

Ep #116: Zero-Downtime Data Architecture (Part 2): The Expand and Contract Pattern
How to rename a database column on a 500-million-row table without dropping a single HTTP request.

By Amit Raghuvanshi | The Architect’s Notebook
🗓️ Jun 11, 2026 · Deep Dive ·
The Anatomy of a Safe Migration
In Part 1, we learned that because of Kubernetes rolling deployments, your database schema must support the old code (v1) and the new code (v2) simultaneously.
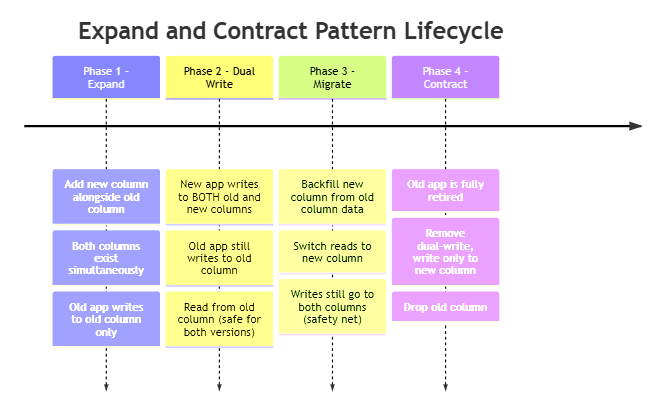
To achieve this, we use the most critical pattern in Zero-Downtime Data Architecture: The Expand and Contract Pattern (also known as Parallel Change or Branch by Abstraction). Master this, and you have solved 80% of your schema migration problems.
It is a multi-phase approach that ensures:
The database always has a schema compatible with both old and new app versions.
Data is never lost or corrupted during the migration.
Each phase can be performed independently and rolled back if needed.
It was popularized by Martin Fowler and has become the gold standard for zero-downtime database evolution.
The 4-Phase Lifecycle: A Walkthrough
Let’s use a real-world scenario.
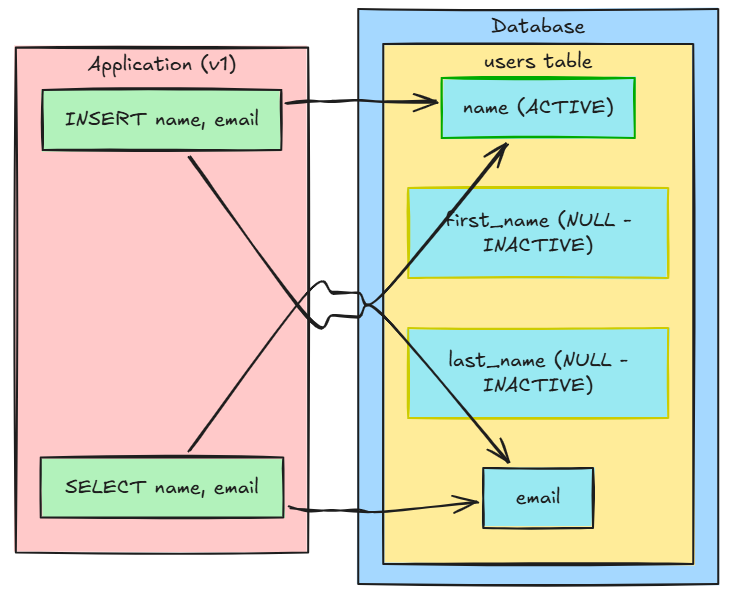
Scenario: You have a users table with a name column (VARCHAR 100). The business wants to split this into first_name and last_name for better data quality and personalization. The table has 200 million rows.
Current schema:
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP
);Target schema:
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP
);If you run a migration that drops name and adds first_name/last_name simultaneously, you cause an immediate outage. Here's how to do it safely.
Phase 1: EXPAND — Add New Columns (Non-Breaking)
Goal: Add the new columns without removing the old one. The new columns must be nullable or have a default value so that existing application code (which doesn't know about the new columns) can still insert rows without errors.
-- Phase 1 Migration: Safe to run on live production
-- In MySQL 8+ with InnoDB, adding a nullable column is an online operation
-- (metadata-only change, no table rebuild required)
ALTER TABLE users
ADD COLUMN first_name VARCHAR(100) NULL,
ADD COLUMN last_name VARCHAR(100) NULL;Why NULL and not NOT NULL? Because the old application code doesn't write to
first_nameorlast_name. If you made them NOT NULL without a default, every INSERT from the old application would fail with a constraint violation.
State after Phase 1: The schema is expanded. The v1 application code is completely untouched. It continues to read and write to the name column happily. The new columns sit empty.

🔒 Subscribe to read Phases 2, 3, and 4 (Dual-Writes & Backfills)
We have expanded the schema. Now comes the hard part. How do we teach the application to write to the new columns without breaking the old ones? And how do we move 200 million existing names into the new columns without locking the database?
In the rest of this deep dive, we will cover:
Phase 2 (Dual Write): How to structure your Repository layer to write to both schemas safely.
Phase 3 (Migrate): How to write a throttled, batched backfill job in C# that won’t melt your database CPU.
Phase 4 (Contract): The safety checklist you must clear before you drop the old column.