

Ep #34: Mastering Microservices Part 2 - Connecting Distributed Services Effectively
An in-depth guide to synchronous and asynchronous communication, their trade-offs, and best practices for building resilient microservice interactions.

Ep #34: Breaking the complex System Design Components – Premium Post
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Sep 4, 2025 · Premium Post ·
Recap of Part 1 – Microservices Foundations
In Part 1, we traced the evolution from monoliths to microservices, explored the technical, organizational, and business reasons behind their rise, and outlined core principles like business capability alignment, decentralized governance, and failure isolation. We also dived into architecture basics - applying DDD, right-sizing services, choosing per-service tech stacks, and adopting the database-per-service pattern. This foundation equips us to now explore microservice communication, service discovery, data consistency, and resilience strategies in Part 2. Now let’s continue
Communication Patterns
Microservices need to talk to each other to form a cohesive system. Communication can be synchronous (request waits for response) or asynchronous (interaction happens independently).
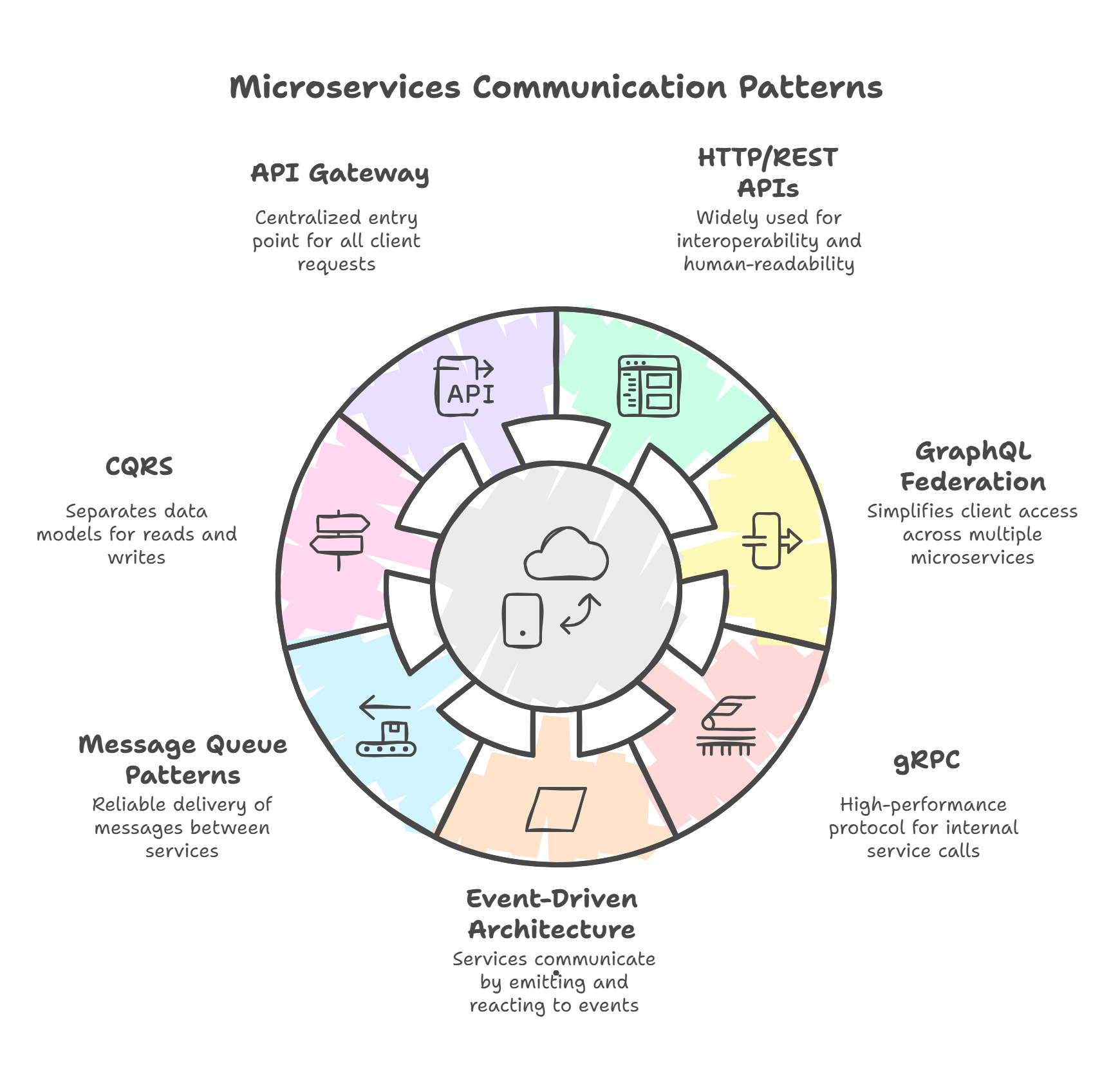
1. Synchronous Communication
a. HTTP/REST APIs
This is the most widely used pattern. One service calls another over HTTP/REST, often using JSON as the data format. The caller waits (is “blocked”) until it gets a response. This is straightforward and easy to debug.
How it works:
Services expose endpoints (e.g.,
/api/v1/orders) that clients or other services call using standard HTTP methods (GET, POST, etc.), sending/receiving data in JSON or XML.Widely used for both external and internal service communication, particularly when interoperability and human-readability are important.
Example (Order Placement in E-commerce):
A shopping cart service can call an order service via HTTP POST to place a new order, sending JSON:
Order Service exposes an HTTP endpoint
/api/v1/ordersUser Service or web frontend calls this endpoint to place an order
javascript
// Service A calling Service B
const orderResponse = await fetch('/order-service/api/v1/orders', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
userId: 123,
items: [{ productId: 456, quantity: 2 }]
})
});
const order = await orderResponse.json();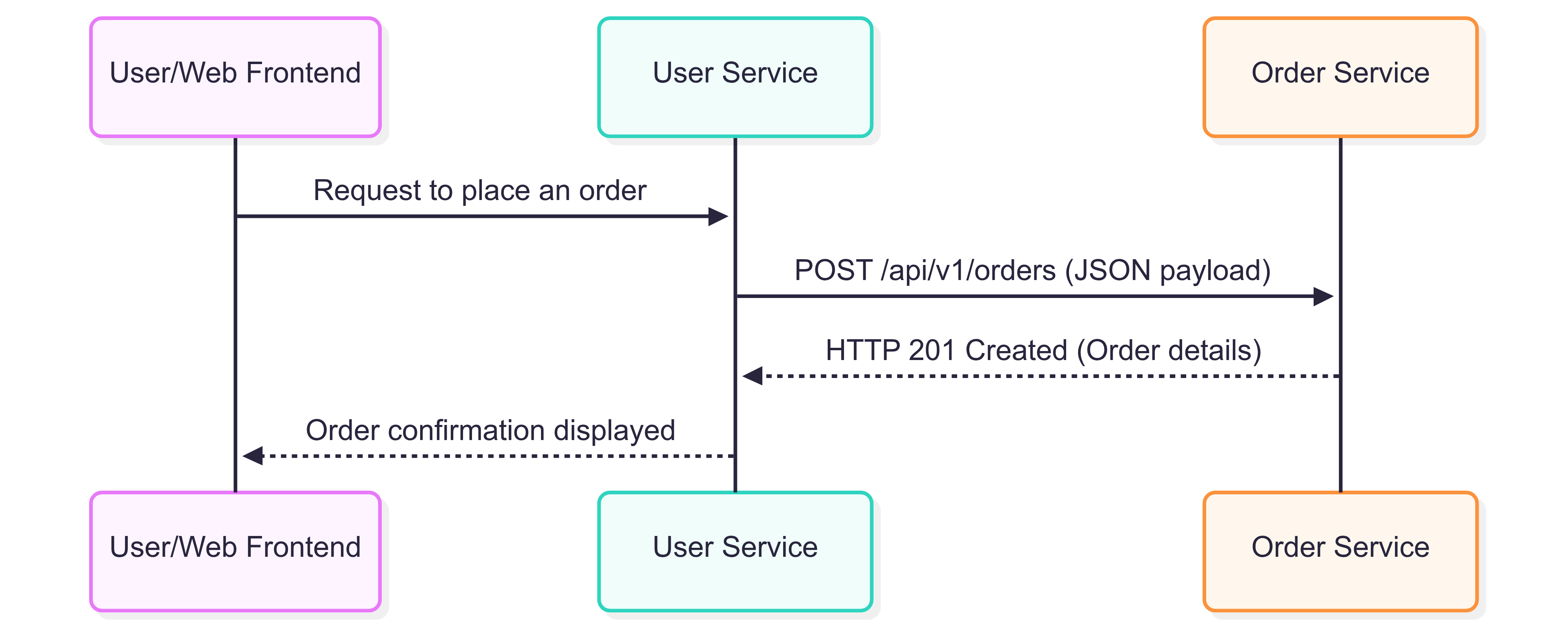
When to Use:
Immediate feedback is needed (e.g., checkout or payment)
Simpler workflow, easy for small teams
Pros:
Simple & Universal: Easy to understand and debug.
Ecosystem: Fits well with most web stacks, abundant libraries and developer experience.
Interoperable: Any tech, platform, or language can use HTTP/REST.
Cons:
Latency: Text-based, so higher overhead than binary protocols.
No Strong Typing: Communication is flexible but less type-safe; runtime errors more likely.
Versioning Pain: Changes in APIs can break clients unless managed carefully.
Tight Coupling: Clients must be aware of endpoint contracts and often wait for synchronous responses.
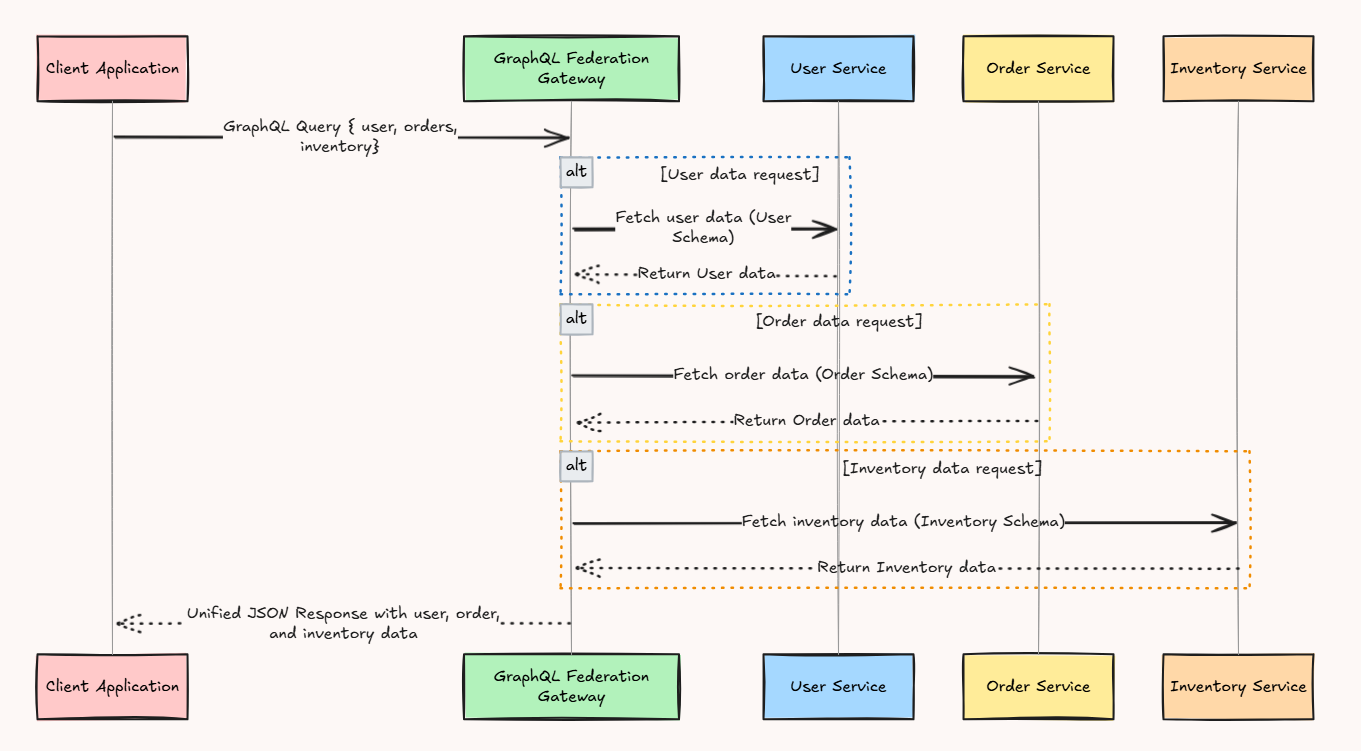
b. GraphQL Federation
GraphQL Federation allows multiple microservices to expose their own GraphQL schemas, which a central gateway “stitches” together into a unified API. Each service handles a different domain (User, Order, Inventory).
How it works:
Each microservice exposes its own GraphQL schema; a federation gateway combines these into a unified API.
Clients can query multiple microservices via a single gateway in one request, receiving only the data they ask for.
Example:
The User Service defines a
Userschema; the Order Service extends this with relatedOrderdata.
graphql
# In the User Service schema:
type User @key(fields: "id") {
id: ID!
name: String!
email: String!
}
# In the Order Service schema:
type Order {
id: ID!
user: User
items: [OrderItem!]!
}
extend type User @key(fields: "id") {
orders: [Order!]!
}
Pros:
Single Data Access Point: Clients fetch all needed data in one query, reducing API calls.
Fine-grained Data: Only requested fields are returned - no need for multiple endpoints or over-fetching.
Flexible Schema Evolution: Adding new fields doesn’t break existing queries.
🔒 This is a premium post — an extended deep-dive continuation of on going Microservices Series
👉 All paid subscriptions are managed through Gumroad.
To get full access to premium posts and newsletters, please subscribe here (Premium members can continue the series):Just a quick note to clarify how premium memberships are managed:
All subscriptions are handled through Gumroad.
Once you subscribe on Gumroad, I will manually add you as a Paid Member here on Substack.
A confirmation email will be sent to your Substack email ID once your access is activated.
This means you get access to all premium posts, resources, and ongoing discussions.
For reference, here are all the key resource URLs:
Memberships:
Books