allowing users to read and write simultaneously without waiting or conflicts.
How DynamoDB Uses MVCC:
Adds version metadata (like timestamps) to track changes.
Maintains a version chain to store the history of an item.
Cleans up old versions automatically to save space.
Benefits:
High Concurrency: Many users can work at once without delays.
Consistent Reads: Users see a stable view of data during their operation.
Snapshot Isolation: Long-running tasks (like reports) use a consistent data snapshot.
Performance: MVCC is optimized for speed (sub-millisecond reads) and storage efficiency (only changed data is stored).
MVCC makes DynamoDB ideal for apps with heavy traffic, like banking, e-commerce, or gaming, where speed, consistency, and scalability are critical.
✨Closing Thoughts for Part 4
Behind every “blazing fast” database claim lies a set of deliberate architectural bets. DynamoDB’s embrace of SSDs unlocked millisecond-level performance, while MVCC brought order to concurrent access in a distributed world. Together, these innovations form the invisible backbone of DynamoDB’s promise: speed and safety at scale.
But we’re not done yet.
🔮 Coming Up in Part 5:
We’ll go beyond single-node concerns into availability zones, multi-tenancy, and global reliability exploring how DynamoDB achieves resilience across regions while still maintaining its performance guarantees.
– Amit Raghuvanshi
Author, The Architect’s Notebook
Stay tuned 👀
NVMe SSDs (Non-Volatile Memory Express Solid-State Drives) are high-speed storage devices that use the NVMe protocol to connect directly to a computer’s CPU via the PCI Express (PCIe) bus. Designed specifically for flash-based storage, NVMe SSDs offer much lower latency and vastly higher data transfer rates compared to SATA or SAS SSDs. They deliver improved speed, parallelism, and efficiency for demanding applications in both consumer and enterprise environments.
In DynamoDB, Global and Local Secondary Indexes are mechanisms that enable more flexible querying beyond the base table’s primary key.
Global Secondary Index (GSI)
A GSI lets you specify a different partition key and optional sort key from those used in your base table, allowing queries on entirely different attributes.
GSIs are “global” because they can span all partitions and have their own read/write throughput settings independent from the base table.
GSIs can be added to a table at any time and are suitable for multi-access patterns across the dataset.
Local Secondary Index (LSI)
An LSI uses the same partition key as the base table but allows a different sort key. This enables alternate querying and sorting within the same partition.
LSIs are “local” because they are scoped to individual partitions, with a size limit (10 GB per partition key) and shared throughput settings with the base table.
LSIs must be defined when the table is created and update synchronously with base table data.
Both indexes improve query flexibility and performance but involve trade-offs in storage, throughput, and update complexity based on specific query needs.
Write-ahead logs (WALs) in DynamoDB are append-only logs that record all changes (writes, deletes, updates) before they’re applied to the database. Each partition in DynamoDB maintains WALs across its three replicas to ensure data durability and crash recovery. If a failure occurs, DynamoDB can quickly recover and replay operations from the WALs, restoring consistency. WALs are also periodically archived to Amazon S3 for enhanced durability (11 nines) and are crucial for point-in-time restores.
SATA SSDs (Serial Advanced Technology Attachment Solid-State Drives) are solid-state storage devices that use the SATA interface to connect to a computer’s motherboard. SATA SSDs replace older PATA drives and offer faster speeds, reliability, hot-swapping, and thinner cables, though they are generally slower than NVMe SSDs. They are widely used in desktops, laptops, and servers for improved performance and easy compatibility.