

Ep #11: Understanding Eventual Consistency in Distributed Systems
How distributed systems maintain availability through relaxed consistency.

#11: Breaking the complex System Design Components
🎉 A Heartfelt Thank You to My First 500 Subscribers! 🎉
Before you dive into today’s article, I want to pause for a moment and say thank you.
We’ve just hit a milestone—500 subscribers—and I couldn’t be more grateful. Whether you’ve been here from the very beginning or just joined yesterday, you’re officially part of the first 500 who believed in this space, this voice, and this vision.
You’re not just a number on a list—you’re part of the foundation. And as this journey grows, I’ll always remember this early tribe that helped shape what’s next.
From the bottom of my heart—thank you for reading, sharing, and staying curious.
Now, on to the article…
Introduction to Consistency in System Design
In system design, consistency refers to the degree to which all nodes in a distributed system agree on the current state of data. It ensures that users see the same data regardless of which node they access. Distributed systems, which involve multiple nodes (servers) working together to store and process data, face challenges in maintaining consistency while ensuring availability and performance. Different consistency models balance these trade-offs in unique ways.
Types of Consistency Models
Strong Consistency: All nodes see the same data at the same time. After a write operation, all subsequent reads reflect that write. Example: Traditional relational databases using ACID transactions.
Eventual Consistency: Nodes may have different views of data temporarily, but all updates propagate to all nodes over time, ensuring eventual agreement. Example: Amazon DynamoDB, Apache Cassandra.
Causal Consistency: Operations that are causally related (e.g., a write followed by a read) are seen in the correct order, but unrelated operations may appear out of order.
Sequential Consistency: All operations appear to execute in some sequential order, and operations from each client are seen in the order they were issued.
Weak Consistency: No guarantees about when updates propagate, often requiring explicit synchronization by clients. Example: Caching systems with short-lived data.
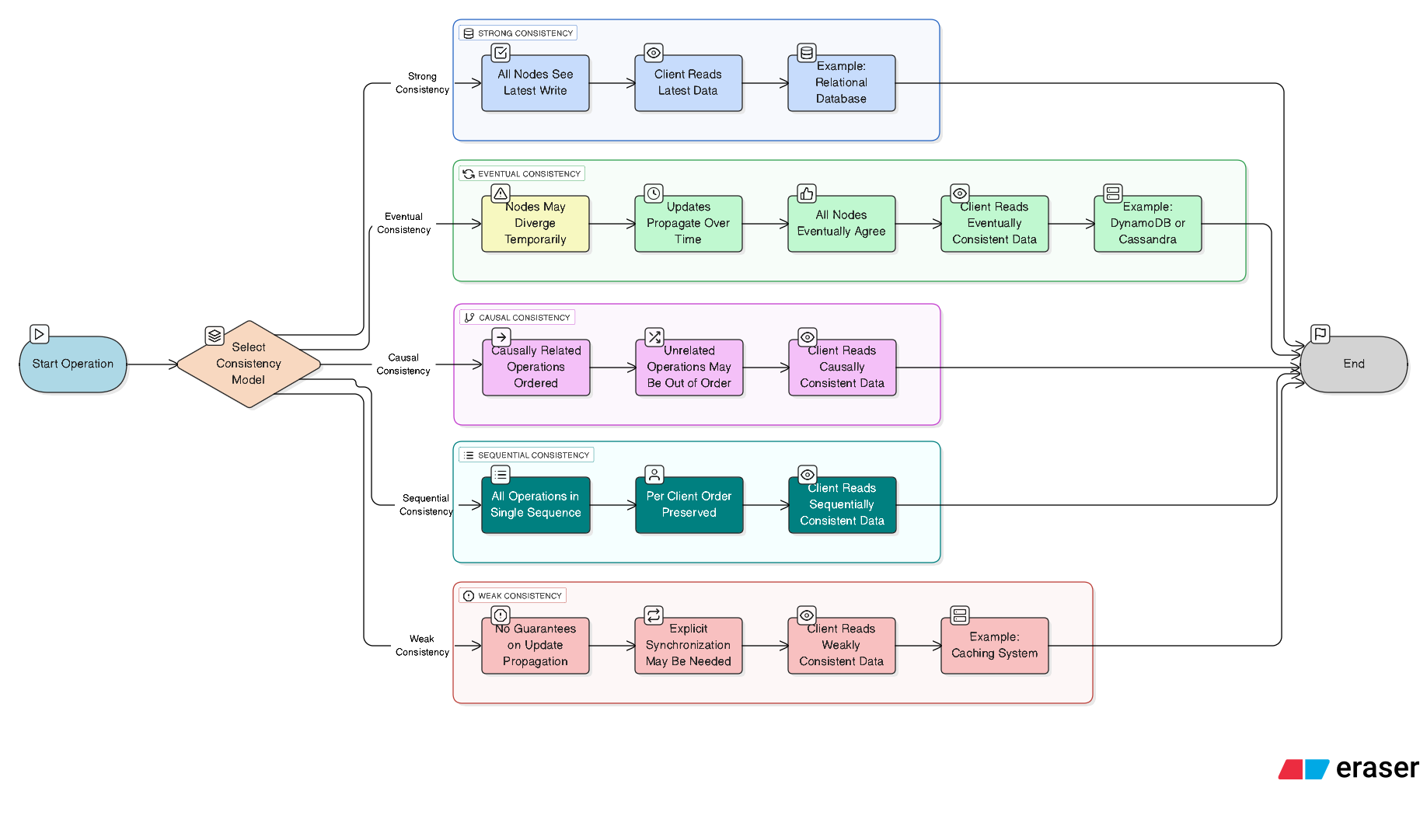
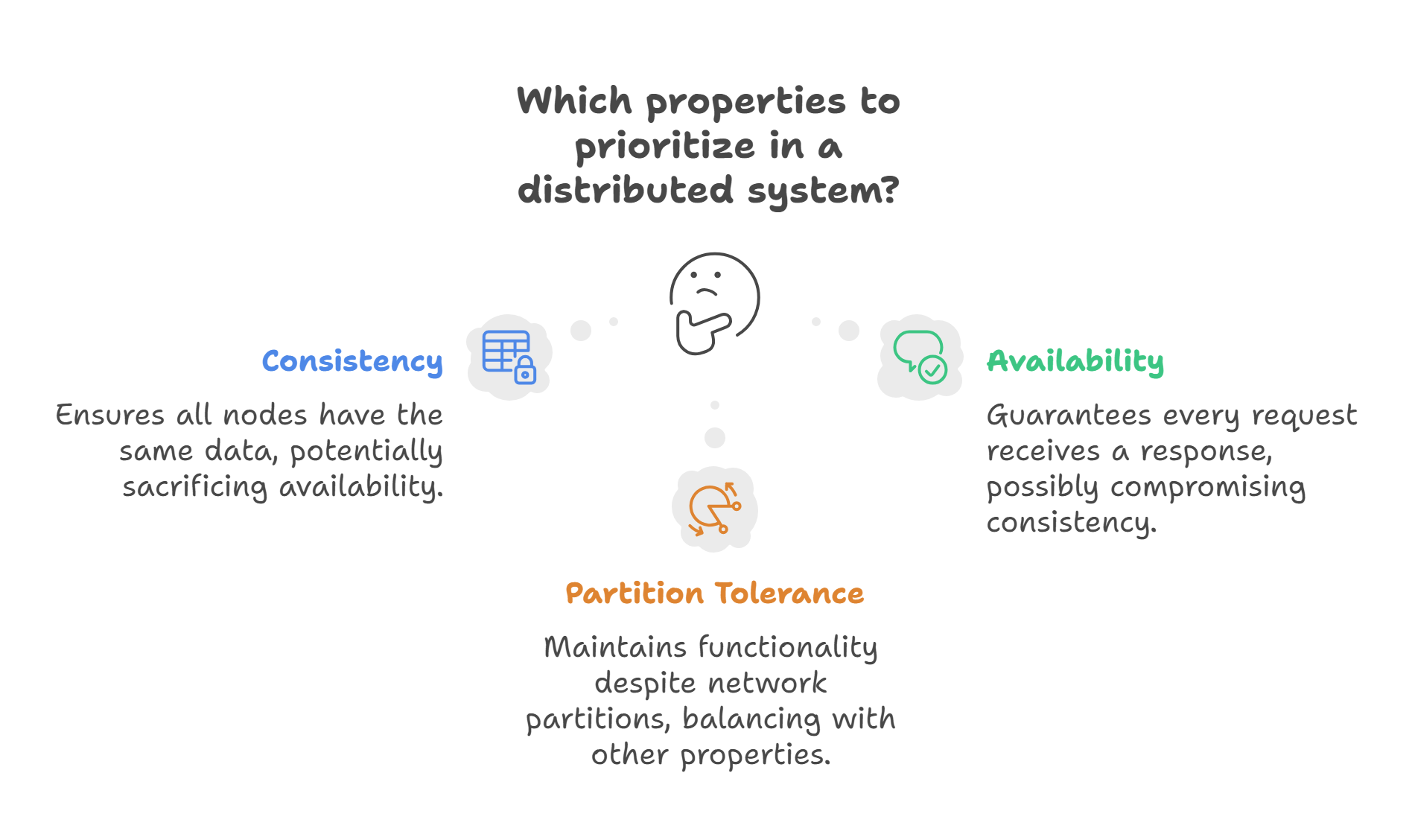
Each model balances the trade-offs between consistency, availability, and partition tolerance, as dictated by the CAP theorem. The CAP theorem states that a distributed system can only guarantee two out of three properties:
Consistency: All nodes have the same data.
Availability: Every request receives a response.
Partition Tolerance: The system continues to function despite network partitions.
Strong consistency often sacrifices availability, while relaxed consistency models like eventual consistency prioritize availability and partition tolerance.
What is Eventual Consistency?
Eventual consistency is a relaxed consistency model commonly used in distributed systems. It allows nodes to have temporary inconsistencies, meaning different nodes may hold different versions of data for a short period. However, given enough time and no new updates, all nodes will eventually converge to the same data state.
For example, if a user updates their profile on a social media platform, one server might process the update immediately, while others take a moment to catch up. Users accessing different servers might briefly see outdated data, but all servers will eventually reflect the updated profile.
Subscribe to get simplified System Design Concepts delivered straight to your inbox:
Key Characteristics of Eventual Consistency
Asynchronous Updates: Updates propagate to nodes in the background, not instantly.
Temporary Inconsistency: Reads may return stale data during propagation.
Eventual Convergence: All nodes will have the same data once updates are fully propagated, assuming no new writes occur.
Conflict Resolution: If multiple nodes receive conflicting updates, the system resolves them using mechanisms like timestamps, vector clocks, or application-specific logic.
Getting bored of this long post? Let’s lighten the mood with a joke:
Why don’t skeletons ever fight each other?
Because they just don’t have the guts. 😄
Why Use Eventual Consistency?
Eventual consistency is useful in distributed systems because it prioritizes availability and partition tolerance over immediate consistency, making it ideal for systems that need to handle high traffic, scale horizontally, or operate across geographically distributed nodes. Here’s why it’s valuable:
High Availability: By allowing nodes to process requests independently without waiting for all nodes to sync, eventual consistency ensures the system remains responsive even during network failures or partitions.
Improved Scalability: Systems can add more nodes without significant performance degradation, as nodes don’t need to coordinate synchronously for every update.
Low Latency: Writes and reads can occur locally on a node without waiting for global consensus, reducing response times.
Fault Tolerance: The system continues functioning even if some nodes are temporarily unavailable, as updates can propagate later.
Geographic Distribution: For globally distributed systems (e.g., content delivery networks or social media platforms), eventual consistency allows users to access nearby nodes, reducing latency while updates propagate globally.
How Eventual Consistency Improves System Performance
Eventual consistency boosts performance by decoupling operations across nodes, enabling the following:
Asynchronous Write Propagation: When a write occurs, it’s recorded on one node and propagated to others in the background. This reduces the time taken for write operations, as the system doesn’t wait for all nodes to acknowledge the update.
Local Reads and Writes: Clients can read from and write to the nearest node, minimizing network latency. For example, in a global e-commerce platform, a user in Asia can update their cart on a local server, and the update will propagate to servers in Europe and America later.
Reduced Coordination Overhead: Unlike strong consistency, which requires nodes to agree on every update (e.g., through two-phase commit protocols), eventual consistency avoids costly coordination, allowing faster processing of requests.
Load Balancing: Nodes can handle requests independently, distributing load across the system and preventing bottlenecks.
Resilience to Failures: If a node or network link fails, the system remains operational, as other nodes can serve requests, and updates sync once connectivity is restored.
However, eventual consistency introduces challenges, such as the need for conflict resolution and handling stale reads. Systems often use techniques like version vectors, timestamps, or last-write-wins policies to resolve conflicts when multiple nodes receive different updates for the same data.
How Distributed Systems Achieve Eventual Consistency
Distributed systems implement eventual consistency using several mechanisms:
Replication: Data is copied across multiple nodes. Updates to one replica are propagated to others asynchronously via mechanisms like gossip protocols or message queues.
Conflict Resolution: When nodes receive conflicting updates, systems use techniques like:
Timestamps: The update with the latest timestamp wins.
Vector Clocks: Track causal relationships between updates to resolve conflicts.
Application-Specific Logic: For example, in a shopping cart, merging items from conflicting updates.
Anti-Entropy Mechanisms: Periodic processes (e.g., Merkle trees or read-repair) compare and sync data across nodes to ensure convergence.
Write-Ahead Logs: Nodes log updates locally and replay them to other nodes to ensure all updates are applied.
Eventual Delivery: Systems use retry mechanisms or message queues to ensure updates reach all nodes, even after temporary failures.
Real-World Examples of Eventual Consistency
Amazon DynamoDB: Amazon’s NoSQL database uses eventual consistency for high availability and low latency. When a user updates an item, the change may not immediately reflect in all reads, but it propagates quickly.
Apache Cassandra: This distributed database allows tunable consistency, where applications can choose eventual consistency for higher availability or stronger consistency for critical operations.
DNS (Domain Name System): When a DNS record is updated, it takes time to propagate to all DNS servers worldwide, but all servers eventually converge to the same record.
Social Media Platforms: Platforms like X or Facebook use eventual consistency for feeds. A user’s post may not instantly appear on all followers’ feeds but will eventually be visible.
Content Delivery Networks (CDNs): CDNs like Akamai cache content at edge nodes. Updates to content propagate gradually, but users may see slightly outdated versions temporarily.
Trade-Offs of Eventual Consistency
While eventual consistency offers significant benefits, it has trade-offs:
Advantages
High Availability: Systems remain responsive even during network issues.
Scalability: Easily scales to handle large volumes of traffic.
Low Latency: Local operations reduce response times.
Fault Tolerance: Handles node or network failures gracefully.
Disadvantages
Stale Data: Reads may return outdated data, which can confuse users in some applications (e.g., banking).
Conflict Resolution Complexity: Resolving conflicting updates requires careful design.
Application Complexity: Developers must handle temporary inconsistencies, which can complicate application logic.
Mitigating Disadvantages
Tunable Consistency: Some systems (e.g., Cassandra) allow applications to choose consistency levels per operation, balancing between eventual and strong consistency.
Client-Side Caching: Applications can cache recent writes locally to reduce stale reads.
User Experience Design: Inform users about potential delays (e.g., “Your update is being processed”).
Quorum-Based Reads/Writes: Require a minimum number of nodes to agree on reads or writes to reduce inconsistency windows.
When to Use Eventual Consistency
Eventual consistency is ideal for applications where:
Availability and low latency are critical (e.g., social media, e-commerce).
Temporary inconsistencies are acceptable (e.g., social media feeds, product catalogs).
The system must scale to handle massive traffic or geographic distribution.
Fault tolerance is a priority (e.g., cloud-based services).
It’s less suitable for systems requiring immediate consistency, such as:
Financial systems where stale data could lead to incorrect transactions.
Real-time systems requiring precise data (e.g., air traffic control).
Conclusion
Eventual consistency is a powerful model for distributed systems, enabling high availability, scalability, and performance by allowing temporary inconsistencies. By propagating updates asynchronously and resolving conflicts intelligently, systems like Amazon DynamoDB, Apache Cassandra, and DNS achieve robust performance while ensuring data eventually converges across all nodes. While it introduces challenges like stale reads and conflict resolution, these can be mitigated with careful system design and application logic. For applications prioritizing availability and scalability over immediate consistency, eventual consistency is a cornerstone of modern distributed system design.