

System Design Insight: Why Scaling Reads Is Easy but Scaling Writes Is Hard
Why you can't just "add more servers" to a write-heavy database.

One concept, clarified in 2 minutes
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Jan 31, 2026 · Free Edition ·
If you’ve ever sat in a system design interview and confidently said,
“We’ll add read replicas to scale,”
you probably noticed the interviewer didn’t react.
Because scaling reads is the easy part.
The real test of an architect is this:
Can you scale writes without breaking consistency, correctness, or money?
Let’s break it down with real reasoning you can use in interviews — and in production.
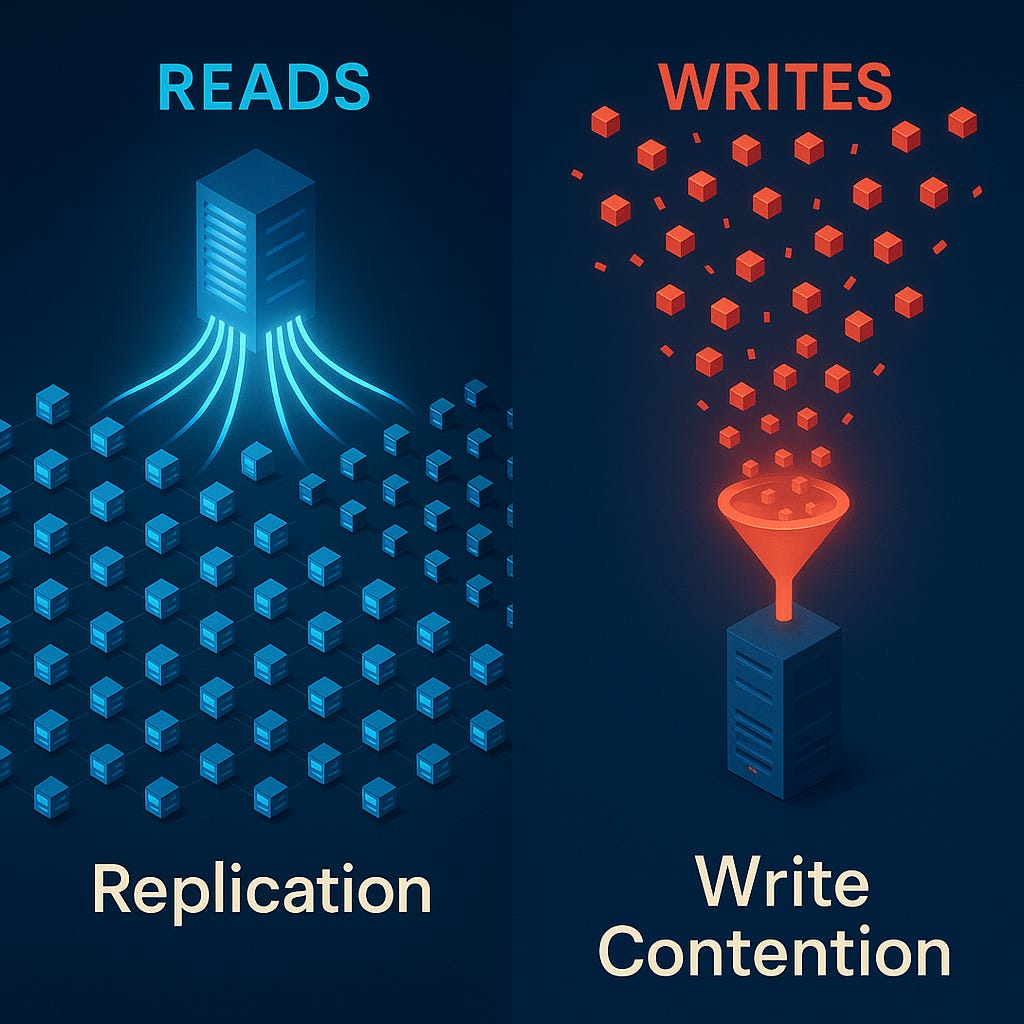
Reads Are Easy Because They Don’t Change Anything
When a user performs a read:
No data changes
No locks are taken
No conflicts occur
Multiple copies can serve the same data
This means you can scale reads with:
Caches (Redis, CDN)
Read replicas
Sharding
Search engines (Elasticsearch)
Materialized views
Reads are embarrassingly parallel.
You can throw 10 replicas at the problem and magically get 10× capacity.
That’s why companies say:
“Reads scale horizontally.”
And they really do.
Writes Are Hard Because They Change the Truth
A write operation modifies shared reality.
That instantly introduces complexity:
1. Writes require coordination
While reads are “just copies,”
writes must decide:
What is the latest value?
Who gets to write now?
What happens if two writes collide?
This is why writes hit:
locks
transactions
race conditions
serialization bottlenecks
2. Writes force consistency decisions
Every distributed system must answer:
“Is it okay if two clients see different data temporarily?”
If yes → you choose Availability
If no → you choose Consistency
That’s the heart of the CAP theorem.
3. Writes don’t scale linearly
If you double your write replicas,
you now must double:
replication
conflict resolution
state synchronization
Write amplification grows faster than you think.
The Physics of the Bottleneck: Writes Must Be Serialized
This is the part most engineers miss.
To keep data consistent, writes must be serialized (put in order). And serialization is the enemy of scale.
You cannot allow:
Update A and Update B to overwrite each other
Transactions to apply out of sequence
“Last write wins” to corrupt financial correctness
Reads don’t need ordering.
Writes do.
And that ordering becomes the bottleneck.
It’s not a coding problem — it’s physics.
The Only Way Out: Sharding
If serialization kills write throughput, how do real systems scale?
They cheat.
They stop treating the database as:
“One big journal of truth”
And instead turn it into:
“1,000 little journals”
Example:
User A writes to Shard 1
User B writes to Shard 2
Now writes don’t hit the same bottleneck.
They happen in parallel without stepping on each other.
This is sharding.
It dramatically increases write throughput —
but at the cost of new complexity:
cross-shard joins
rebalancing
distributed transactions
inconsistent hotspots
routing logic
Scaling writes always comes with trade-offs.
Real Example: Why Payments Are Hard
Let’s say two requests try to update a bank balance:
Balance = 100
Write A → -50
Write B → -50Reads? No problem — 1,000 replicas can read “100”.
But writes?
Which one arrives first?
What if both are processed at the same time?
What if Write A succeeds but the acknowledgment is lost?
What if Write B retries?
Now you’ve charged the customer twice.
That’s why financial systems use:
distributed locks
optimistic concurrency
idempotency keys
sharding
You can’t blindly “scale writes” the way you scale reads.
Money demands correctness.
The Takeaway for Interviews
When asked:
“How will you scale this system?”
Do NOT say:
“We’ll add more replicas.”
Instead say:
“Reads and writes scale differently.
Reads can be fanned out.
Writes need serialization, sharding, or queuing because they modify shared state.”
This one sentence signals architect-level thinking.
Don’t optimize for Write Scalability unless you absolutely have to. Most apps are 99% reads and 1% writes. If you can cache it, cache it. If you have to shard it, say a prayer.
If you found this useful, share it with another engineer who mixes up read vs write scaling.
And if you want more short architecture lessons like this, hit Subscribe — your future interview self will thank you. 🚀