

Ep #53: The Amazon DynamoDB Outage (Oct 19–20, 2025): What Went Wrong and What We Can Learn
How a Small Race Condition Led to a Big AWS Outage — Lessons from DynamoDB’s October 2025 Failure

Breaking the complex System Design Components
By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Oct 28, 2025 · Free Post ·
On October 19 and 20, 2025, one of the world’s most reliable cloud infrastructures — Amazon Web Services (AWS) — faced a major disruption in its Northern Virginia (us-east-1) region. The root cause started with Amazon DynamoDB, but it quickly cascaded across many AWS services, including EC2, Lambda, and Network Load Balancer (NLB).
For companies running on AWS, this incident was a reminder that even the most resilient systems can fail — and that understanding the why behind such failures helps us design better ones in the future.
Before we start with today’s post —
Over time, while writing The Architect’s Notebook, I realized there’s another kind of architecture we often overlook — the one inside our own minds.
That realization led to my new publication, The Mind’s Blueprint — a space where I write about awareness, simplicity, and the architecture of the inner world.
It’s not about escaping reality, but about seeing it with more clarity and peace.
If The Architect’s Notebook helps you build better systems, The Mind’s Blueprint will help you understand the mind that builds them.
✨ Subscribe to The Mind’s Blueprint and walk with me on this journey of unblocking the mind.
Let’s break it down simply: what happened, what caused it, how AWS fixed it, and what lessons we can learn as engineers and architects.
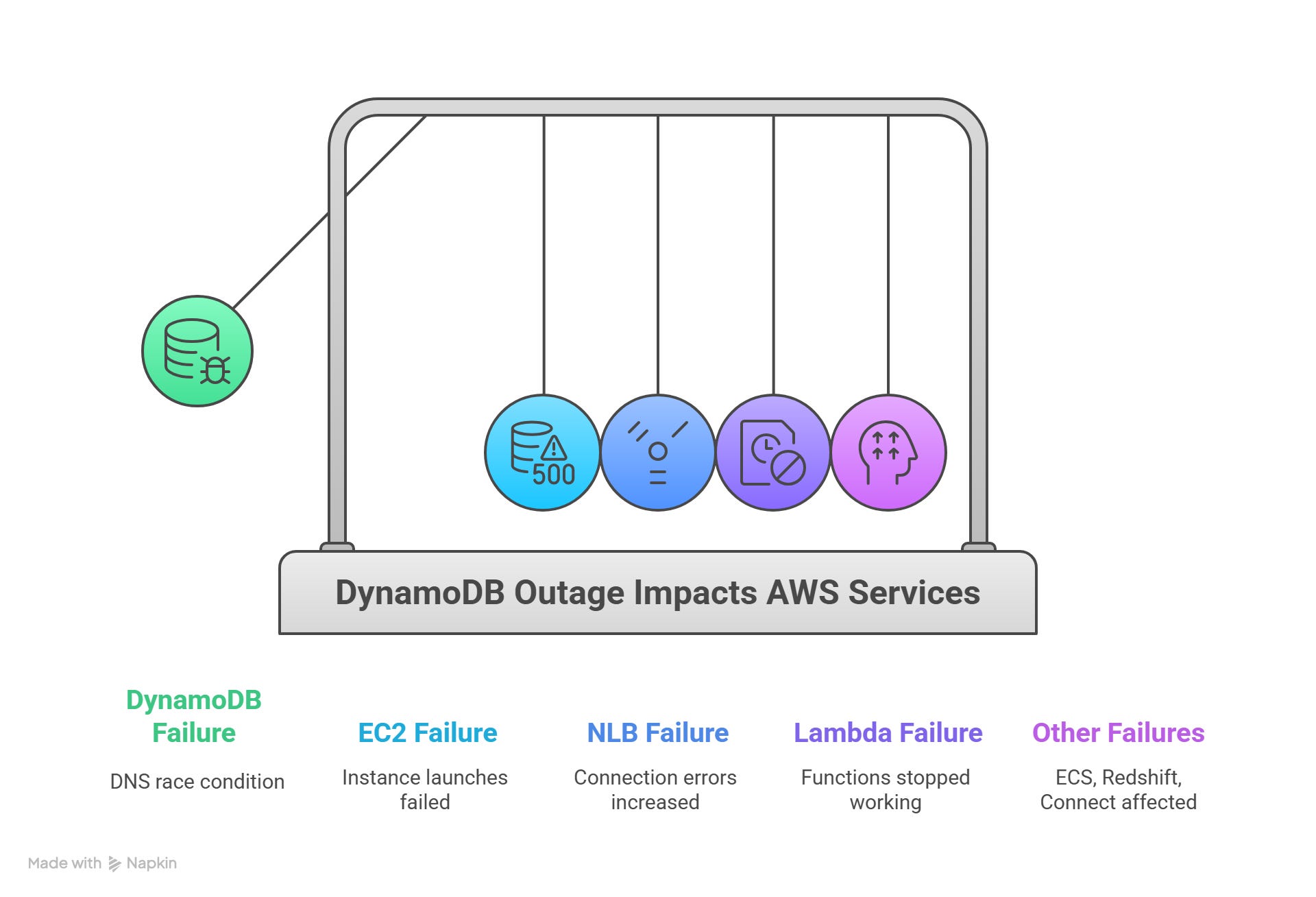
What Happened
The incident began around 11:48 PM PDT on October 19, when Amazon DynamoDB — AWS’s fully managed NoSQL database — started returning API errors in the us-east-1 region.
Because DynamoDB is a core dependency for dozens of AWS services (like EC2 instance management, Lambda, Redshift, and IAM), this single failure rippled through the ecosystem.
In short:
Customers couldn’t connect to DynamoDB in that region.
EC2 instance launches failed.
Lambda functions stopped working.
Load balancers (NLBs) started showing connection errors.
Other AWS services like ECS, Redshift, and Connect were affected too.
It took AWS engineers nearly 15 hours to fully restore all services.
Here’s a quick TL;DR video summary of this article — perfect if you prefer watching instead of reading
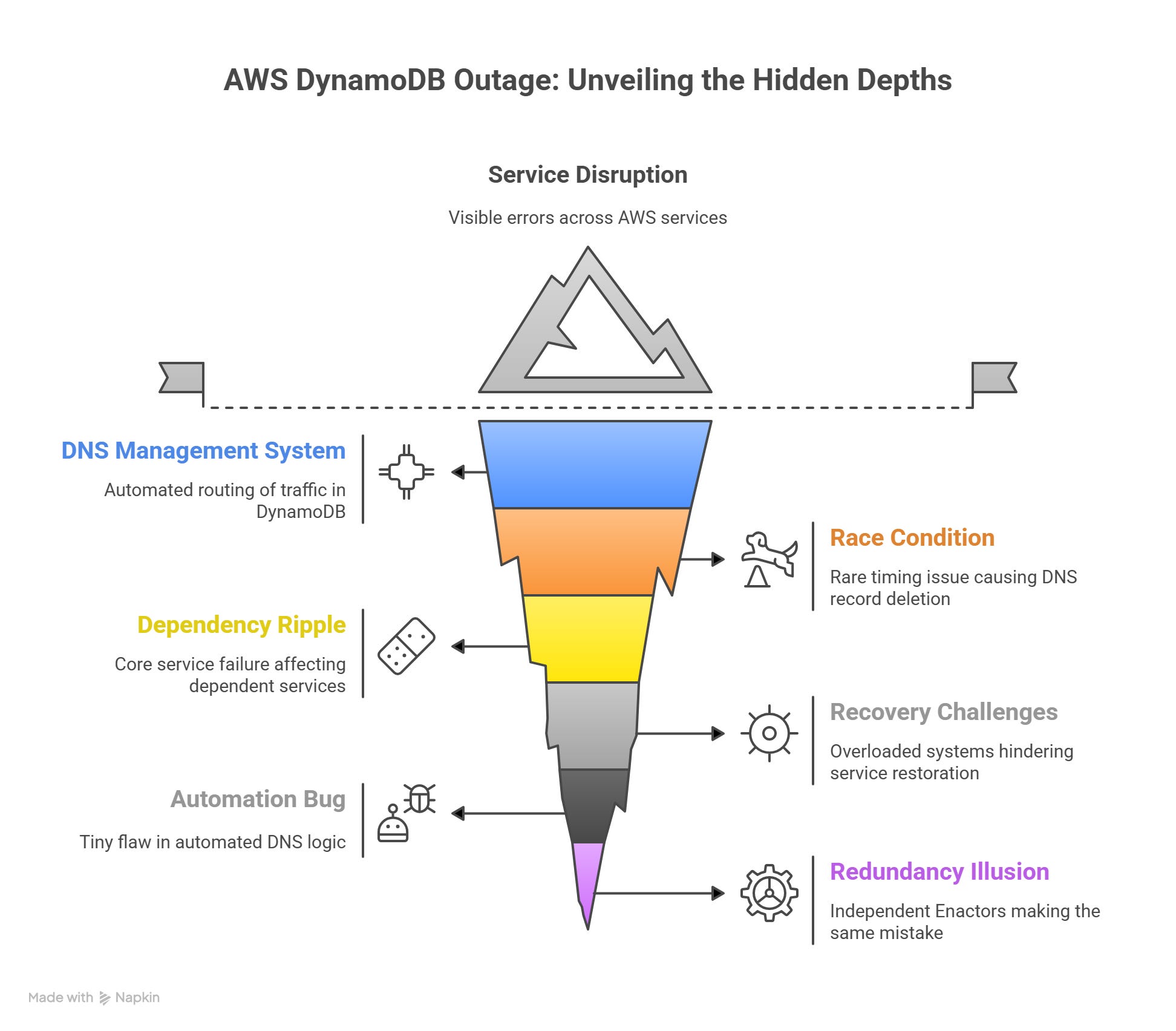
Root Cause — A Subtle Race Condition
The outage was caused by something deep in DynamoDB’s DNS management system — the mechanism that ensures users’ requests reach healthy servers.
To handle millions of requests, DynamoDB uses automated DNS management to route traffic efficiently. Two key components are involved:
DNS Planner: Decides which servers should handle which requests.
DNS Enactor: Applies those plans by updating Amazon Route 53 (AWS’s DNS service).
For redundancy, there are three DNS Enactors, each operating independently. Normally, this design ensures that even if one fails, others continue smoothly.
But on this day, a rare race condition occurred:
One Enactor was slow in updating DNS records.
Another Enactor, working faster, applied a new plan and then cleaned up older ones.
The slower Enactor finally caught up — but applied an old plan right after the cleanup.
That “old” plan deleted the active DNS records for DynamoDB’s regional endpoint.
As a result, the DNS record for dynamodb.us-east-1.amazonaws.com became empty — meaning no one (including AWS’s own systems) could find where DynamoDB lived.
This small race condition brought down one of the most critical services in AWS’s global network.
Impact Across AWS Services
When a core service like DynamoDB fails, the domino effect is massive. Let’s look at how it spread:
1. DynamoDB
All connections in us-east-1 failed between 11:48 PM and 2:40 AM PDT.
Systems relying on DNS couldn’t reach the database.
Recovery required manual intervention from AWS engineers.
2. EC2 (Virtual Machines)
EC2 depends on DynamoDB to manage physical servers (“droplets”) through an internal system called DropletWorkflow Manager (DWFM).
When DynamoDB went down, DWFM couldn’t renew “leases” with these servers, so it treated them as unavailable.
This led to “insufficient capacity” errors for new EC2 launches.
Even after DynamoDB recovered, EC2 took several more hours to catch up and re-establish network states.
Full recovery was achieved around 1:50 PM PDT.
Example: Imagine trying to rent a car from a company’s system that suddenly loses its database connection. Even though cars exist, the system thinks there’s no availability — that’s what EC2 experienced.
3. Network Load Balancer (NLB)
NLB began failing health checks because new EC2 instances had incomplete network setups.
It started removing healthy nodes from rotation, thinking they were faulty.
This led to random connection failures across apps using NLB.
Engineers disabled automatic failover at 9:36 AM, restoring stability.
4. Other Services
Lambda functions failed to invoke or scale properly.
ECS, EKS, and Fargate couldn’t launch new containers.
Amazon Connect (contact center service) experienced dropped calls and chat failures.
Redshift queries and cluster operations failed due to IAM and EC2 dependencies.
IAM and STS login operations failed temporarily, preventing console sign-ins.
By 2:20 PM PDT on October 20, all AWS services in us-east-1 were back to normal.
How AWS Fixed It
Once engineers identified that the DynamoDB DNS record had been wiped, they manually restored it.
Timeline of key fixes:
12:38 AM: Issue traced to DynamoDB DNS management.
1:15 AM: Temporary fixes applied to restore some internal connections.
2:25 AM: DNS fully restored.
Morning: EC2, NLB, and other dependent services began sequential recoveries.
Afternoon: Full recovery achieved across all AWS services.
AWS engineers also had to carefully restart internal systems like DWFM and Network Manager, which were overloaded by backlogged tasks once DynamoDB came back online.
Lessons Learned
This outage highlights some timeless engineering truths that apply far beyond AWS.
1. Automation Is Powerful — but Needs Guardrails
Automation keeps large systems running smoothly, but as AWS saw, a tiny bug in automated DNS logic can bring an entire region down.
Lesson: Always design automation with multiple safety checks and rollback paths.
2. Redundancy Isn’t the Same as Immunity
Having three independent DNS Enactors didn’t prevent the failure because they weren’t fully isolated from making the same mistake.
Lesson: True resilience comes not just from redundancy, but from independent failure domains that can’t all make the same error.
3. Dependencies Can Multiply the Blast Radius
DynamoDB was only one service — but EC2, Lambda, Redshift, and dozens of others depend on it indirectly.
Lesson: Map your system dependencies clearly. The failure of one core service can ripple through everything if dependencies aren’t well-isolated.
4. Recovery Can Be Harder Than Failure
Once the root issue was fixed, AWS still spent hours bringing EC2 and NLB back because of backlog congestion.
Lesson: Design your recovery workflows to handle large-scale restarts gracefully. “Self-healing” is only useful if the system can catch up efficiently.
5. Communication and Transparency Matter
AWS published a detailed postmortem explaining what happened and what steps they’re taking to prevent it again.
Lesson: When things fail, owning the narrative builds trust. Whether you’re AWS or a startup, honesty after failure is a strength.
You can read the full report here.
What AWS Is Changing Going Forward
AWS has already taken several actions to prevent a repeat:
Disabled the DynamoDB DNS automation globally until fixed.
Adding protections against race conditions in DNS updates.
Introducing velocity control in NLB to prevent large-scale failovers.
Building new EC2 recovery test suites to simulate large-scale lease reestablishments.
Improving throttling logic in EC2 systems to manage queue overloads.
These steps show AWS’s deep engineering culture — learning fast, fixing root causes, and strengthening systems.
Final Thoughts
Even the best-engineered systems fail. What matters most is how quickly you detect, communicate, and recover.
AWS’s DynamoDB outage was a rare and complex event caused by a subtle race condition — a reminder that no automation is infallible. Yet it also showed the power of resilience: multiple teams coordinating across thousands of servers, recovering step by step.
For those of us building distributed systems, the takeaway is clear —
Resilience is not built in the easy times; it’s built in how we handle failures.
If you found this breakdown useful, consider subscribing for more real-world system architecture analyses, design failures, and lessons from large-scale engineering.
My wife, Karen, says it reconfirms everything her teachers taught her: anything that can go wrong will and if more than one thing can go wrong, the worst possible combination thereof will occur, document everything and keep your documentation up to date, test test test, when you make a mistake own it because it's about accountability not blame.