

System Design Insight: The Real Difference Between Throughput and Latency
When optimizing for scale hurts speed.

One concept, clarified in 2 minutes
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Feb 7, 2026 · Free Edition ·
If you really want to expose whether someone understands system performance or just memorizes buzzwords, ask this:
“What’s the difference between throughput and latency?”
Most engineers give textbook answers.
Architects give behavioral answers — the kind that explain how real systems break under load.
Let’s make sure you answer like an architect.
The Common (Wrong) Answer
Most people say:
“Latency is how long a request takes.”
“Throughput is how many requests we can handle per second.”
Technically correct.
Practically useless.
Because in real systems, the two fight each other.
And that’s where real performance engineering begins.
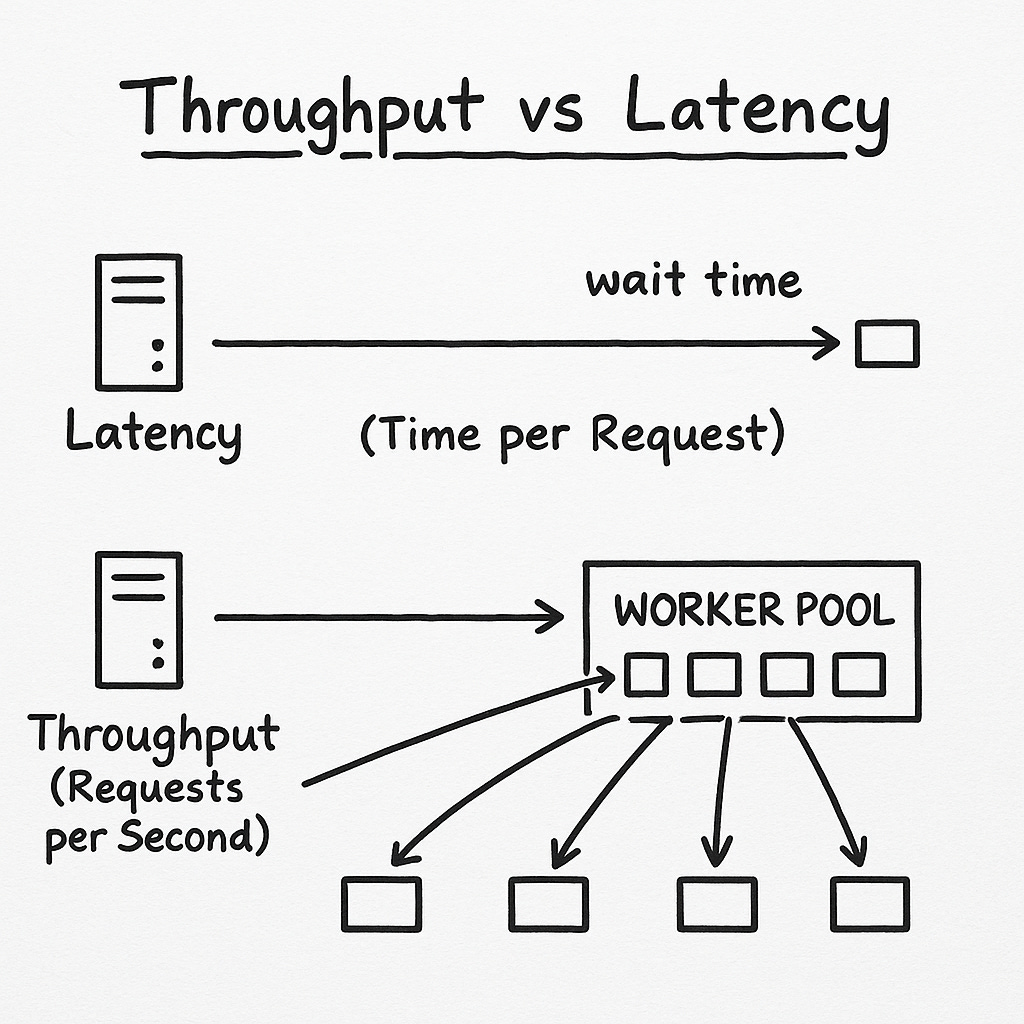
Latency: How long one request waits
Latency is about speed of a single request:
How fast your API returns
How quickly the DB runs a query
How long a message stays in the queue
How soon a user sees a response
When latency spikes, users feel it immediately:
slow page loads
checkout delays
lag in chat apps
Latency is a user-facing pain.
Throughput: How many requests you can handle in parallel
Throughput measures capacity:
100 req/sec
1,000 messages/sec
50 writes/sec
When throughput drops:
queues back up
CPU hits 100%
threads get exhausted
the whole system starts “breathing heavily”
Throughput is a system-facing limit.
The Real Insight: Improving One Can Hurt the Other
This is the part interviewers want.
Increasing throughput often increases latency because:
more requests → more queuing
queues create wait time
wait time increases response time
Imagine a restaurant:
If you add 200 customers (higher throughput)
but keep the same number of chefs,
everyone’s food arrives late (higher latency).
Real systems behave exactly the same.
Why Architects Care About This
Because system design is often about answering:
“Do we optimize for one fast request, or many acceptable requests?”
Example:
Redis
Optimized for latency
Simple operations, in-memory, ultra-fast
Kafka
Optimized for throughput
Batches messages, trades speed for volume
Payment systems
Optimized for correctness, not either
Each domain makes a different trade-off.
The Interview Version (Say This!)
“Latency is about the speed of one request.
Throughput is about how many requests the system can handle.
At scale, improving throughput often increases latency because of queuing. The right balance depends on the product’s goals — user experience vs. capacity vs. cost.”
This answer checks all the boxes:
conceptual, practical, and architecture-aware.
If this helped you finally “feel” the difference between throughput and latency, share it with another engineer.
And if you want more quick architecture lessons like this, hit Subscribe — your future interview self will thank you. 🚀
“At scale, improving throughput often increases latency because of queuing.” This makes me think. Space based architecture might achieve a better trade off on improving throughput without latency degradation because we will not attempt to improve throughput just putting a buffer (queue) in the middle?