

Ep #89: Vector Databases 101 (Part 1): Why SQL Fails at "Meaning"
Why your SQL database can't understand "meaning," and how to architect the memory for your AI applications.

Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Mar 10, 2026 · Deep Dive ·
The “Confident Liar” Problem
We have all played with ChatGPT. It’s magical. It writes code, summarizes emails, and composes poetry about databases.
But if you ask it about your company’s internal documentation, or a specific customer support ticket from yesterday, it fails. Worse, it doesn’t just say “I don’t know.” It hallucinates. It confidently invents a policy that doesn’t exist.
This happens because Large Language Models (LLMs) have Parametric Memory. They only know what they were trained on (which cut off months ago). They are like a brilliant professor locked in a room without internet for a year.
To fix this, we don’t need to retrain the model (which costs millions). We need RAG (Retrieval-Augmented Generation).
Retrieval: Find the relevant pages in your company’s textbook.
Augmentation: Paste those pages into the prompt context.
Generation: Ask the LLM to answer using only that information.
The hard part isn’t the “Generation” (OpenAI does that). The hard part is the Retrieval. How do you search through 100,000 PDF documents to find the exact paragraph relevant to a user’s vague query?
Your standard Postgres LIKE ‘%query%’ won’t work. ElasticSearch keyword matching won’t work.
You need a new kind of database. You need a Vector Database.
Today, we are going to explore the physics of “Semantic Search,” the algorithms that power Vector Databases (HNSW), and how to design a production-grade RAG system from scratch.
Part 1: What is a Vector? (The Physics of Meaning)
To a computer, text is just bytes. To make a computer understand “meaning,” we need to convert text into numbers. But not just any numbers—coordinates.
Imagine a 2D graph:
X-axis: How “furry” is the object?
Y-axis: How “domesticated” is the object?
On this graph:
Dog:
[0.9, 0.9](Very furry, very domesticated).Cat: [0.8, 0.8] (Similar to Dog).
Wolf:
[0.9, 0.1](Furry, but wild).Toaster:
[0.0, 0.0](Not furry, not domesticated).
If I ask for “something like a puppy,” I can plot “puppy” on the graph and mathematically measure the distance to the other points. The “Dog” point will be the closest. The “Toaster” will be far away.
This is an Embedding.
In modern AI (like OpenAI’s text-embedding-3-small), we don’t just use 2 dimensions. We use 1,536 dimensions.
Every piece of text you feed into the model—whether it’s “Hello world” or a 10-page contract—gets squashed into a list of 1,536 floating-point numbers.
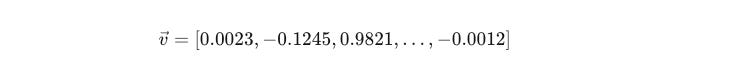
The magic is that in this high-dimensional space, semantic concepts cluster together.
The vector for “King” minus the vector for “Man” plus the vector for “Woman” lands almost exactly on the vector for “Queen”.
The vector for “Apple” (the fruit) is far away from “Apple” (the iPhone) if the context is different.
This allows us to search not for keywords, but for intent.
A Quick Note Before You Go: If today’s deep dive resonated with you, you need to check out my newly released book: The Architecture of Neural Scale: Volume 1(A) - Foundations of AI Systems.
Right now, most of the industry treats AI like a magical black box—just another API call to a vendor. But if you want to understand what is actually happening under the hood, you have to look deeper.
This book is the definitive guide to how AI actually works behind the scenes. Whether you want to grasp the foundational concepts of Large Language Models or demystify the “magic” of how billions of parameters generate text, this volume breaks it down. We take you from the basic mechanics of neural networks all the way to the “metal layer”—explaining hardware physics, memory bottlenecks, and how these massive systems are served in production without melting down. We don’t do theoretical hype; we do real engineering.
To celebrate the launch, I am offering a 10% discount for just a few more days. If you are ready to stop building API wrappers and start understanding true AI infrastructure, this is your blueprint.
Use below link to get the book at discounted price
Part 2: Why SQL Fails Here
Why can’t we just store these arrays in Postgres and query them?
In a standard database, indexes (B-Trees) are built for Exact Matching or Range Matching (Greater Than / Less Than). B-Trees are excellent at sorting numbers: 1, 2, 3, 4, 5.
But vectors aren’t single numbers. They are multi-dimensional coordinates. There is no simple “sort order” for 1,536 dimensions.
If you wanted to find the “nearest neighbor” to a query vector in Postgres without a special index, you would have to:
Scan every single row in the table (Full Table Scan).
Calculate the distance (Cosine Similarity) between the query and the row.
Sort them all.
Return the top 5.
This is O(N). If you have 1 million vectors, and each distance calculation takes a few microseconds, your query takes seconds. That is too slow for search.
We need a way to find “approximate” nearest neighbors (O(logN)) without scanning the whole world.
🔒 Subscribe to read the HNSW Algorithm & Pipeline Design
How do we search 1 million vectors in 5 milliseconds? We need an algorithm that navigates high-dimensional space like a GPS navigates a city map.
In the rest of this deep dive, we will cover:
The HNSW Algorithm: How “Hierarchical Navigable Small Worlds” act like an express highway for your data.
The RAG Architecture: The exact ETL pipeline from PDF -> Chunking -> Embedding -> Vector DB.
The “Lost in the Middle” Phenomenon: Why retrieving too much context actually makes the LLM dumber.