

Ep #63: Microservices Madness: Why 90% of Startups Should Stick to a Monolith
You aren’t Netflix, and you don’t have Netflix’s problems. Stop paying the "Microservices Tax" before you have product-market fit.

Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Dec 2, 2025 · Free Post ·
The Seductive Lie
Picture this: You’re at a tech conference. A Netflix engineer is on stage, showing a dazzling diagram of 700+ microservices communicating through event streams, deploying independently 4,000 times a day. The audience is mesmerized.
You go back to your 5-person startup and think: “We should do that too.”
This is how startups die.
Not with a bang, but with a whimper—buried under mountains of YAML files, debugging distributed tracing issues at 2 AM, and burning runway on infrastructure instead of features.
In the last decade, our industry has been gripped by a collective delusion: that the architecture used by Netflix, Uber, and Amazon is the default correct choice for a team of five engineers building a CRUD app. We have conflated “good engineering” with “maximum complexity.”
Today, we are going to tear down the hype. We are going to look at the mathematical reality of distributed systems, the hidden costs of splitting your database, and why the boring, dusty Monolith is actually the high-performance race car your startup needs.
Here’s a quick TL;DR video summary of this article — perfect if you prefer watching instead of reading
The Fallacy of “Infinite Scale”
Why do engineers choose microservices on Day 1? Usually, the argument boils down to Scalability.
The logic goes like this:
If we split the application into small pieces, we can scale the heavy pieces independently. If the video processing service is heavy, we add more servers just for that, without touching the user profile service.
Theoretically, this is true. Practically, for 90% of startups, it is irrelevant.
Most startups fail not because their architecture couldn’t handle 10 million concurrent users. They fail because they couldn’t iterate fast enough to find Product-Market Fit (PMF). They fail because they ran out of money.
When you choose microservices early, you are optimizing for a problem you hope to have in three years (massive scale), while neglecting the problem you actually have today (velocity).
You are building a skyscraper foundation for a lemonade stand. And the concrete is expensive.
What Actually Happens: The Tale of Two Architectures
Let’s visualize the difference between what you think you’re building and what you actually get.
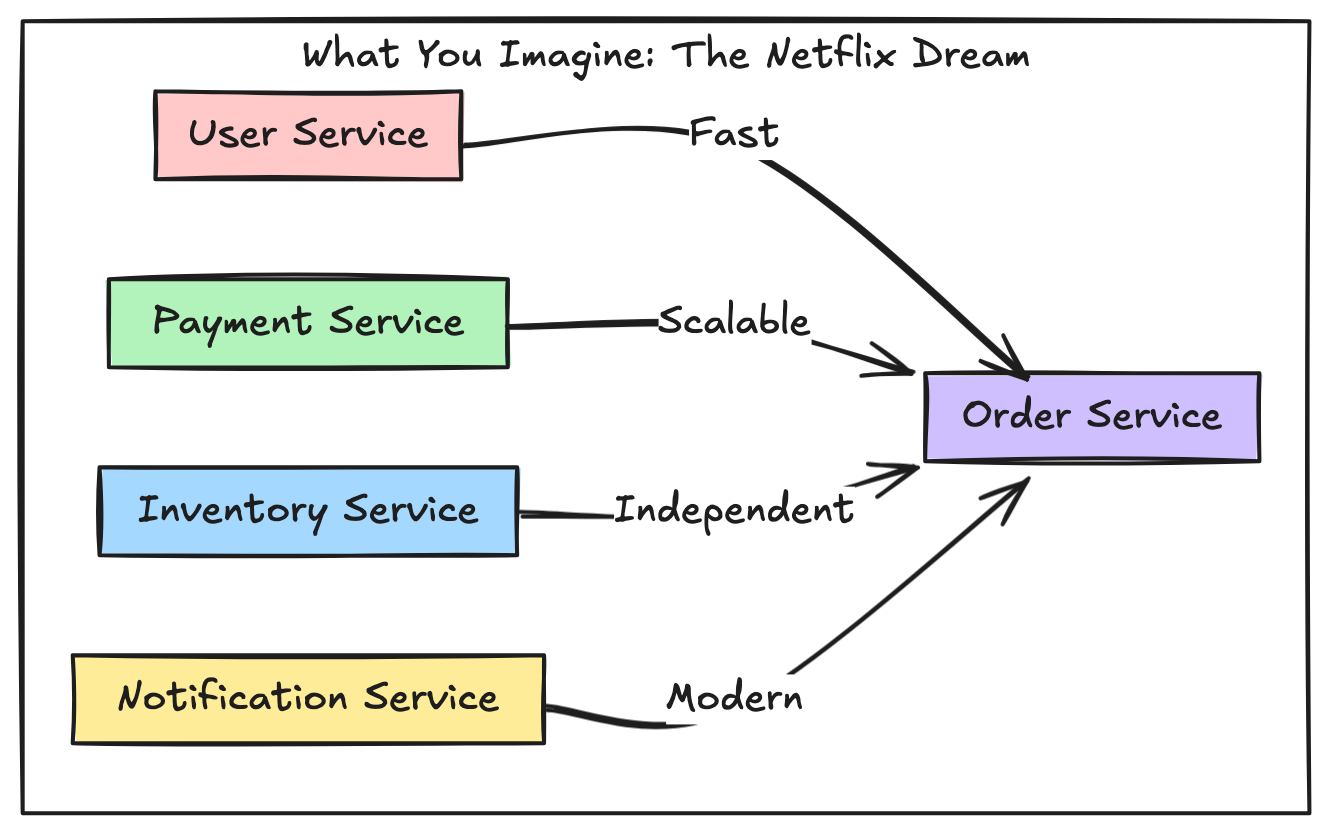
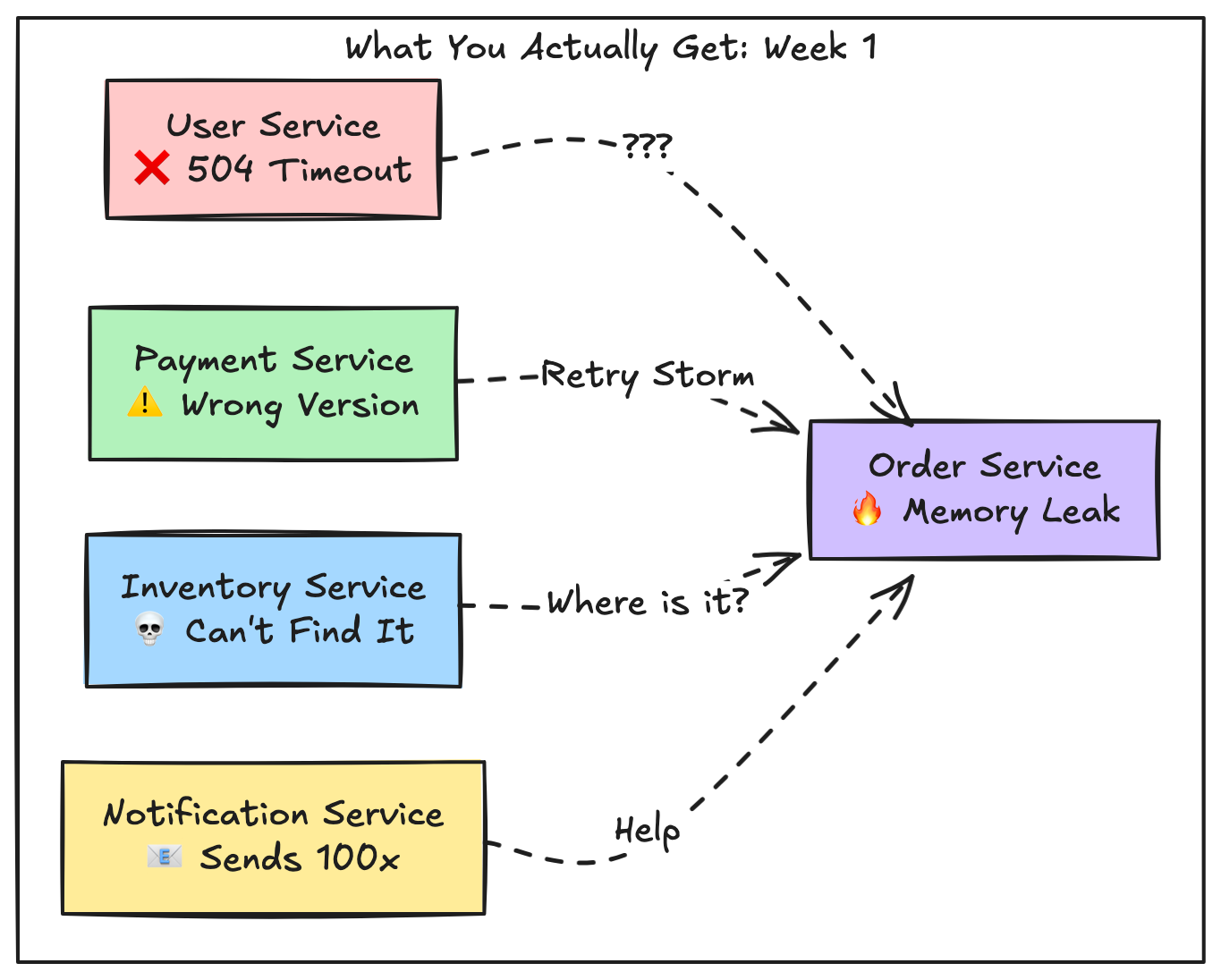
The Monolith vs Microservices: A Visual Reality Check
The Monolith (What 90% Should Build)
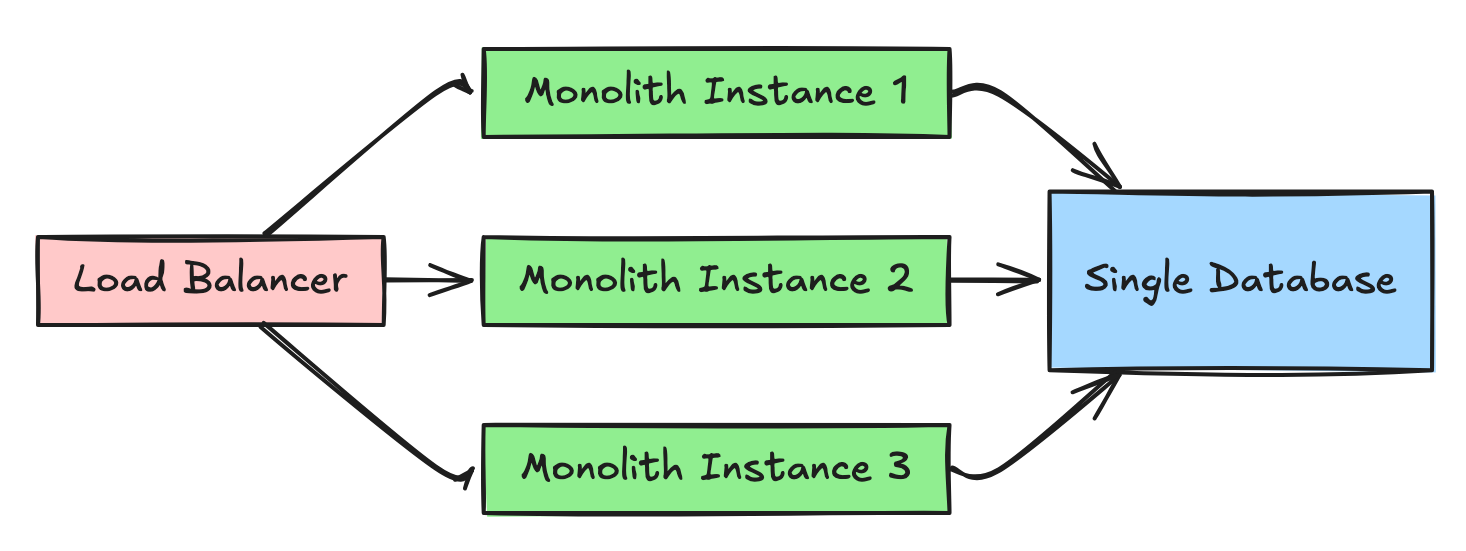
One Repository.
One Database.
One Deployment.
Multiple Instances.
The Microservices Chaos (What You Get Before PMF)
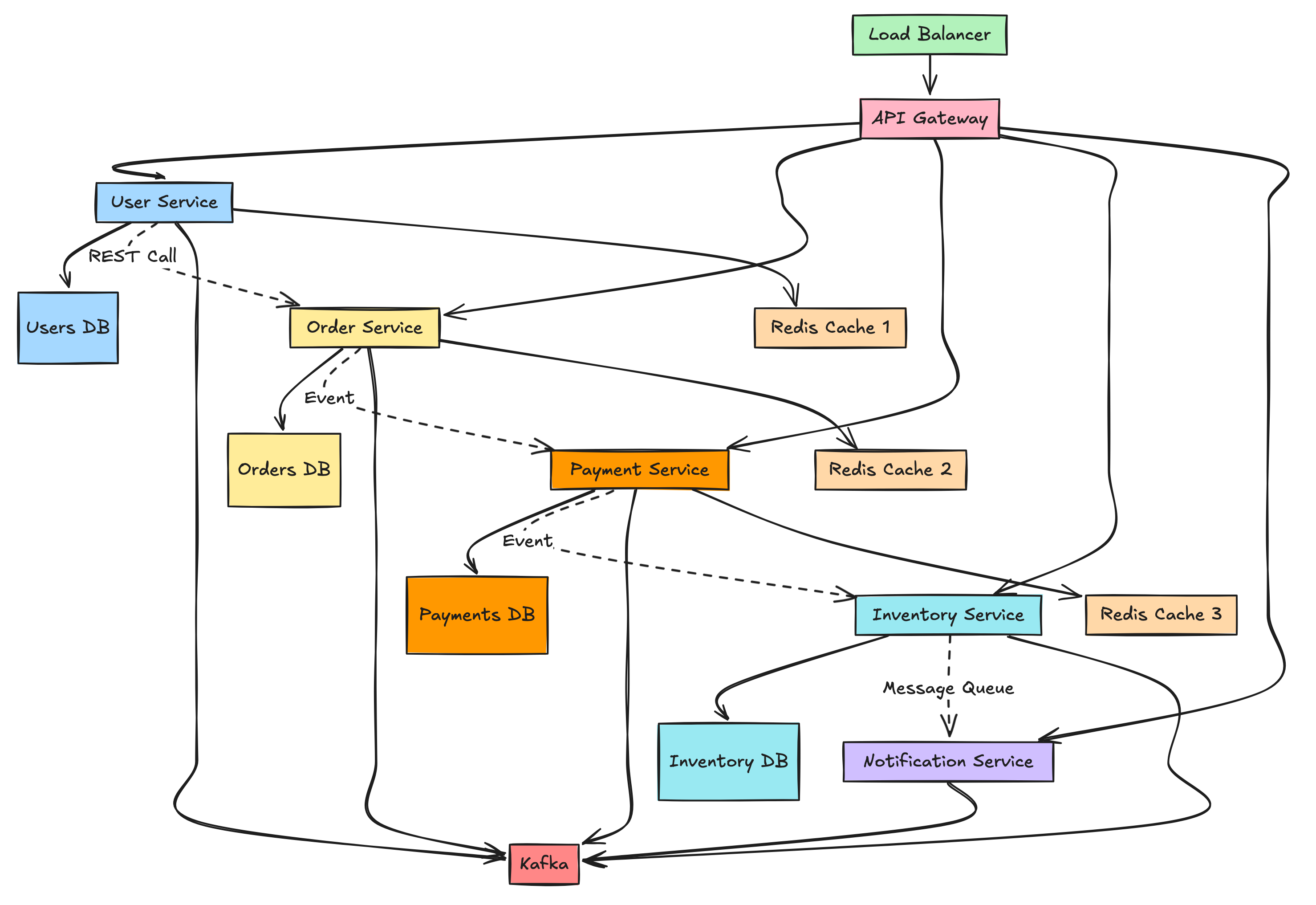
Five Repositories.
Four Databases.
Three Message Queues.
Two Caching Layers.
One Exhausted Developer.
Real World Evidence: When Giants Went Backward
Case Study 1: Segment (2020)
Segment was running 150+ microservices. Their engineering team was drowning.
Their Problems:
Dozens of HTTP calls to render a single page
Deployment took hours (coordinating multiple services)
3 engineers spent full-time just managing infrastructure
Debugging required jumping between 10+ repositories
Their Solution: They merged back into a monolith. Not because they were failing—they had raised $175M. Because it was the right engineering decision.
Results:
Page load times cut in half
Deployment time: 1 hour → 15 minutes
Developer productivity increased 40%
Infrastructure costs dropped 30%
Case Study 2: Amazon (The Original Example)
Everyone loves to cite Amazon as a microservices success story. But here’s what they don’t tell you:
Amazon was a successful $1B+ company BEFORE microservices.
They didn’t start with microservices. They:
Built a monolith (1994-2001)
Achieved product-market fit
Scaled to millions of customers
Then broke it apart when they had:
1000+ engineers
Clear service boundaries
Actual scaling problems
Money to burn on infrastructure
Starting with microservices would have killed Amazon.
Case Study 3: Stack Overflow
Stack Overflow serves 5,000 requests per second with a monolith and just 9 web servers.
That’s right. One of the world’s most popular developer websites runs on a monolithic architecture.
Why? Because:
They can understand the entire codebase
Deployments are simple
Performance is predictable
They spend time on features, not infrastructure
The “Microservices Tax”: What You Are Actually Paying
Microservices are not free. In fact, they are one of the most expensive architectural patterns you can choose. I call this the Microservices Tax. It comes in three currencies: Latency, Consistency, and Cognitive Load.
1. The Latency Tax (Network > Memory)
In a Monolith, communication happens in-memory. If OrderModule needs to check a user’s credit balance, it calls a function in UserModule.
Cost: Nanoseconds.
Reliability: 100% (unless the CPU catches fire).
In a Microservices architecture, OrderService must make an HTTP/gRPC call to UserService.
Cost: Milliseconds (Network I/O + Serialization + Deserialization).
Reliability: Variable. The network is flaky. The switch might be overloaded. The DNS might fail.
You have just replaced a function call (guaranteed to work) with a network request (guaranteed to eventually fail). This introduces the need for retries, circuit breakers, and timeouts. You aren’t writing business logic anymore; you are writing plumbing code to handle the fact that computers talk to each other over a wire.
2. The Consistency Tax (Goodbye, ACID)
This is the one that hurts the most.
In a Monolith with a single relational database (Postgres/MySQL), you have the God-tier superpower of ACID Transactions.
You want to create an order and deduct inventory? Easy.
SQL
BEGIN TRANSACTION;
INSERT INTO orders (user_id, item_id) VALUES (1, 50);
UPDATE inventory SET count = count - 1 WHERE item_id = 50;
COMMIT;If the power goes out after line 2, the database rolls back. The order never happened. The data is pristine.
In Microservices, you (usually) follow the Database-Per-Service pattern. The Order Service has order_db, and the Inventory Service has inventory_db. You cannot run a transaction across two different database servers.
Now, to perform that same operation, you need:
Distributed Transactions: (Two-Phase Commit), which lock resources and kill performance.
Sagas: A complex pattern of events and “compensating transactions.” If the inventory deduction fails, you have to trigger an “undo” event to delete the order.
You have just turned a 4-line SQL transaction into a week of engineering work involving Kafka, event consumers, and eventual consistency bugs.
3. Cognitive Load
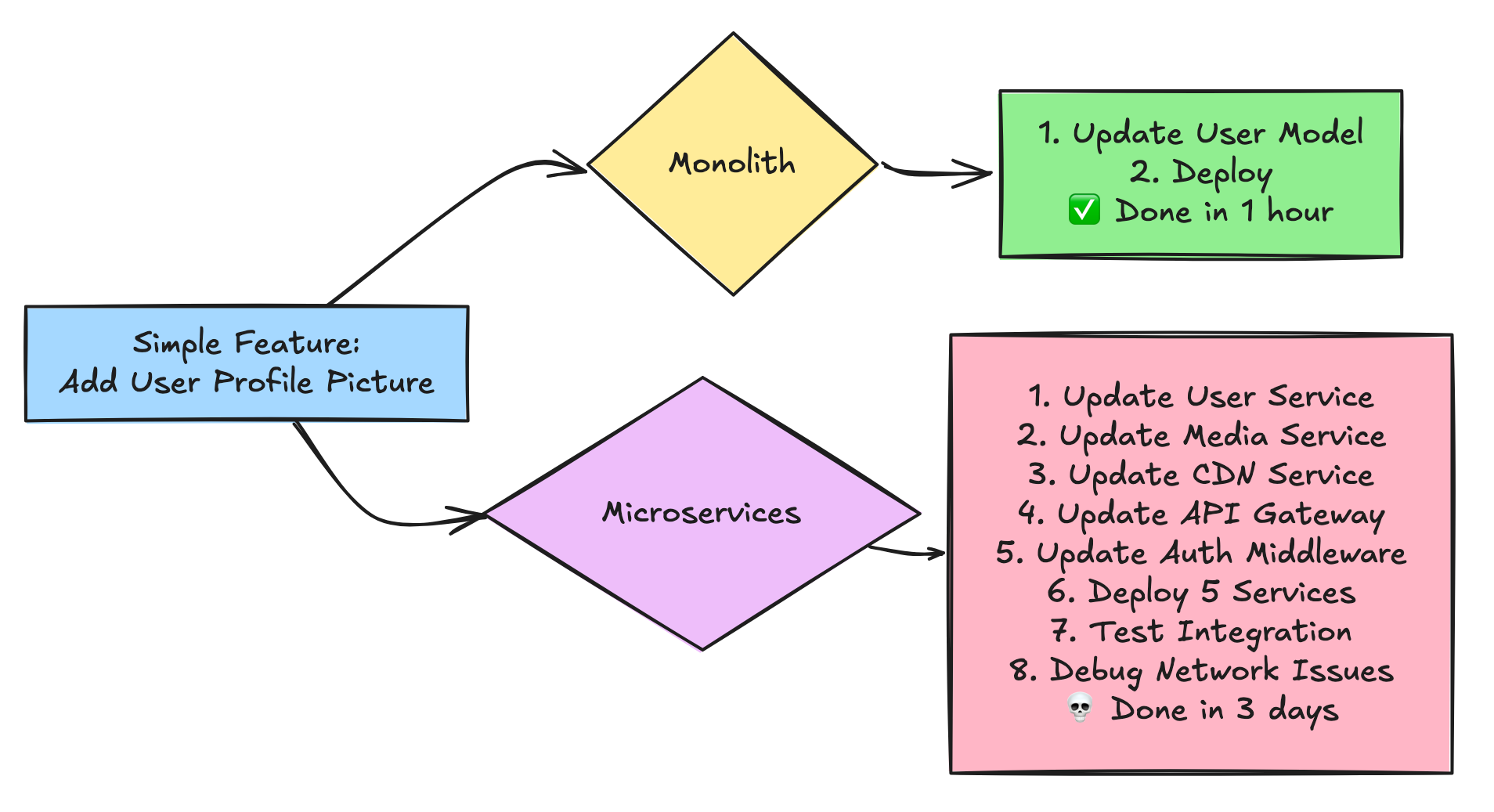
In a monolith: Change one file, deploy, done.
In microservices: Change four services, update three API contracts, fix two integration tests, debug one network timeout, cry once.
4. The DevOps Tax (Infrastructure Complexity)
A Monolith needs a Load Balancer and an App Server.
Microservices need:
A Container Orchestrator (Kubernetes).
A Service Mesh (Istio/Linkerd) for service-to-service mTLS and observability.
A Service Discovery mechanism.
Centralized Logging (ELK/Splunk) because you can’t
tail -flogs across 50 containers.Distributed Tracing (Jaeger/Honeycomb) because you have no idea where the error originated.

Suddenly, your “Full Stack Developer” needs to be a Kubernetes expert just to deploy a typo fix.
5. Operational Nightmare
Imagine you have a bug. A customer can’t complete checkout.
In a Monolith:
1. Check logs (/var/log/app.log)
2. Find error in checkout.py line 47
3. Fix bug
4. Deploy
5. Total time: 20 minutesIn Microservices:
1. Which service is failing?
- Check API Gateway logs
- Check distributed tracing (Jaeger)
- Find it’s the Payment Service
2. But Payment Service logs look fine?
- Oh, it’s calling Inventory Service
- Check Inventory Service logs
- Inventory looks fine too?
3. Network issue?
- Check service mesh (Istio)
- Check DNS resolution
- Check Kubernetes pod health
4. Found it! Circuit breaker is tripping
- But why?
- Check Kafka messages
- Found duplicate messages
5. Fix requires changes to 3 services
6. Deploy them in the right order
7. Hope you didn’t create new race conditions
8. Total time: 4 hours, 2 developers, 1 nervous breakdownSummary
If you are a startup, your bottleneck is not “merge conflicts.” Your bottleneck is “building features people want.” Microservices slow that down.
So, if we don’t use Microservices, do we just write spaghetti code in one big file?
No. The answer is the Modular Monolith.
In this Friday’s Paid Deep Dive, we are going to cover:
The Modular Monolith: How to structure your code to get the benefits of microservices without the pain.
The Folder Structure: Exact layouts for Python/Node to enforce boundaries.
The Code: A breakdown of how to implement this pattern using FastAPI.
The Breaking Point: A checklist of when you actually need to switch to microservices.
See you on Friday.