

Why Distributed Systems Fail - Part 1 (In One Diagram)
The Eight Fallacies that will crash your microservices

System Design Insight | One concept, clarified in 4 minutes
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ May 31, 2026 · Free Edition
🚨 Out Now: System Design Masterclass Volume 5
Before we dive into today’s deep dive, I am thrilled to announce that System Design Masterclass: Volume 5 - The Architecture of Distributed Counter is officially live!
This 400+ page guide tackles the brutal physics of the Write-Heavy Avalanche. We explore how to handle massive write contention, decoupling ingestion with Kafka firehoses, scaling with HyperLogLog approximations, building Lambda architectures, and federating active-active state globally using CRDTs.
Launch Week Offers:
Launch Discount: Grab it this week for 10% off the regular $39 price.
Infinity Pass Holders: Volume 5 has already been added to your library entirely for free.
Substack Members: Lifetime members get an exclusive 15% off, and Yearly members get 10% off (Please ping me for your promo codes).
Upgrade to Infinity: If you’ve purchased previous volumes and want to unlock the Infinity Pass, just reply to this email with your receipts. I’ll generate a custom discount to credit your past purchases toward the upgrade!
The Illusion of the Cloud
You did everything “right.”
You read the blogs. You broke your massive, clunky monolith into sleek, independent microservices. You deployed them to Kubernetes. You added an API Gateway. You looked at your architecture diagram and felt like a true Silicon Valley engineer.
And then, production went down at 2:00 AM.
Not because your code had a logic bug. Not because your database ran out of disk space. Production went down because Service A tried to talk to Service B, and nothing happened. No error, no response, just a hanging thread that eventually exhausted your connection pool and cascaded into a system-wide outage.
Welcome to the painful reality of distributed systems.
When you split a monolith, you trade the complexity of a single codebase for the complexity of a network. And networks are inherently hostile environments. Back in 1994, Peter Deutsch and his colleagues at Sun Microsystems documented the “8 Fallacies of Distributed Computing”. More than three decades later, these exact false assumptions are still taking down modern cloud-native applications.
Here is the entire problem of distributed systems, mapped out in a single diagram:
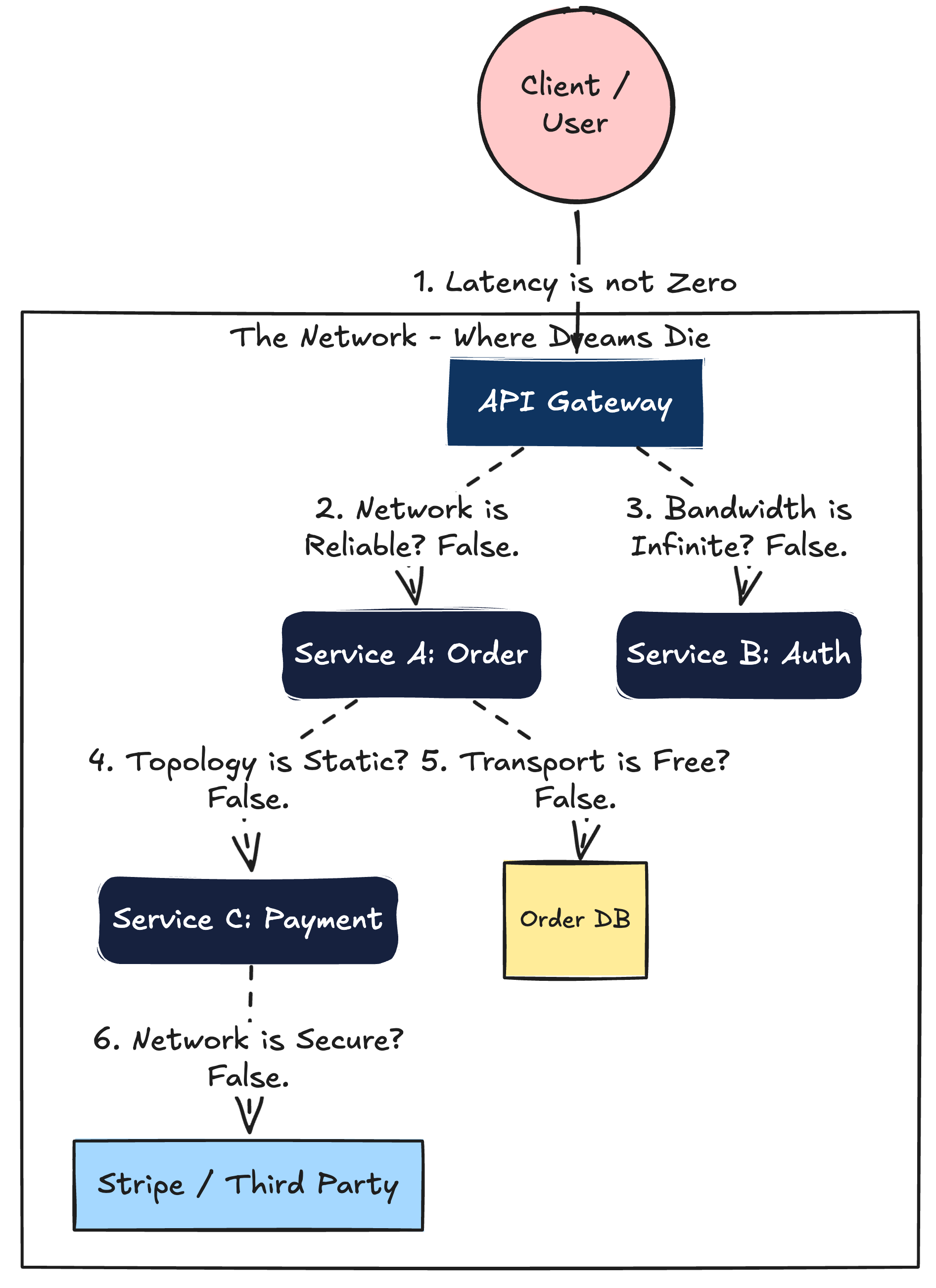
Breaking Down the Fallacies
Let’s look at the most dangerous lies we tell ourselves when designing microservices, and how they destroy our architecture.
1. “The Network is Reliable”
This is the deadliest trap. In a monolith, calling a function always works unless the server is completely dead. In a distributed system, a network call can fail because a router rebooted, a cable was bumped, or AWS had a micro-outage.
The Symptom: Infinite loading screens. Service A waits forever for Service B to reply.
The Architect’s Fix: Never make a synchronous network call without a Timeout and a Retry Policy. But beware—retries cause “Retry Storms” that DDOS your own systems. Always use Exponential Backoff and Jitter.
2. “Latency is Zero”
When fetching data from local memory, it takes nanoseconds. When fetching data across an AWS Availability Zone, it takes milliseconds. That is a 1,000,000x difference.
The Symptom: The “N+1 Query” nightmare. If your dashboard microservice makes 50 sequential HTTP calls to the User microservice to load a grid, a page that took 10ms in a monolith will now take 3 seconds.
The Architect’s Fix: You must design coarse-grained APIs. Stop requesting individual resources over the network. Batch your requests, use GraphQL, or implement data replication (CQRS) so the data is local when you need it.
3. “Bandwidth is Infinite”
Because we have gigabit fiber, we think payload size doesn’t matter. So, we serialize our data into massive JSON payloads filled with nested objects that the client doesn’t even need.
The Symptom: Network congestion and massive AWS data transfer bills. Serialization and deserialization of massive JSON strings start burning all your CPU cycles.
The Architect’s Fix: Use efficient binary protocols for internal service-to-service communication. Switch from REST/JSON to gRPC and Protocol Buffers. It compresses the payload and drastically reduces CPU overhead.
4. “Topology Doesn’t Change”
In the old days, you hardcoded an IP address because the server was a physical box that sat in a rack for five years. Today, your application lives in a Kubernetes Pod that might be destroyed and recreated on a different node three times a day.
The Symptom: “Connection Refused” errors after a routine deployment because the downstream service IP changed.
The Architect’s Fix: Service Discovery and DNS. You must use tools like Consul, or rely on Kubernetes’ internal DNS, and implement client-side load balancing to handle dynamic IP routing.
5. “Transport Cost is Zero”
Developers often forget that sending data across the wire costs money and hardware resources. You have to marshal the object to a string, push it through the TCP stack, encrypt it via TLS, send it, and reverse the process on the other side.
The Symptom: A microservice that does very little logic but consumes 4GB of RAM and 100% CPU, purely from handling HTTP connections and parsing JSON.
The Architect’s Fix: Keep chatty services together. If two services talk to each other 10,000 times a second, they shouldn’t be separate microservices. Merge them back together.
(Note: These are only the physical network fallacies. In Part 2 next week, we will break down the final three organizational fallacies—including the most dangerous assumption of all: that your internal network is secure.)
The Core Lesson: Defensive Architecture
If you want to survive distributed systems, you have to fundamentally change your mindset.
You must stop practicing “Happy Path Engineering.” You can no longer write code that assumes the database is available, the network is fast, and the downstream API is perfectly healthy.
You must practice Defensive Architecture.
Assume the network will drop packets.
Assume the third-party API will be down.
Assume the database will lock up.
Design your systems so that when—not if, but when—these failures occur, they are caught gracefully by Circuit Breakers, Fallback Caches, and Dead Letter Queues, rather than blowing up your entire production environment.
Building scalable systems isn’t about preventing failure. It is about containing it.
Until next time, The Architect’s Notebook
P.S. Mastering these concepts is the difference between a mid-level developer and a true Architect. If you are tired of guessing how to handle network partitions, consistency models, and global latency, I have compiled everything I know into my System Design Masterclass book series.
5 volumes are now live. Whether you need to understand the metal layer of infrastructure, or you are looking to master the architecture of global engagement, these books contain the definitive blueprints.
Volume 1 taught us Financial Correctness (Payments, Sagas, Idempotency).
Volume 2 taught us Extreme Contention (Inventory, Race Conditions).
Volume 3 taught us Absolute Truth (Ledgers, PACELC, Append-Only Logs).
Volume 4 taught us Read-Heavy Scale (Global Engagement, Fan-out, Feeds).
Volume 5 taught us Distributed-Counter (Youtube video views, Unique viewers).