Ep #45: Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook 🗓️ Sep 30, 2025 · Free Post ·
What You’ll Gain from This Article
Amazon S3 is more than just “a place to store files” - it’s a carefully engineered system built to handle trillions of objects with near-limitless scalability and reliability. This article breaks down that complexity into practical, digestible insights so you can:
Understand the Why – Learn the original vision and the problems S3 was designed to solve.
See the Big Picture – Get a clear overview of S3’s architecture and its key components.
Follow the Data Journey – Trace exactly how a request moves through the S3 system.
Grasp Scaling Strategies – Discover how S3 partitions and auto-scales to handle unpredictable workloads.
Optimize Your Own Workloads – Apply S3 performance best practices to boost your application’s efficiency.
Think Like an Architect – Gain principles from S3’s design that you can apply to other distributed systems.
Whether you’re a developer, architect, or tech enthusiast, by the end of this read you’ll have both the conceptual clarity and practical understanding to make smarter design and optimization decisions for S3-based solutions.
Before we start the deep dive
We’ve come a long way in just a few months. Since launching this newsletter on June 8th, over 6,384 readers have joined - a milestone I never imagined so soon. On July 25th, we introduced paid membership, and already 20 readers have supported the journey - including 2 lifetime and 4 yearly subscribers. That kind of long-term trust means the world.
A heartfelt thank you to everyone — free and paid — for being part of this journey. We’re just getting started.
For those who want to join the Premium Membership to support this newsletter:
Amazon Simple Storage Service (S3) is one of the most fundamental and widely-used services in cloud computing today. Launched in 2006, S3 has become the backbone of countless applications, serving everything from simple file storage to complex data lakes powering machine learning workloads. This comprehensive guide explores how S3 works under the hood, its architecture, performance characteristics, and best practices for real-world usage.
Why Amazon S3 Was Created
– Solving the problem of internet-scale storage
The Problem S3 Solved
Before cloud storage services like S3, organizations faced several critical challenges:
Infrastructure Complexity: Companies had to purchase, configure, and maintain their own storage hardware, which required significant upfront investment and ongoing operational overhead.
Scalability Issues: Traditional storage solutions couldn't easily scale to accommodate rapidly growing data needs. Adding storage capacity often meant complex hardware upgrades and potential downtime.
Reliability Concerns: Ensuring data durability and availability required sophisticated backup and replication strategies that were expensive and difficult to implement correctly.
Global Distribution: Serving content globally required establishing data centers worldwide, which was prohibitively expensive for most organizations.
Amazon's Internal Need
Amazon originally developed S3 to solve their own internal infrastructure challenges. As their e-commerce platform grew, they needed a way to store and serve massive amounts of product images, user data, and other digital assets reliably and at scale. The solution they built was so robust and useful that they decided to offer it as a service to other organizations.
The S3 Vision
– A world where storage is infinite, reliable, and simple to access
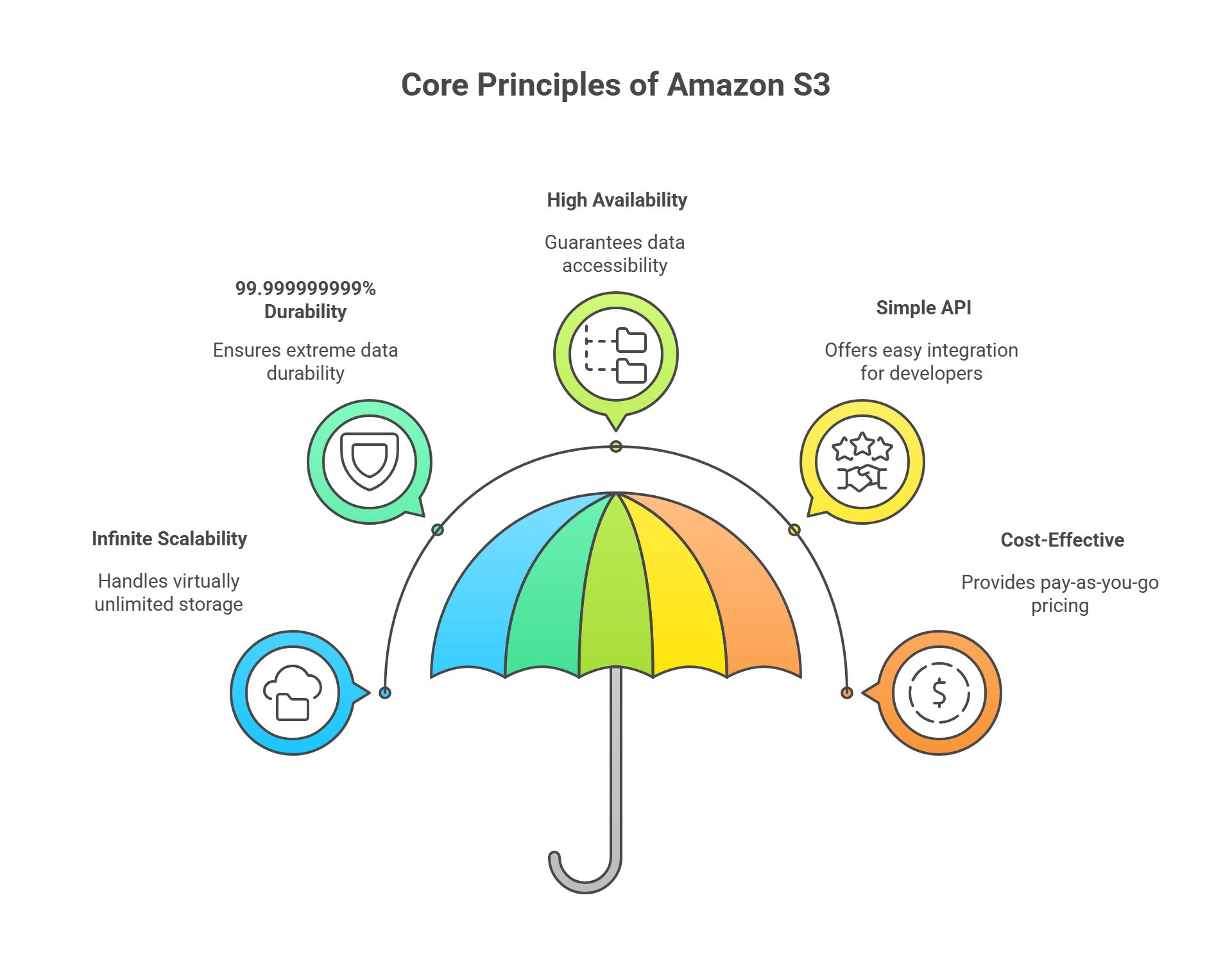
Amazon S3 (Simple Storage Service) was created to offer robust, flexible, and developer-friendly cloud storage. Its vision is anchored around the following core principles:
1. Infinite Scalability
S3 is architected to handle virtually unlimited storage, customers can upload any quantity of data, from a handful of files to petabytes or even exabytes. There is no need to pre-allocate storage or worry about running out of capacity, as the underlying infrastructure automatically adapts to increasing (or decreasing) storage demands, making it suitable for everything from small apps to global enterprise workloads.
2. 99.999999999% (“11 9’s”) Durability
S3 is engineered for extreme data durability. When an object is stored, S3 automatically replicates and distributes it across multiple geographically and physically separated facilities (Availability Zones). The “11 nines” means that, statistically, if you store 10 million objects in S3, you might expect to lose one object every 10,000 years. This is achieved through redundant storage, regular integrity checks, and self-healing processes that identify and repair data corruption.
3. High Availability
S3 ensures that your data remains accessible even if parts of the underlying infrastructure fail. This is achieved by replicating data across multiple locations within a region. S3 is designed for 99.99% availability over a given year, meaning that outages are brief and rare. Customers can rely on S3 to serve critical business applications, backup, and disaster recovery.
4. Simple API
The S3 API is RESTful and easy to use, making integration straightforward for developers. Operations like uploading, downloading, deleting, and managing data are exposed via simple HTTP commands. SDKs for popular programming languages further simplify common tasks. This ease-of-use lowers the barrier to adoption and encourages rapid development.
5. Cost-Effective (“Pay as You Go”)
S3 charges based only on what you use, there are no upfront costs, minimum fees, or provisioning hassles. Customers are billed for actual storage consumed, data transferred, and any additional features enabled (like advanced security or analytics), allowing efficient cost management. S3 also offers a variety of storage classes (Standard, Infrequent Access, Glacier, etc.) so you can optimize costs based on access patterns and retention needs.
S3 Architecture Overview
– Breaking down the storage powerhouse
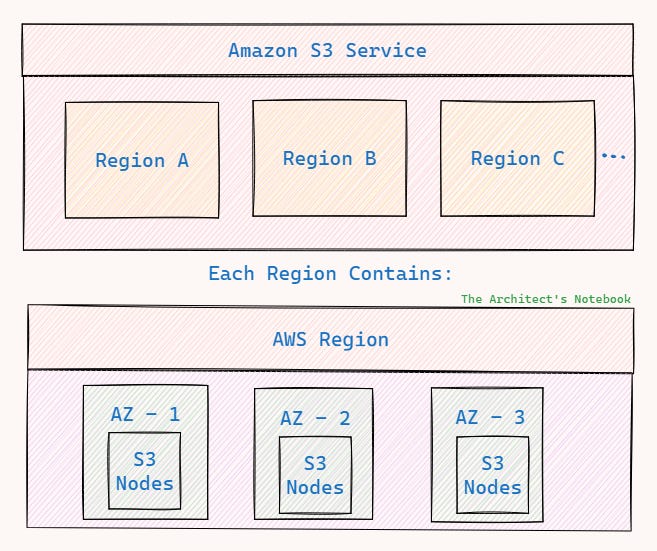
High-Level Architecture
At the highest level, S3 is distributed across multiple AWS Regions around the globe. Each region is segmented into several Availability Zones (AZs) essentially separate data centers - to ensure resilience to failures.
Key Points:
Regions: Geographically isolated groups of data centers.
Availability Zones: Independent facilities within a region; each region contains at least three AZs.
Core Components of S3 Architecture
1. S3 Control Plane
Function: Handles incoming API requests (such as object uploads, deletions, policy changes), manages bucket and object metadata, and coordinates placement of data.
Role: Ensures consistency, tracks versions and access, and orchestrates activities like lifecycle actions or replication.
2. Storage Nodes
Function: Physical servers, packed with hard drives or SSDs, where your actual data ("objects") resides.
Distribution: Spread across multiple AZs for fault tolerance. S3 replicates each object across several nodes and AZs for durability.
Self-Healing: Nodes send health "heartbeats" to the control plane. If a node fails or data corruption is detected, S3 automatically restores redundancy by re-replicating data from healthy copies.
3. Index System
Function: Maps object keys (unique identifiers like filenames) to their physical storage locations across the nodes.
Role: Enables high-speed lookup and retrieval by translating user/API requests to the correct storage location, regardless of internal changes to infrastructure.
4. Request Router
Function: At the entry point, routes every API call to the appropriate service within S3, balancing load and optimizing for availability and latency.
Role: Ensures that requests reach healthy nodes, and retries or reroutes if failures are detected.
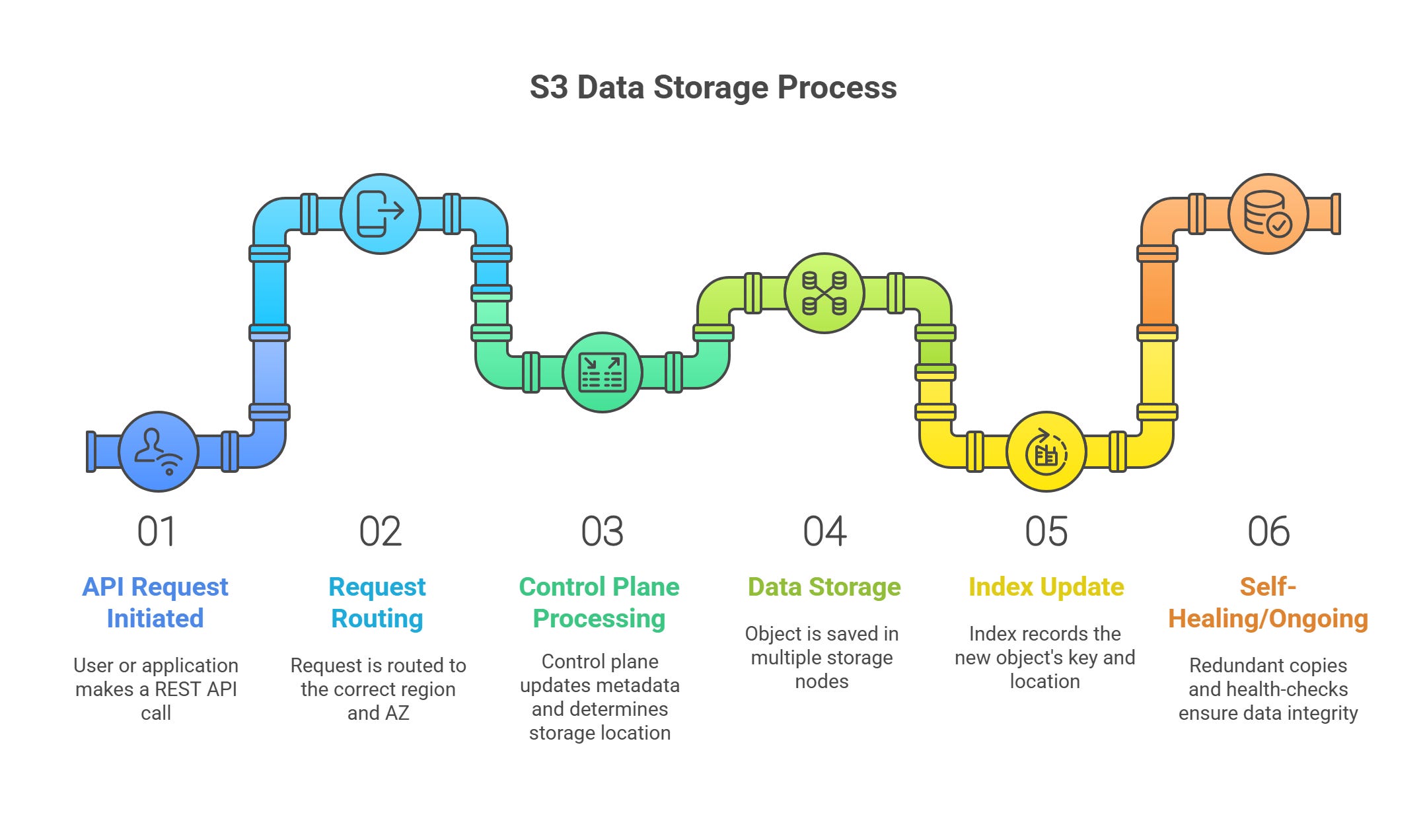
How Data Flows through S3 (Step-by-Step)
– A step-by-step journey from request to storage
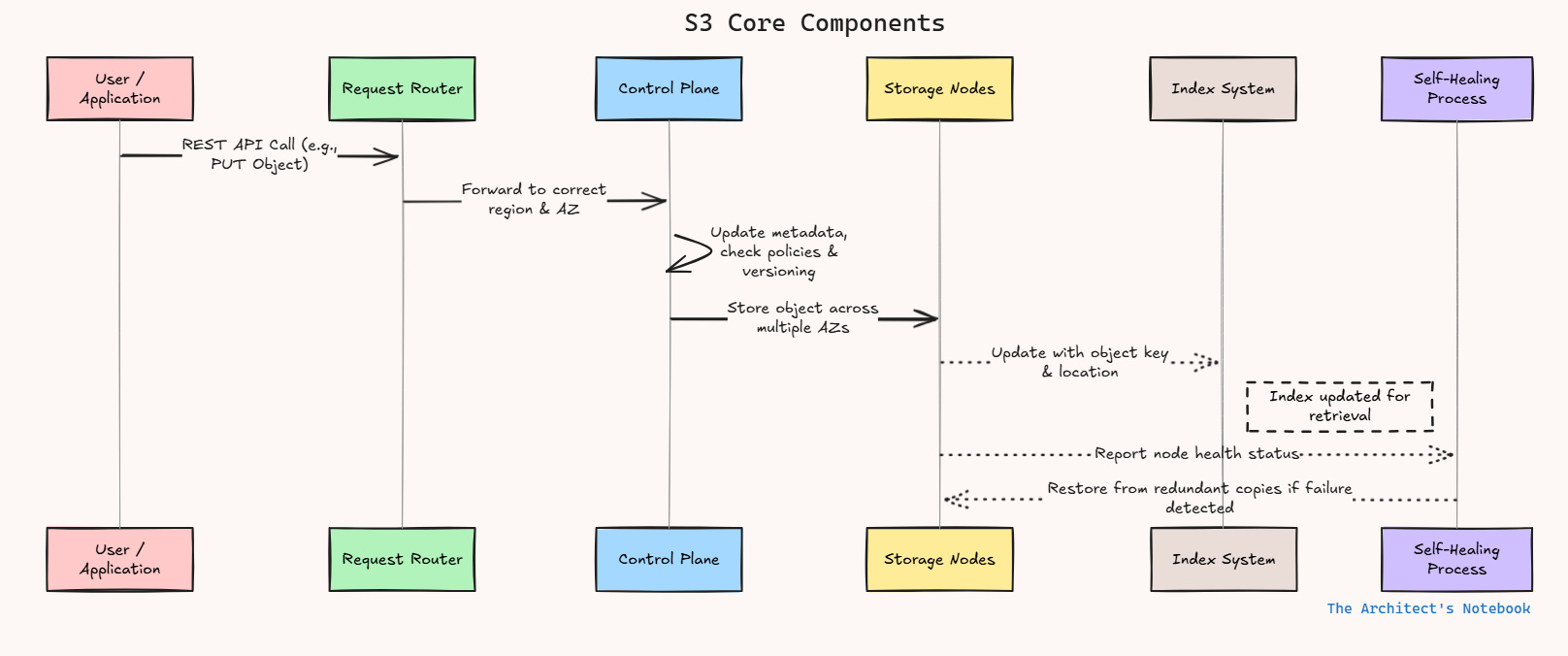
API Request Initiated: A user or application makes a REST API call (e.g., PUT to upload an object).
Request Routing: The request hits the Request Router, which forwards it to the correct region and AZ.
Control Plane Processing: The control plane updates metadata, determines where to store data, and ensures the action complies with policies and versioning.
Data Storage: The object is saved in multiple storage nodes (span AZs for redundancy).
Index Update: The index records the new object's key and location.
Self-Healing/Ongoing: If any node fails or data is corrupted, redundant copies and health-checks ensure data integrity and quick restoration.
Microservices: S3 is powered by hundreds of microservices, enabling modularity and ease of scaling. Each component (like storage or indexing) may actually be a cluster of subsystems and teams, each operating with API contracts.
Buckets and Keys: User data is organized in 'buckets,' but under the hood, S3 represents every object with a unique key, and manages all access using the index system.
Scalability Architecture
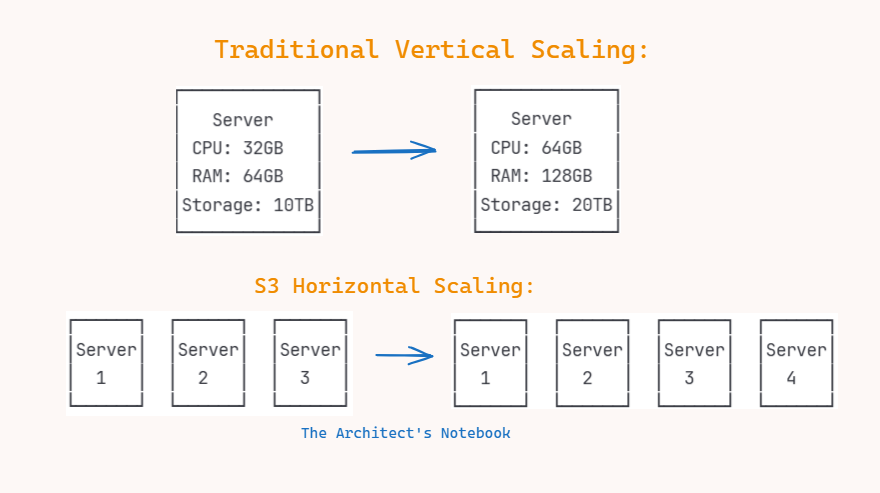
Horizontal vs. Vertical Scaling
Vertical Scaling: Increasing the power (CPU, RAM, storage) of a single server. Limitations: Cap on how big a server can get; eventual bottleneck.
Horizontal Scaling (S3’s Approach):
S3 achieves massive scalability through horizontal scaling rather than vertical scaling. Instead of making individual servers more powerful, S3 adds more servers to handle increased load. Adding more servers to the system, each one relatively small and simple, but together forming a massive distributed network without a central point of failure or capacity limit.
S3’s backend can add new storage nodes at any time with virtually no upper limit, making it perfectly suited for unpredictable or hyper-scale workloads.
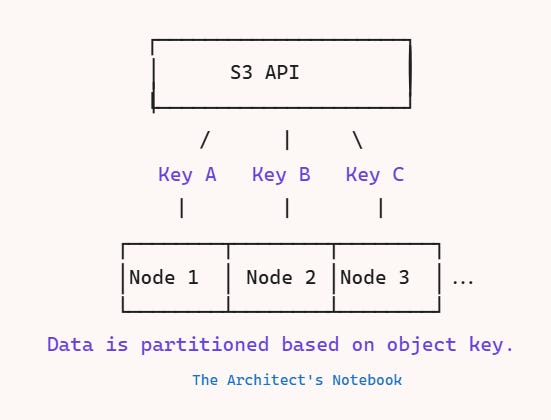
Partition Strategy
S3 stores data as “objects” with unique “keys” inside “buckets.” S3 automatically partitions data based on object keys. The service uses consistent hashing to distribute objects evenly across storage nodes:
Key-Based Partitioning: The object’s key (bucket + filename) determines which partition/node it resides on, using hashing and lexicographic techniques for even spread.
Objects are distributed based on their full key (bucket + object name).
Consistent Hashing: Prevents overloading nodes if new ones are added or old ones removed.
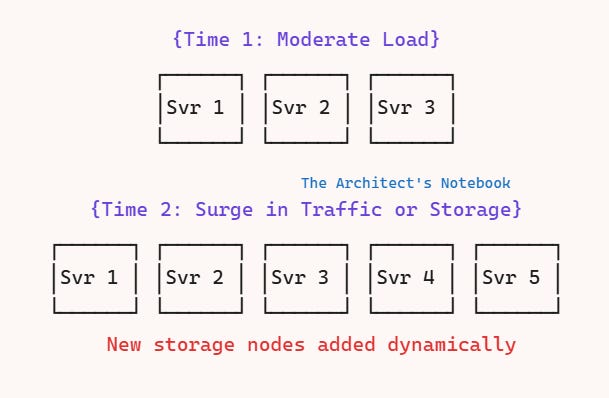
Dynamic Rebalancing: If storage nodes or partitions get too “hot” due to high traffic or size, S3 can seamlessly split partitions and redistribute data to balance load. This is invisible to the user.
Hot Partition Detection: S3 continuously monitors request patterns. If a partition/key (e.g., all keys starting with the same prefix) gets more traffic, the system rebalances it automatically.
Randomized Key Prefixes: AWS recommends adding randomness to object key prefixes to prevent “hot spots” for example, /img/3ac9dc_file1.jpg instead of /img/2024/file1.jpg. This helps S3 spread storage and access evenly across its fleet.
Auto-Scaling in Action
– How S3 adapts to fluctuating workloads
Unlike traditional compute-based auto-scaling, S3’s scaling is:
Request Rate Scaling: As the rate of GET/PUT requests surges, S3 transparently adds more front-end and back-end processing capacity, no user intervention required.
Storage Scaling: As users upload more objects, new storage nodes are automatically brought online and data rebalanced, so there’s never a practical storage cap.
Regional Expansion: With cross-region replication, S3 replicates popular content to new regions if global access patterns demand it, minimizing latency and further spreading load.
Key Takeaways
S3’s scalability is not theoretical: AWS runs over 350 trillion objects and processes 100M+ requests/second using this design.
Users don’t need to pre-provision, “scale up,” or worry about bottlenecks.
Partitioning and auto-scaling are seamless and completely invisible to end-users, making S3 a foundational building block for cloud-native, internet-scale apps.
Amazon S3 Performance Characteristics
– Latency, throughput, and durability guarantees
Amazon S3 is built for high throughput, low-latency access at cloud scale.
Core Performance Metrics
Throughput and Request Rates
Request Rate per Partition/Prefix:
3,500 PUT/COPY/POST/DELETE requests per second per prefix
5,500 GET/HEAD requests per second per prefix
Bandwidth:
Up to 100Gbps between S3 and EC2 (in the same region), enabling enormous data movement capabilities.
Scaling via Prefixes:
There are no hard limits on the number of prefixes in a bucket. By distributing objects across multiple prefixes, throughput can be scaled linearly (e.g., 10 prefixes → 35,000 writes/sec).
Latency:
Typical operation latency is 100–200ms for most requests.
Closing Thoughts
Amazon S3 is not just a storage service - it’s a masterclass in distributed system design. From its carefully partitioned architecture to its adaptive scaling strategies, S3 balances reliability, scalability, and performance on a truly global scale. By understanding how its core components interact, architects and developers can appreciate the engineering behind it and apply these principles to build resilient systems of their own.
As detailed as this deep dive has been, we’ve only scratched the surface of S3’s full architecture. In our next premium article, we’ll explore the S3 REST APIs, how S3 enforces authentication, the internal storage architecture, data distribution mechanisms with parallel reads, erasure coding, and much more.
If you want to truly master S3’s architecture, this is the perfect time to become a paid member and gain access to the upcoming in-depth explorations.
If you have any questions about the membership or content suggestions, feel free to reply or leave a comment below. Thanks for supporting The Architect’s Notebook!