

Ep #81: The Distributed Lock Nightmare (Part 1): Why Your Redis Lock is Lying to You
Why synchronized doesn't work in the cloud, and the million-dollar race condition that "Redlock" can't fix.

Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Feb 10, 2026 · Deep Dive ·
Quick Announcement
📢 Just Released: The Architecture of Digital Identity (Vol 2A)
We have released the latest volume of The Architect’s Security Series last week.
This 600-page guide is dedicated to the most critical layer of modern distributed systems: Identity, OIDC, and Access Control. If you want to move beyond simple login screens to mastering the architecture of trust, this is your blueprint.
🚀 Launch Offer: To celebrate the release, you can grab the standalone book for $39 (Regular $59). This discount is valid until the end of this week.
(Note: If you are a Lifetime Member, do not buy this! It has already been added to your Gumroad library for free.)
The Million-Dollar Race Condition
Let’s start with a horror story. You are building a “Wallet” service for a fintech startup. You have a withdraw() function:
Check balance (
SELECT balance FROM wallets WHERE user_id = 1)If balance > amount, subtract amount
Update balance (
UPDATE wallets...)
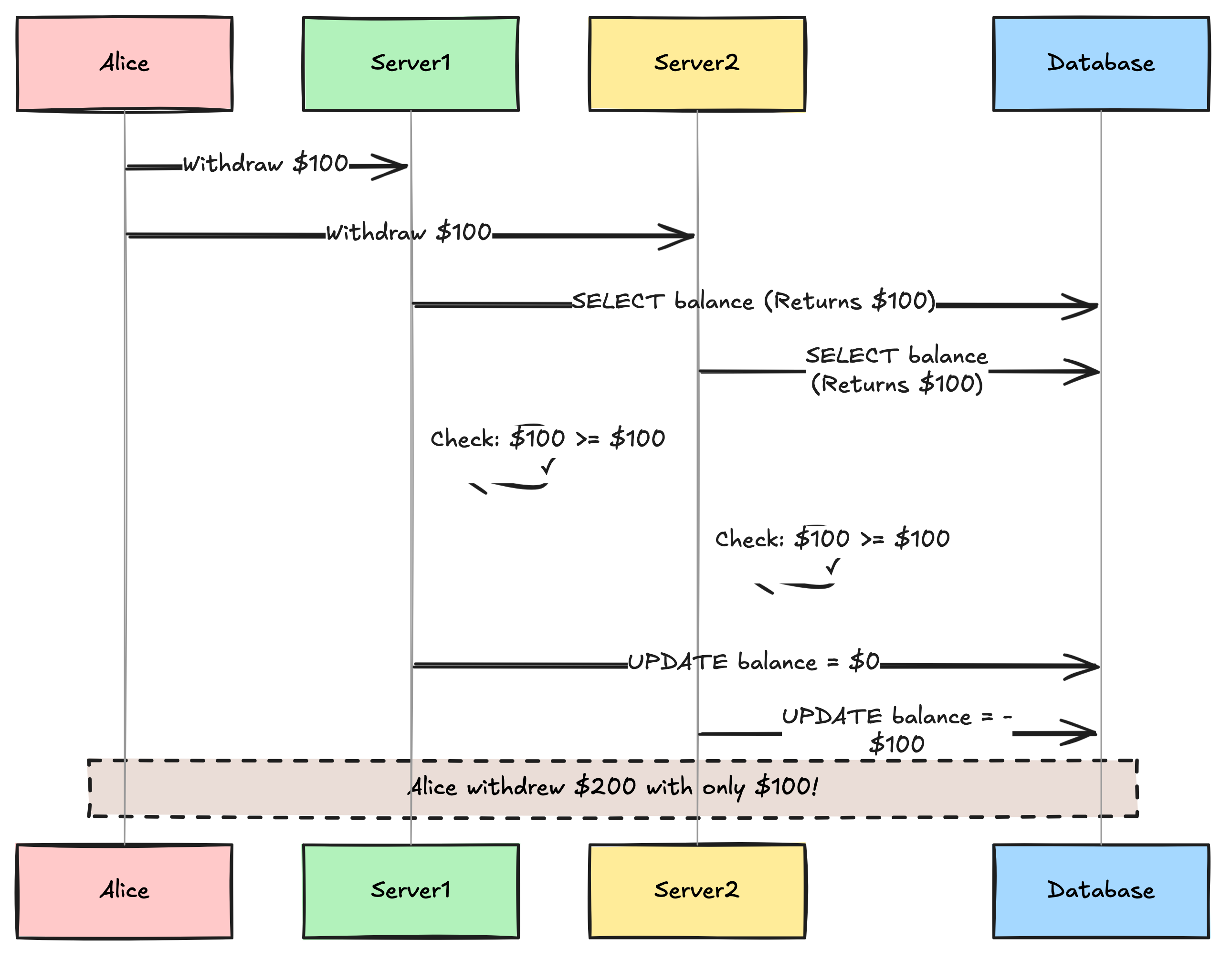
It works perfectly in development. You ship it. Black Friday arrives. A user named “Alice” writes a script to hit your API with two concurrent withdrawal requests for $100. She only has $100 in her account.
Request A hits Server 1. It reads the balance: $100.
Request B hits Server 2. It reads the balance: $100 (because Request A hasn’t saved the new balance yet).
Request A subtracts $100 and saves. Balance = $0.
Request B subtracts $100 and saves. Balance = -$100.
Alice just stole $100 from you.
In a monolithic application running on a single server, you would fix this with a simple mutex or a synchronized block in Java/C#. This works because all threads share the same Operating System memory space. The OS kernel acts as the referee.
But in a Distributed System, Server 1 and Server 2 are different machines. They don’t share memory. They don’t even share a clock. A Java lock on Server 1 is invisible to Server 2. To solve this, we need a Distributed Lock—a mutex that lives outside your application servers, in a shared location that everyone can see.
This leads us to the Great Debate: Where do we put the lock?
The Contestants
When architects discuss distributed locking, these are the usual suspects:
Redis: The popular choice. Fast, simple, AP (Available/Partition-tolerant)
ZooKeeper / Etcd: The “Correct” choice. Uses Consensus algorithms (ZAB/Raft). CP (Consistent/Partition-tolerant)
Postgres/MySQL: The boring choice. Uses Row-level locking or Advisory Locks
Most startups pick Redis because they already have it. Most enterprises pick ZooKeeper because they read a Google whitepaper. Let’s figure out who is right.
The Trap of Redis Locking
If you Google “Redis Distributed Lock,” you will find a StackOverflow answer that suggests something like this:
-- Bash
SET resource_name my_random_value NX PX 30000NX: Only set if it does not exist (Acquire lock) - Set If Not ExistsPX 30000: Expire in 30 seconds (TTL)
If the command returns “OK”, you have the lock. When you are done, you delete the key. Simple, right?
Wrong. This implementation is dangerous.
The “Zombie Process” Problem
What happens if your application crashes after acquiring the lock but before releasing it?
Without a TTL (Time To Live), that lock would stay there forever. The resource would be deadlocked.
That is why we add the PX 30000 (30-second expiration). It’s a safety mechanism.
But this introduces a new, terrifying problem: GC Pauses and Clock Drift.
The GC Horror Scenario:
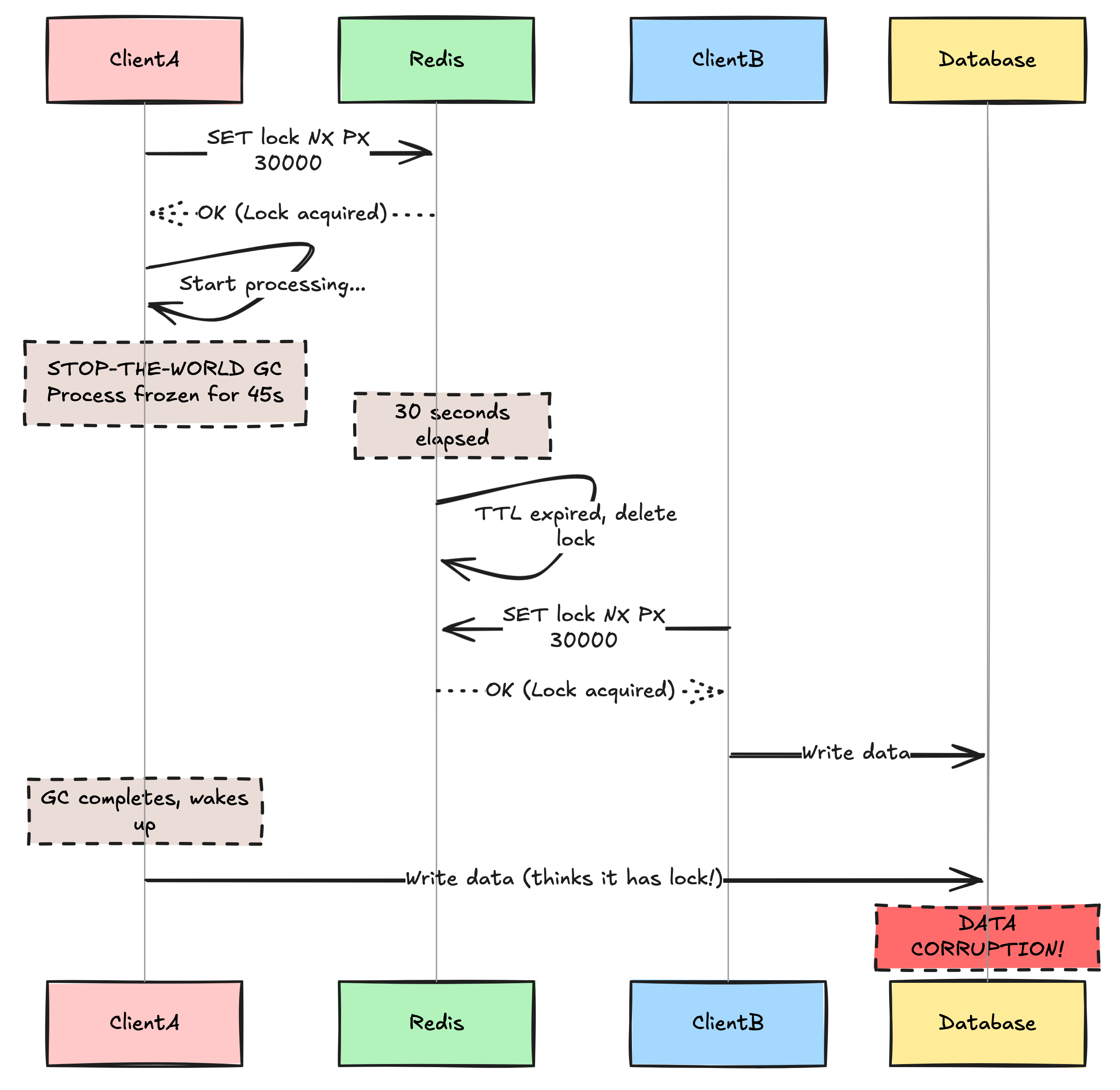
Imagine this scenario:
Client A acquires the lock. TTL is 30 seconds.
Client A starts processing (e.g., calling a slow 3rd party API).
Client A’s JVM triggers a “Stop-the-World” Garbage Collection. The entire process freezes for 45 seconds.
Redis sees 30 seconds have passed. It expires (deletes) the lock.
Client B requests the lock. Redis says “Sure!”
Client B writes to the database.
Client A wakes up from GC. It thinks it still holds the lock. It writes to the database.
BOOM. Data corruption.
Two processes modified the resource simultaneously because the first one “slept” through its lock expiration. This proves a fundamental theorem of distributed systems: You cannot assume a process is dead just because it is silent. It might just be slow.
🔒 Subscribe to read the “Redlock” Controversy & Solutions
Redis is fast, but is it safe? The creator of Redis (Antirez) proposed an algorithm called Redlock to make this safer. But distributed systems expert Martin Kleppmann proved that Redlock is mathematically flawed for correctness.
In the rest of this deep dive, we will cover:
The Redlock Debate: Why running 5 Redis masters doesn’t solve the clock drift problem.
The Decision Framework: When is it actually okay to use Redis? (Hint: Efficiency vs. Correctness).
The Alternatives: A sneak peek at ZooKeeper, Etcd, and Postgres Advisory Locks.